1. Introduction
This document is essential reading for anyone who is using or is planning to use the Techila Distributed Computing Engine (TDCE), the interactive big compute solution. This document provides an overview of the technology used in the TDCE solution, and introduces the fundamental concepts and features.
This document is organized as follows:
Distributed Computing introduces the terminology related to distributed computing. The main focus is to define terminology of distributed computing, which will be used throughout this document and in other Techila Distributed Computing Engine documentation.
Fundamentals introduces the key concepts of the Techila Distributed Computing Engine solution. This chapter also defines essential terminology, which will be used throughout this document and in other TDCE documents. The terminology includes terms such as "Projects", "Jobs" and "Bundles", which are related to the process flow that occurs when a computational workload is executed in a TDCE environment. This chapter introduces also the concepts of integrating distributed computing to an existing application using TDCE, and the essential features of the TDCE API.
Features introduces some of the most commonly used optional features available in Projects created with peach or cloudfor-functions. These include features such as Snapshotting (saving intermediate results that can be used to resume computations) and Streaming (downloading individual Job result files as soon as they are available). The purpose of this Chapter is to provide an overview of the available features that can improve the performance of your application when using Techila Distributed Computing Engine.
Advanced Features introduces some of the more advanced features available in the Techila Distributed Computing Engine system. Some of the most noteworthy features are the Techila interconnect feature, which allows processing parallel workloads in the Techila Distributed Computing Engine environment and the Techila Distributed Computing Engine AD impersonation feature, which can allow computational processes to access data resources requiring AD authentication.
Distributing Computations with the Java API introduces how you can distribute computations by using the Java-based Techila Distributed Computing Engine Interface Methods. These methods will allow you to have even more control regarding the distribution process, but with the risk of added code complexity.
Application Highlights highlights some of the more advanced applications of Techila Distributed Computing Engine technology to speed up computations.
2. Distributed Computing
The terminology related to distributed computing can be quite confusing and can seem to be overlapping or inconsistent. In order to clarify what the Techila system is, this chapter will define distributed computing terminology used in this document and in other Techila Technologies' documentation.
2.1. Distributed Computing Problems
Computational problems can be divided in to two main categories; parallel problems and embarrassingly parallel problems. The difference between these two problem types is in the amount of communication between individual Jobs.
Parallel problems are problems where the computations performed in one Job affect the computations in another Job. This means in order to solve the computational problem, Jobs will need to be are able to communicate and pass information between Jobs. An illustration of a parallel problem is shown below. Typical parallel problems include for example computations dealing with fluid dynamics or finite element models.
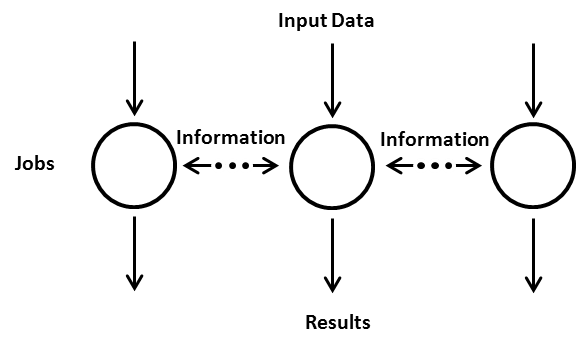
Embarrassingly parallel problems are problems, where the computational Jobs are independent. This means that each Job can be solved independently, without communication between Jobs. Because of this, individual Jobs can also be completed in any order, without any communicating with other Jobs. This process flow is shown below. Embarrassingly parallel computations include for example Monte Carlo methods, computer graphics rendering, genetic algorithms, brute force methods and BLAST searches.
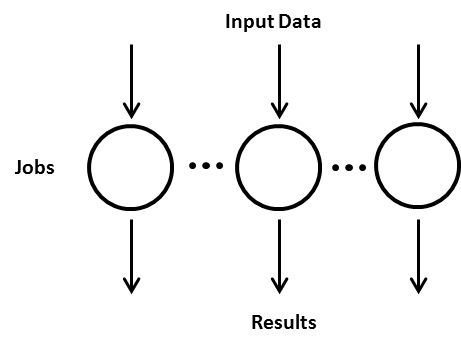
2.2. Distributed Computing Models
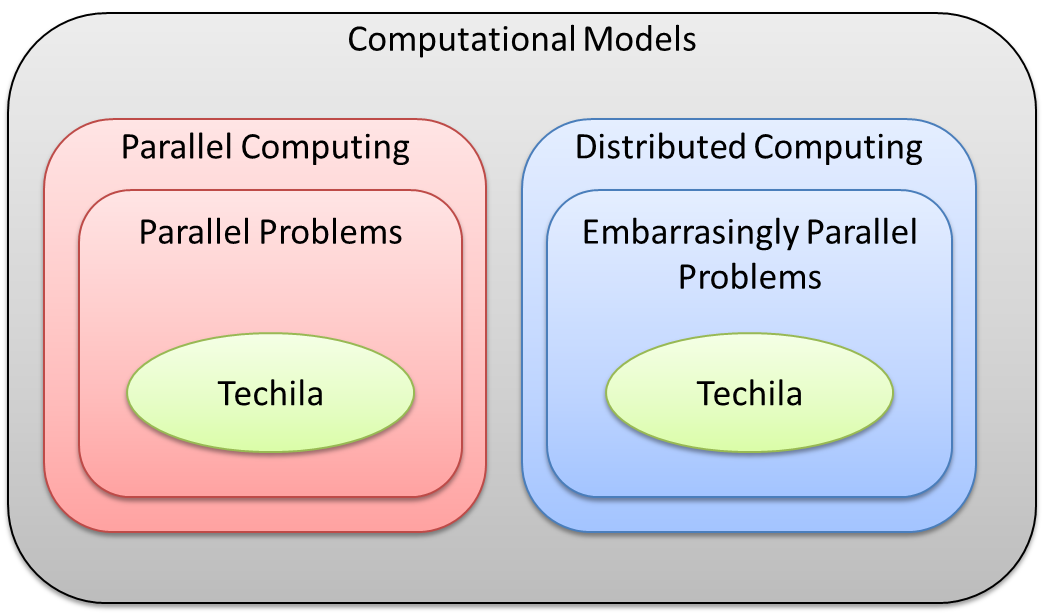
Generally speaking, all distributed computing models are based on the same fundamental idea. A large, time consuming computational problem is divided into smaller pieces, which then can be solved simultaneously using a group of computers. Depending on the computational problem, the Jobs can be either independent or require communication with each other. Based on the amount of inter-process communication, two models can be highlighted: parallel computing and distributed computing.
Parallel computing is used to solve parallel problems. Parallel computing environments provide mechanisms that can be used to handle inter-process communication. Parallel computing environments are usually found in computing clusters or dedicated cloud computing environments. Parallel computations can also be performed in a Techila Distributed Computing Engine environment by using the Techila interconnect feature.
Distributed computing is used to solve embarrassingly parallel problems. Distributed computing environments are often more loosely coupled than parallel computing environments. They can contain a wide variety of different types of computers running different operating systems. This is different from a parallel computing environment, where both the hardware and the software are often quite homogeneous.
The Techila Distributed Computing Engine system is a distributed computing solution, designed for solving both parallel problems and embarrassingly parallel problems. This is illustrated below.
2.3. Techila Distributed Computing Engine System
Techila Distributed Computing Engine is a distributed computing solution that utilizes existing computational resources to solve demanding computational Projects. Techila Distributed Computing Engine supports use of heterogeneous hardware and operating system platforms. The computational resources can be personal workstations, laptops, nodes belonging to a computing cluster or compute instances from cloud providers.
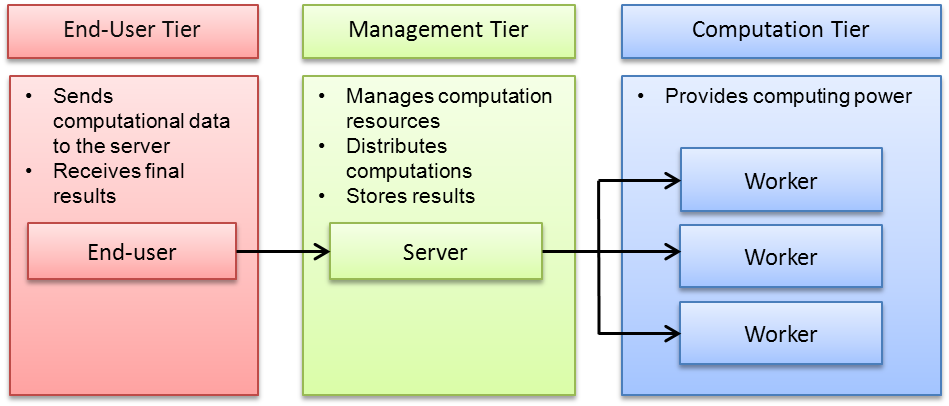
Efficient distribution of computations requires efficient resource management. Resource management in a Techila Distributed Computing Engine environment is done by the Techila Server. The Techila Server is responsible for distributing the computations to Techila Workers and monitoring the state of the Techila Workers. The Techila Server also acts as communication endpoint between the End-User’s computer and the Techila Distributed Computing Engine environment, providing the End-User access to the environment when they are using the Techila SDK to create computational Projects. This forms a three-tiered structure, each tier performing a specific role in the computing environment. This structure is illustrated below.
The Computation Tier consists of individual computers providing computational power in a Techila Distributed Computing Engine system. Each of these computers, be it a laptop or a cluster node, is called a Techila Worker.
3. Fundamentals
This Chapter contains important information on the fundamental operating principle of the Techila Distributed Computing Engine system and introduces some of the terminology that will be used frequently later on in the documentation.
3.1. Terminology
This Chapter describes the terminology associated with Techila Distributed Computing Engine and contains an overview of the process flow during a computational Project. A more detailed description on the process flow of a single computational Job is also provided.
3.1.1. Projects and Jobs

A Project is a computational problem created by an End-User. It acts as container for all Jobs in the Project and provides a handle in the form of a Project Identification (PID) number. The PID number can be used to monitor and control the computation process. A Project is divided into Jobs on the Techila Server according to the parameters specified by the End-User. Projects can be given Project parameters that control the distribution process. Project parameters can be used for example to specify requirements regarding the hardware properties that must be met by the Techila Worker before it can participate in the computations.
A Job is the smallest unit in a computational Project. Projects consist of either embarrassingly parallel problems, where Jobs are independent, or parallel problems, where Jobs communicate with other Jobs. The Techila Server assigns Jobs to available Techila Workers, where they will be executed. By default, a single Job is assigned to a single core on a Techila Workers Central Processing Unit (CPU).
A Techila Worker creates a temporary working directory for each Job. This directory is used to store the binaries, data files and other relevant information linked to the Job. The Techila Worker will then execute the executable code with the input arguments defined for the Job. Typically each Job will have a different set of input arguments. Techila Workers will transfer partial results generated by the Jobs to the Techila Server. These partial results can be streamed to the End-User as soon as they arrive to the Techila Server or they can be aggregated on the Techila Server. Aggregated results are transferred in a single package to the End-User when all of the Job results have been transferred to the Techila Server.
When a Project is created, the Project will also be assigned a Project priority value. Available values for the Project priority are shown in the table below:
| Numerical value | String value |
|---|---|
1 |
highest |
2 |
high |
3 |
above_normal |
4 |
normal |
5 |
below_normal |
6 |
low |
7 |
lowest |
By default, all Projects will be given the priority value 4 (normal).
The Project priority values will affect the order in which Projects created by you will be computed. For example, if you create a Project with a priority value 1 and a Project with priority value 4, Jobs belonging to the Project with priority value 1 will be assigned to Techila Workers before assigning any Jobs belonging to the other Project. Please note that if your Techila Server has been configured to allow parallel scheduling of multiple Projects from the same End-User, differences in Project priority values will only have a small effect in the order in which Jobs are assigned from different Projects. Please also note that Jobs belonging to a Project with the priority value 7 (lowest) will be removed from a Techila Worker if a Project with the priority 4 (or better) is waiting for computational resources on that Techila Worker to become available.
3.1.2. Bundles
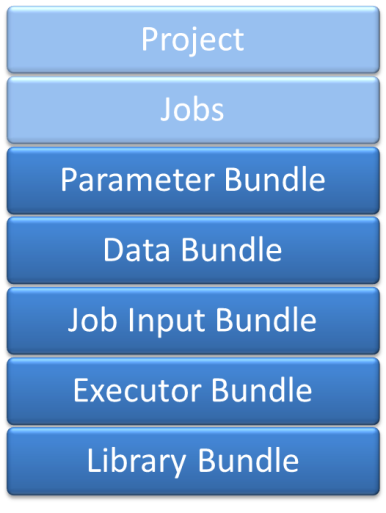
Techila Projects use Bundles to store and transfer computational data required on each Techila Worker. This data includes input parameters, data files and executable binaries. Technically speaking, Bundles are Java Archives (JAR) which are used to store the compressed computational data. Computational data is stored in different Bundle types, depending on its role in the computations. Bundles are created on the End-User’s computer and transferred to the Techila Server, which transfers required Bundles to Techila Workers.
Parameter Bundle is used to transfer parameters with when the peach-function is used. The Bundle contains the input parameters that will be used when computing the Project. The parameters usually include input arguments required by the Techila Worker Code. When the peach-function is not used, parameters are transferred as Project parameters.
Data Bundle contains common input data, which is used in one or several Projects. Input data stored in a Data Bundle is available for all Techila Workers participating in the Project. A Project can also contain several Data Bundles. The Data Bundle is an optional Bundle.
Job Input Bundle is used in transferring individual Job Input Files to Techila Workers. The Job Input Bundle is different from other Bundles, as individual files from the Bundle are transferred to Techila Workers directly from the Server. The Job Input Bundle is an optional Bundle.
Executor Bundle contains executable code or binaries that will get transferred and executed on Techila Workers. The contents of the Executor Bundle can also include interpretable computational code, which will get interpreted by a Library Bundle. An Executor Bundle is required in all Projects.
Library Bundle contains common Executor Bundle prerequisites used by several Projects. These include but are not limited to runtime libraries, language interpreters and mathematical libraries. Techila Workers automatically download Library Bundles from the Techila Server that are required by the Executor Bundle. Library Bundles are stored on the Techila Workers after a Project has been completed. This makes them locally available for future usage, enhancing the efficiency of future Projects. Library Bundles are usually created by a Techila Administrator,
Bundle parameters can be used to control the behavior of Bundles. For example, Bundle parameters can be used to control how long a Bundle should be stored on a Techila Worker.
Each Bundle includes a Manifest File containing information about the contents of a Bundle and dependencies to other Bundles. This information is included in lists containing Bundle imports and exports. Because of this, the Manifest File can be seen as a checklist, which ensures that all computational components are available on the Techila Worker before starting the computation. When using the peach-function, Bundle export and import lists will get created automatically. More information on Bundles can be found in Bundle Guide.
3.1.3. Process flow during a computational Project
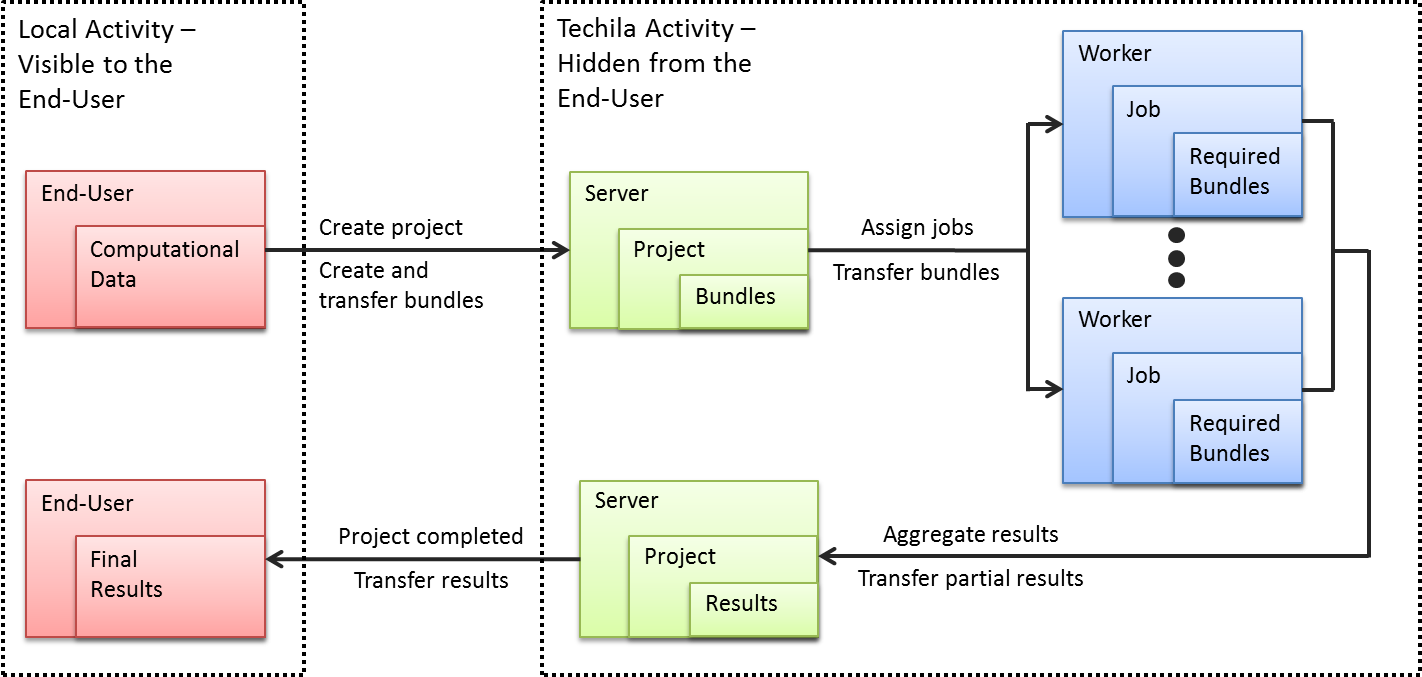
A computational Project starts when an End-User creates a Project by using one of the available Techila Distributed Computing Engine API functions, such as the peach-function. The computational data required in the computations is stored in Bundles and will get transferred to the Techila Server.
The Techila Server will split the Project into Jobs and will assign them to available Techila Workers. When a Job is assigned to a Techila Worker, the Techila Worker will request necessary Bundles from the Techila Server. The Server will then deliver the requested Bundles to the Techila Worker.
As soon as all required Bundles have been delivered to the Techila Worker, the Techila Worker will be able to start processing the computational Job. Partial results generated from Jobs will be transferred to the Techila Server, where the partial results are spooled. Results will either get transferred back to the End-User after all the Jobs have been completed or results of individual Jobs can be streamed to the End-User as soon as they are available on the Server. The process flow during a computational Project where partial results are aggregated on the Techila Server is illustrated below.
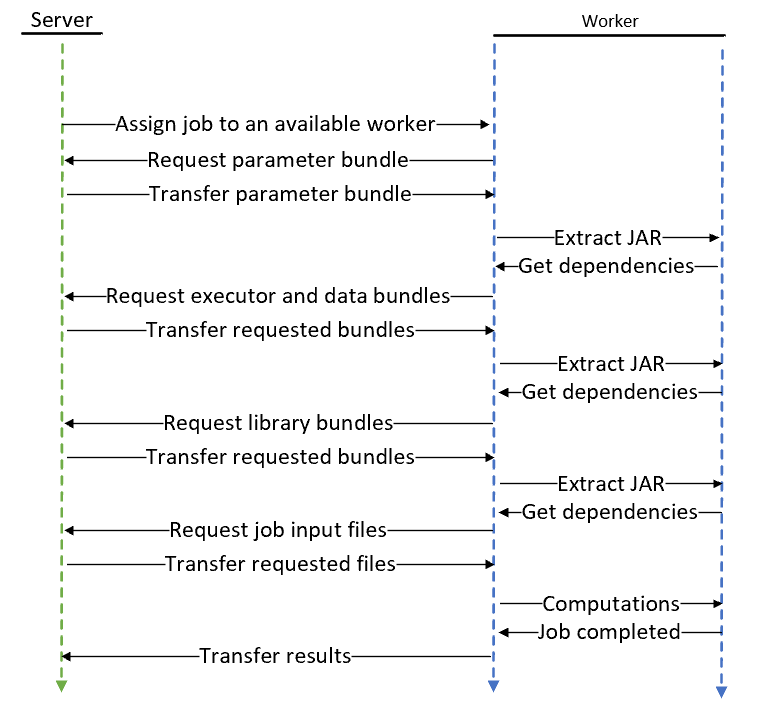
3.1.4. Process flow during a computational Job
The process flow occurring between a Techila Worker and the Techila Server during a single computational Job is illustrated below. The process consists of three main stages:
-
Initial Job assignment
-
Bundle transfers
-
Computation
The process starts by the Techila Server assigning a Job to an available Techila Worker. The Techila Worker then requests and transfers the Parameter Bundle from the Techila Server. The JAR file containing the Parameter Bundle is extracted and the content of the Manifest File is used to determine a list of Bundle dependencies. These dependencies specify what Bundles are requested from the Techila Server. If a Bundle listed in the dependencies is available locally on the Techila Worker, the local Bundle is used instead of requesting the Bundle from the Server.
The Server transfers the requested Executor and Data Bundles to the Techila Worker, where the JAR files containing the Bundles are extracted. The Manifest Files of these Bundles are used to determine further dependencies, and the need for additional Library Bundle transfers. As soon as all required Bundles have been transferred from the Techila Server to the Techila Worker, and the contents of the JAR files have been extracted, the computation can be started. After the Job has been completed, results are transferred to the Server.
Please note that, individual Job Input Files are transferred directly to the Techila Worker from the Server and Bundles are only requested by the Techila Worker if they are not available locally. The process flow during a computational Job, belonging to a Project created with the peach-function is illustrated below.
3.2. Integrating Techila Distributed Computing Engine in your application
The process of modifying a locally executable program to support execution in a Techila Distributed Computing Engine environment typically includes the following steps:
-
Locating the computationally intensive part of the code
-
Separating the computationally intensive part of the code to a separate entity. This part of the Techila Distributed Computing Engine enabled program is known as the Techila Worker Code and it will be executed on the Techila Workers.
-
Creating a locally executable piece of code that is used to control the distribution process. This part of the Techila Distributed Computing Engine enabled program is known as the Local Control Code and it will be executed on the End-User’s own computer.
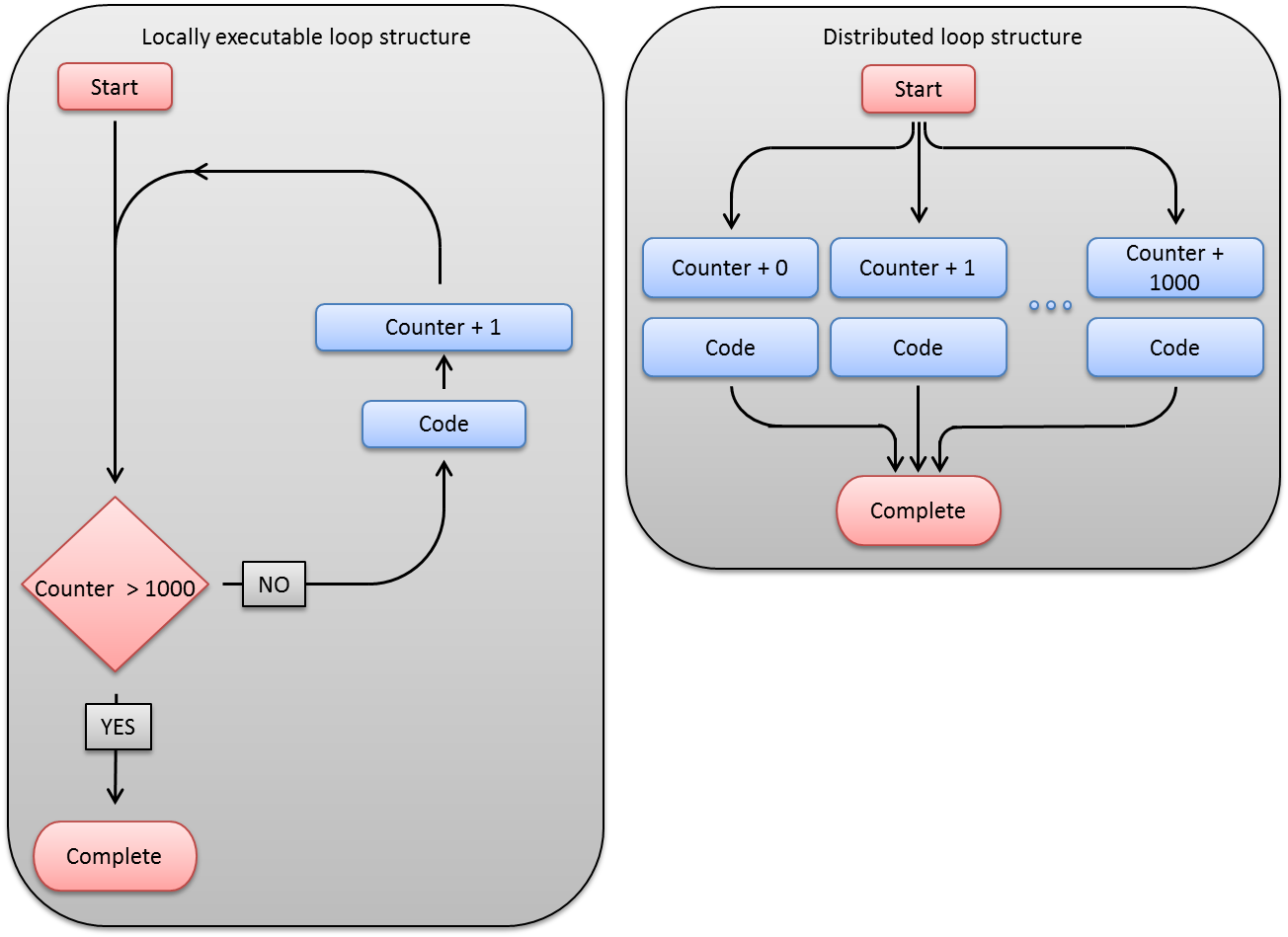
The image below demonstrates how the computational process flow will change as a locally executable loop structure will be converted to a Techila Distributed Computing Engine enabled version. In the locally executable loop structure, illustrated on the left side of image below, computational code inside the for-loop will be evaluated during each iteration. The iterative nature of the for-loop means that the code is evaluated several times in a sequential fashion, similar computational operation occurring on each iteration. Assuming that there are no recursive dependencies between the iterations, the iterations of the loop structure can be executed simultaneously on the Techila Workers in the Techila Distributed Computing Engine environment.
The distributed loop structure illustrated on the right side of image below corresponds to a situation where the computational instructions inside the for-loop have been extracted from the code into Techila Worker Code. The computational instructions in the Techila Worker Code will be executed on several Techila Workers simultaneously. This means that the computational instructions occurring in the locally executable loop structure can be evaluated simultaneously and independently, meaning the iterative nature of the program can be replaced with concurrent processing.
3.2.1. Local Control Code
Local Control Code is piece of code that is usually computationally light and will be executed on the End-User’s local computer. The Local Control Code will be used for creating the computational Project and will typically include definitions for the following parameters:
-
Name of the computationally intensive function or program (Techila Worker Code) that should be executed on Techila Workers
-
Number of Jobs in the computational Project
-
Input arguments for Techila Worker Code
-
A list of data files that should be transferred to Techila Workers
The Techila Worker Code can be e.g. a reference to a MATLAB m-file, an R script containing a computationally intensive function or to a precompiled binary. If you are using MATLAB and the file name refers to a MATLAB m-file, the Techila Distributed Computing Engine system will automatically compile the code into an executable binary. This binary file will then be transferred and executed on the Techila Workers with the specified input arguments.
In addition to these parameters, the Local Control Code can also be used to:
-
Define general Project parameters that can be used to control the distribution process
-
Automatically post-process the results after the Project has been completed
-
Implement advanced Techila features (introduced in Features)
3.2.2. Techila Worker Code
Techila Worker Code is piece of code that will be executed on the Techila Workers and usually contains all the computationally intensive operations related to the Project. The execution of the Techila Worker Code will be controlled by the parameters defined in the Local Control Code. Generally, the Techila Worker Code is therefore responsible for:
-
Performing the computationally intensive operations on the Techila Worker according to input arguments specified in the Local Control Code
-
Returning the defined output variables and/or output files from the Techila Worker
3.2.3. Process flow of a computational Project: Local Control Code and Techila Worker Code
The image below illustrates the roles of the Local Control Code and Techila Worker Code and their execution order. The process starts by executing the Local Control Code. This will create all necessary Bundles and the computational Project.
After the Project has been created, the Techila Server will divide the Project into Jobs and assign them to available Techila Workers. After all necessary Bundles have been transferred to the Techila Workers; the Techila Workers will start the execution of the Techila Worker Code and return the results to the Techila Server.
Results will either get transferred back to the End-User after all Jobs have been completed or results of individual Job result files can be streamed to the End-User as soon as they are available on the Server. The streaming feature is described here. The image below illustrates a situation where Streaming is not used.
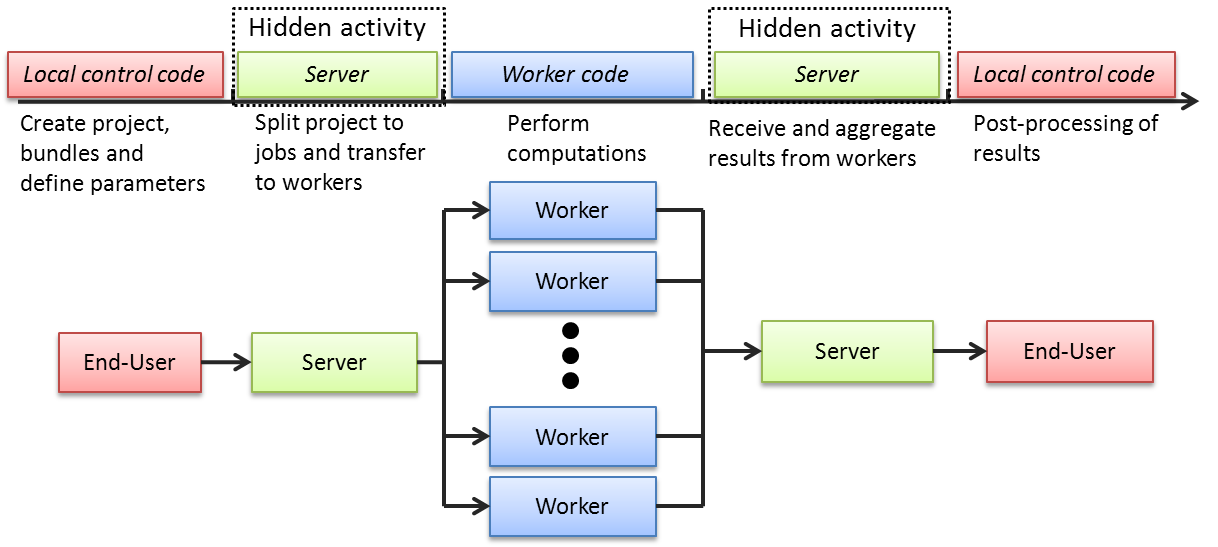
3.3. Understanding the performance statistics
When a computational Project is created, messages containing performance statistics and other useful information related to the Project creation process will be displayed. These performance statistics can be used to fine-tune the distribution process to improve overall performance.
The example below shows the printouts that are generated when one of the examples included in the Techila SDK is executed.
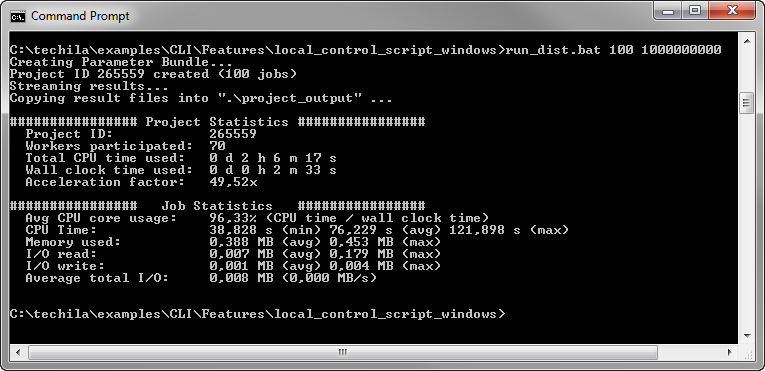
3.3.1. Project Statistics
The Project Statistics section contains a general overview on performance of the computational Project. This section is illustrated below.
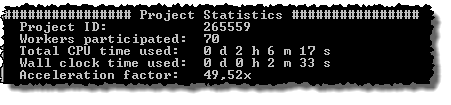
The Project ID line displays the Project ID number of the Project. The Project ID number is unique for all Projects in the Techila environment.
The Techila Workers participated line displays the number of unique Techila Workers that participated in the computational Project. In the example above, 70 unique Techila Workers participated in the Project.
The Total CPU time used displays the total amount of CPU time that was used during all of the computational Jobs.
The Wall clock time used line displays the amount of wall clock time that elapsed between the Project start and Project completion. More specifically, the value shown here is the difference in timestamps when the first Job was assigned to a Techila Worker and when the last result in the Project was returned to the Techila Server.
The Acceleration factor line displays the speed-up that was achieved in the Project. This value is calculated using the formula CPU time / Wall clock time.
3.3.2. Job Statistics
The Job Statistics section contains information on the performance statistics of the computational Jobs completed during the Project. This section is illustrated below.
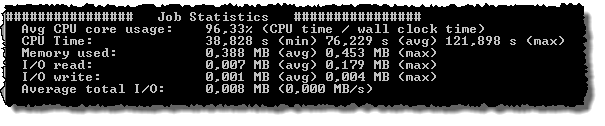
The Avg CPU core usage line displays the average efficiency in computational Jobs. This value is calculated using the formula CPU time / Wall clock time. A high value (e.g. over 95%) means that the computational Jobs were efficient. Smaller values (e.g. below 70%) could be an indication that there might room for improvement.
One of the most common reasons for low efficiency values are extremely short computational Jobs. An example of such a Job is shown in the image below.
The CPU time line displays information on how much CPU time was used in the computational Jobs. If the amount of used CPU time is small, it will be typically reflected as poor computational efficiency as displayed on the line "Avg CPU core utilization".
For example, in the screenshot below the average efficiency was only 32 %. This low efficiency was caused by the extremely short Jobs, where only fractions of a second of CPU time were used in each Job.

In these types of situations, it is recommended that you attempt to increase the duration of a computational Job by e.g. increasing the amount of computational operations performed in each Job.
Recommended minimum durations for computational Jobs vary depending on the programming language used and other properties of the computational Job. As a rule of thumb however, it recommended that the length of a computational Job should be at least 30 seconds as the drop off in efficiency in Jobs shorter than this can be substantial.
The Memory used line displays the amount of memory that was used in the computational Jobs. The values shown are peak values that occurred during the Jobs. The (avg) value is the average of the peak values and the (max) values is the largest reported peak value.
The I/O read line displays the amount of read activity generated when the computational Job was computed. The value displayed here includes the read activity generated in the actual executable program and read activity generated by the operating system such as loading libraries required by the executable program
These values are reported by the operating system, which may cause some additional variation in the values in cases where Techila Workers with different combinations of operating systems and processor architectures participate in the Project.
The I/O write line displays the amount of write activity generated when the computational Job was computed. These values are reported by the operating system in a similar manner as the read activity described above.
The Average total I/O line displays the total amount of read and write activity generated in the computational Job. This value is calculated by summing the reported average values displayed on the "I/O read" and "I/O write" lines. The average speed of the I/O activity is enclosed in the parentheses.
3.4. Techila SDK
The Techila SDK is a collection of library functions and other necessary components that enable the End-User to interact with the Techila Distributed Computing Engine environment using their own computer. These library functions can be used by the End-Users in their Local Control Code for creating the computational Project.
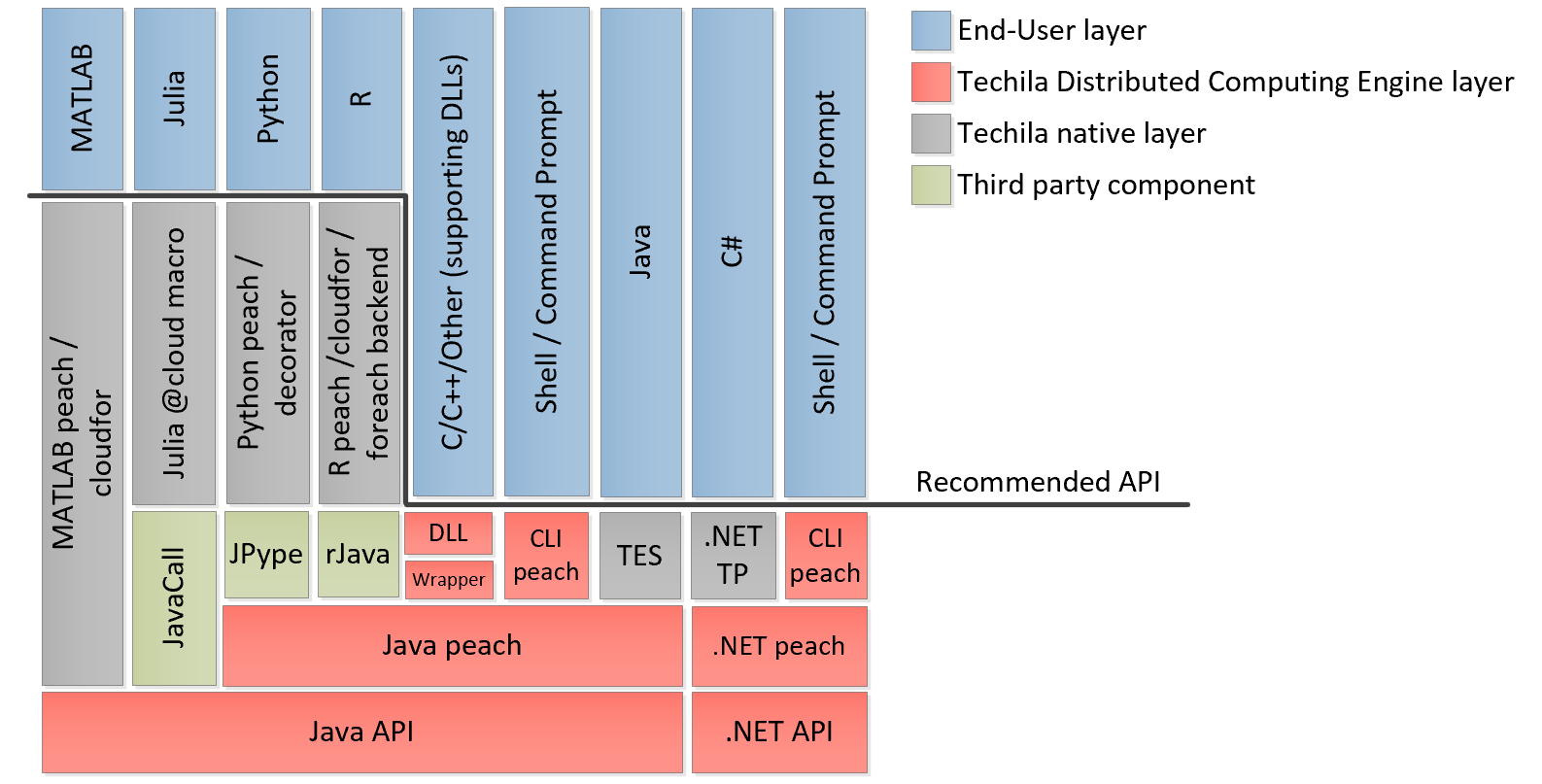
The library functions in the Techila SDK provide an easy-to-use interface and will hide the complexity related to the distribution process. The majority of the library functions in the Techila SDK are based on the underlying Java-based API, which can also be used to directly communicate with the Techila Server. There are also higher level helper functions (such as cloudfor and peach described in The cloudfor-function and The peach-function implemented in several programming languages, which can be used when creating computational Projects. These native wrappers provide a natural user interface, removing the need to call individual Java-methods directly. When using R, a TDCE foreach back end can be used to distribute computations, which allows you to run any existing code (that uses foreach) in a Techila Distributed Computing Engine environment with minimal changes. This also applies to packages using foreach internally, such as plyr.
When using a programming language that does not have native wrapper functions implemented, the Java API can be used. If the programming language does not support calls to Java, the Techila SDK includes shared libraries that can be used. These shared libraries include dynamically linked libraries (.dll`s) for Microsoft Windows and shared object files (.so`s) for Linux. Applications developed with programming languages supporting the .NET framework, such as C#, can access the Techila Distributed Computing Engine environment by using the Techila Distributed Computing Engine .NET API.
The image below illustrates the different layers in the Techila Distributed Computing Engine system.
Instructions for installing the Techila SDK can be found in Getting Started. Programming language specific steps can be found in the "Techila Distributed Computing Engine with" documentation series. These documents can be found here.
3.4.1. MATLAB
The recommended API for MATLAB applications is either the peach or cloudfor function. Native MATLAB implementations for these functions can be found in the following directory in the Techila SDK:
-
techila/lib/Matlab
This directory also contains several additional MATLAB functions, which are used internally by the peach and cloudfor functions.
Example material that uses the peach and cloudfor functions can be found in the following directory in the Techila SDK:
-
techila/examples/Matlab
Walkthroughs of the example material can be found in the Techila Distributed Computing Engine with MATLAB.
3.4.2. CLI
The CLI (Techila Command Line Interface) is the recommended API in situations where you wish to execute precompiled binaries in the Techila Distributed Computing Engine environment by using your operating systems command prompt or shell. The functionality of the CLI interface is included in the following file in the Techila SDK:
-
techila/lib/techila.jar
Example material that uses CLI interface can be found in the following directory in the Techila SDK:
-
techila/examples/CLI
Walkthroughs of the example material can be found in Techila Distributed Computing Engine with Command Line Interface.
3.4.3. R
The recommended API for R applications is either the peach or cloudfor function or the foreach back end. Native R implementations for these functions can be found in the following directory in the Techila SDK:
-
techila/lib/R
Example material that uses the peach and cloudfor functions and the foreach back end can be found in the following directory in the Techila SDK:
-
techila/examples/R
Walkthroughs of the example material can be found in Techila Distributed Computing Engine with R.
3.4.4. Java
The recommended API for Java applications is the functionality provided by the Techila Executor Service (TES). Native implementations for these functions can be found in the following file in the Techila SDK:
-
techila/lib/techila.jar
-
techila/lib/techilaworkerutils.jar
Example material that uses the Java TES functions can be found in the following directory in the Techila SDK:
-
techila/examples/java/tes
Java API documentation can be found in Techila Distributed Computing Engine with Java.
3.4.5. C#
The recommended API for applications developed with C# is the Techila Project (TP) API. This API consists of the following files in the Techila SDK:
-
techila/lib/TechilaManagement.dll
-
techila/lib/TechilaExecutor.exe
Example material for the TP API using C# programming language can be found in the following directory in the Techila SDK:
-
techila/examples/CSharp
Walkthroughs of the example material can be found in Techila Distributed Computing Engine with CSharp.
Additional documentation on the Techila Distributed Computing Engine TP API can be found in the following file:
-
techila/doc/TechilaManagement.chm
3.4.6. C/C++/Other
The recommended API for applications developed with C/C++ are the peach functions included in the shared libraries. These shared libraries can be found in the following directory in the Techila SDK:
-
techila/lib
Example material that uses the peach functions from the shared libraries can be found in the following directory in the Techila SDK:
-
techila/examples/C
Walkthroughs of the example material can be found in Techila Distributed Computing Engine with C.
Additional documentation on the peach functions can be found in Techila C Interface Reference.
3.4.7. Python
The recommended API for Python applications is the peach function. The native implementation for this function can be found in the techila package, which is located in the following directory in the Techila SDK:
-
techila/lib/python
Example material that uses the peach function can be found in the following directory in the Techila SDK:
-
techila/examples/python
Walkthroughs of the example material can be found in Techila Distributed Computing Engine with Python.
3.5. The cloudfor-function
The cloudfor-function is a helper function, which provides a very simple way to distribute computationally intensive loop structures to the Techila Distributed Computing Engine environment. Currently the cloudfor-function is available for the following programming languages:
-
MATLAB
-
R
Converting a locally executable for-loop to a cloudfor-loop can be performed by simply replacing the for-loop with cloudfor-loop in the code. A pseudo code representation of this conversion is shown below. Please refer to the documents Techila Distributed Computing Engine with MATLAB and Techila Distributed Computing Engine with R for programming language specific syntaxes and examples.
| Locally Executable | Distributed Version |
|---|---|
|
|
When using cloudfor-loops, the computational operations inside the loop structure will be automatically sent to Techila Workers for execution. All necessary workspace variables required during computations will also be automatically transferred to Techila Workers.
The functionality of the cloudfor-function is based on the peach-function. This means all features available for peach-functions, will also be available when using the cloudfor-function.
3.6. The peach-function
The peach-function (an acronym from Parallel Each) is an integral part of Techila Distributed Computing Engine. The peach-function hides the majority of the complexity related to the process flow of a distributed computing process, such as Bundle creation, result file processing and clean-up activities. The peach-function also provides a simple-to-use syntax, which can be used to create Projects and distribute computations. The simplified internal process flow of the peach-function is illustrated in Figure 14.
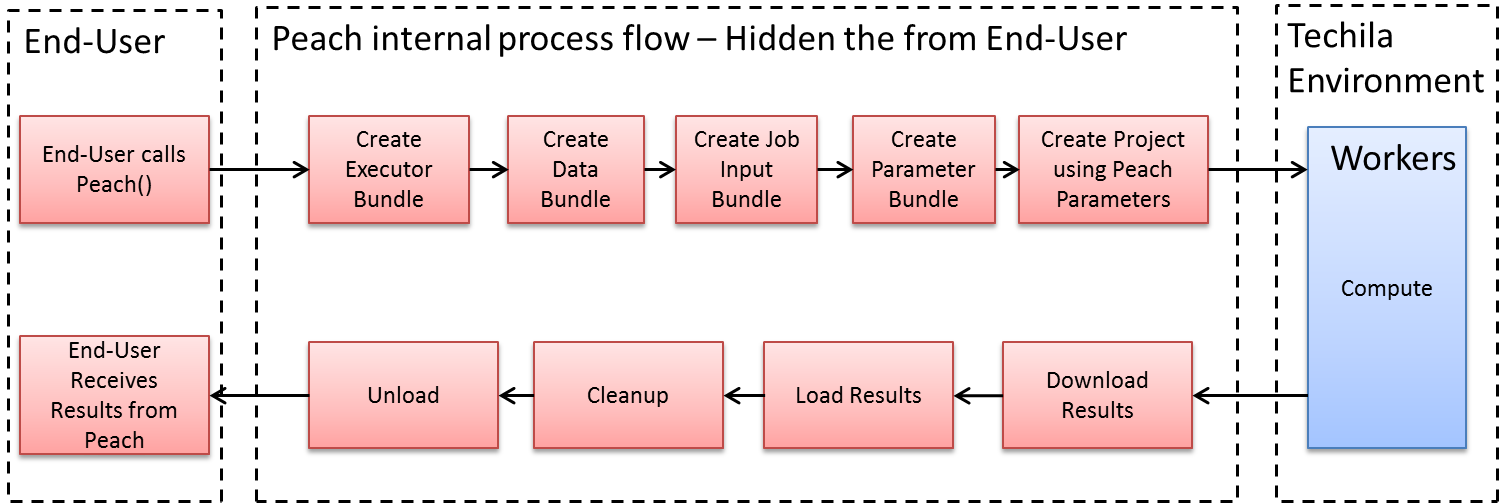
The process flow in the image above is simplified and is only intended to provide an outline level illustration of events initiated by a peach-function call. The internal process flow also includes Bundle state monitoring, meaning that Bundle creation only occurs if a matching Bundle has not been created earlier. Events taking place after the Project completion, such as clean-up operations, also happen automatically and will be invisible to the End-User. This means the End-User only needs to provide parameters for the peach-function and to take care of post-processing activities after the results have been received from the Server.
As mentioned here , the Local Control Code usually defines the following parameters:
-
Name of the computationally intensive function or program (Techila Worker Code) that should be executed on Techila Workers
-
Number of Jobs in the Project
-
Input arguments for the Techila Worker Code
-
Data files that are transferred to each Techila Worker
When using the peach-function, this information will be given to the peach-function as input arguments. The syntax of defining input arguments may vary depending on the programming language used.
Generally speaking, the peach-function syntax will typically include the following parameters:
peach(funcname,params,files,peachvector)
These parameters enable the End-User to control all the basic functionality in a computational Project. This includes defining the program that will be executed on Techila Workers, how many Jobs are created, what input arguments are given to the computationally intensive program and what additional files should be transferred to Techila Workers.
3.6.1. Funcname
The funcname parameter defines the code that will be executed on the Techila Workers. Depending on the programming language used, the funcname parameter can, for example, refer to a file containing a function definition or to a subroutine name. If the parameter refers to a MATLAB m-file, the code will be automatically compiled in to an executable binary and stored in the Executor Bundle, which will be transferred to the Techila Workers.
3.6.2. Params
The params parameter can be used to specify list of input arguments for the computationally intensive function that will be executed on Techila Workers. The params parameter can be used to transfer static and dynamic parameters.
Static parameters can be e.g. variables defined in the workspace of MATLAB or an R session. The values of these types of input arguments will be identical for all Jobs in the Project. Dynamic parameters can be elements of the peachvector and each Job in the Project will receive a different element. Elements of the peachvector can be defined as input argument using the special notation <param>. More information about the peachvector can be found here.
3.6.3. Files
The files parameter can be used to specify a list of files that will be stored in Data Bundles and transferred to each Techila Worker participating in the computational Project. Please notice that if you are using large files, or a large amount of small files, this can potentially create network congestion and reduce system performance. If individual Jobs in your Project require only some of the files on the list, please consider using the Individual Input Files feature (Please see Job Input Files) to transfer specific files to specific Jobs.
3.6.4. Peachvector
The peachvector is a vector containing elements, which can be given as input arguments to the executable function. This can be achieved by using the special notation <param> when defining the params parameter. This provides a method that can be used to easily perform parameter sweep type computations in the Techila Distributed Computing Engine environment. The length of the peachvector also determines the number of Jobs in the Project. An example of a simple peachvector containing the integers between one and five is illustrated in Figure 15.
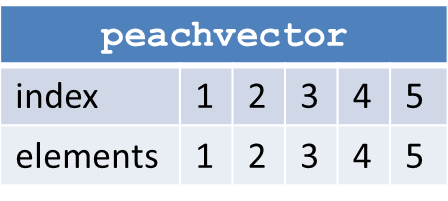
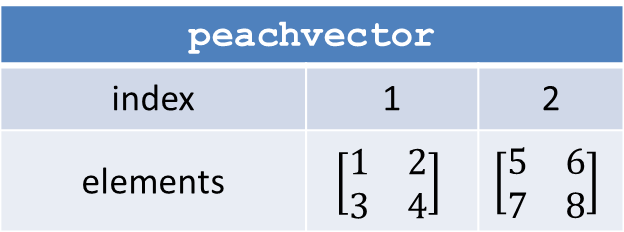
peachvector would create a Project containing five (5) Jobs.Depending on the programming language used, the elements of the peachvector can also be for example structures (MATLAB) or lists ®. For example, the peachvector shown in Figure 16 would create two Jobs, where each element of the peachvector would be a 2x2 matrix.
Using the funcname,params,files and peachvector parameters, the End-User has full control over the computational Project and is able to carry out complex computations in the distributed computing environment. The image below is intended to recap the effect of the four parameters and place them in to the proper context.
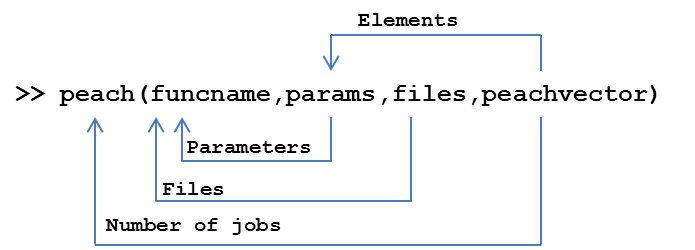
funcname parameter determines what is executed on the Techila Workers; params defines what input arguments are given to the executable program; files determines what files are transferred to Techila Workers and the peachvector determines the number of Jobs and provides elements that are used as dynamic input arguments for the executable program.3.6.5. Optional parameters for the peach-function
The peach-function can also be given a large number of optional parameters. These optional parameters are used to implement different features available in the Techila Distributed Computing Engine system, such as snapshotting, streaming and assigning each Job individual input files. Some of these optional parameters are covered in Features. Note that all of the features listed in Features are not available in all programming languages. More comprehensive lists of available features can be found in the "Techila Distributed Computing Engine with" documentation series.
3.6.6. Peachclient
The peachclient is a programming language specific piece of code that acts as wrapper for the Techila Worker Code. The peachclient wrapper will used automatically when creating a Project with the peach or cloudfor functions for the following programming languages:
-
MATLAB
-
R
-
Python
From the End-Users point of view, using the peachclient wrapper will be transparent, meaning it will be used automatically.
The peachclient wrapper will enable the End-User to use peachvector elements as input arguments for the executable program. These peachvector elements can contain non-integer values such as the ones illustrated in the image below. If the peachclient wrapper is not used, the End-User can only use the default values produced by the Job splitter on the Server. These values will range from one (1) to the total number of Jobs.
By default, the peachclient is not used when:
-
The computational Project is not created using peach- or cloudfor-function
-
The peach-function is used to distribute a precompiled binary
-
The programming language does have support for the
peachclientwrapper
4. Features
This Chapter contains an overview of the technologies available in Techila Distributed Computing Engine. The syntaxes for using the features is not approached in this document, but instead it focuses on the general idea of the features.
The syntax for using the features is shown in the "Techila Distributed Computing Engine with" documentation series, which focuses on language specific implementations. If you are interested in executing precompiled binaries or other independently executable applications directly from the command line interpreter of your operating system, information in Techila Distributed Computing Engine with Command Line Interface will be useful.
4.1. Snapshots
Snapshotting is used to improve the fault-tolerance of computations and to reduce the amount of computational time lost due to interruptions. In practice, this is done by storing the state of the computations at regular intervals in snapshot files. These snapshot files are then transferred to the Server at regular intervals from the Techila Workers. When interruptions occur, these snapshot files are transferred to other available Techila Workers where the computational process can be resumed by using the intermediate results stored in the snapshot file.
The differences in workflow between a snapshotting and a non-snapshotting Project are illustrated in the images below.
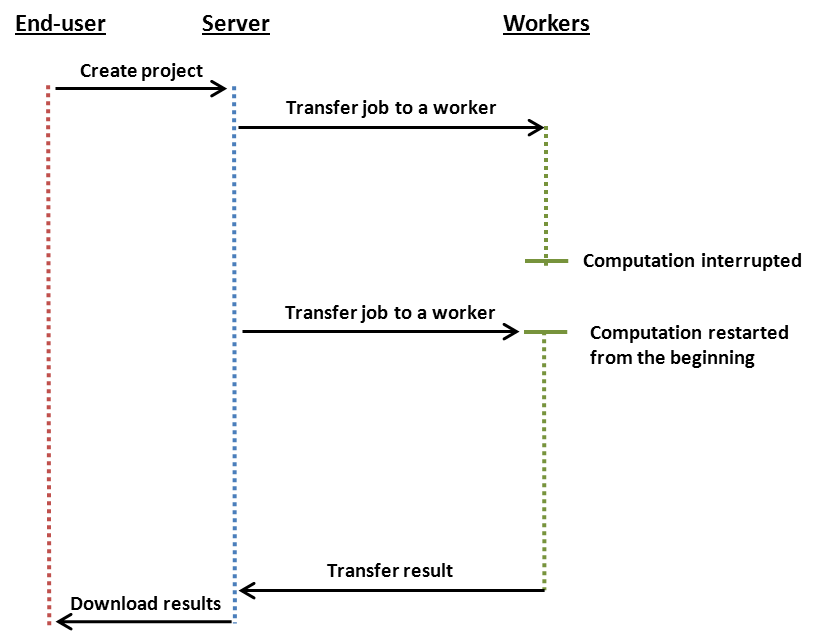
Non-snapshotting workflow: The computations begin when the Server has transferred the Job and all relevant Bundles to a Techila Worker. When the computations are interrupted, the Job assigned to the Techila Worker is terminated. The Job is then assigned to a new Techila Worker, where the computations are resumed from the beginning. All the computational work that was done on the first Techila Worker is lost.
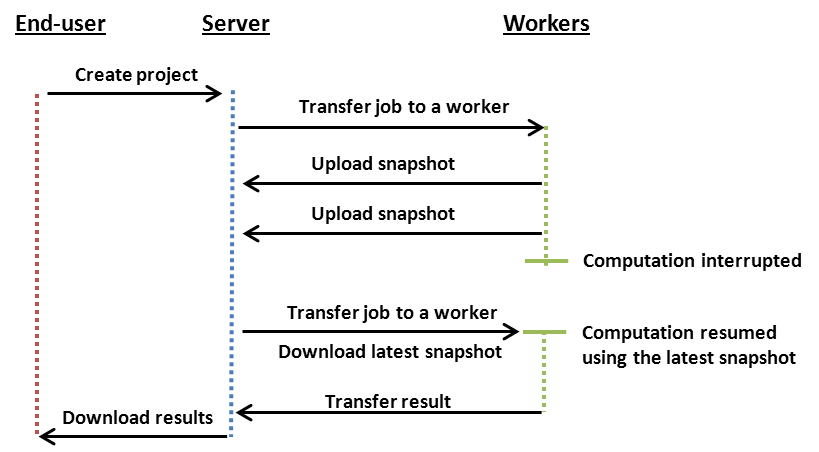
Snapshotting workflow: The computations begin when the Server has transferred the Job and all relevant Bundles to a Techila Worker. During the computations, intermediate results are stored in snapshot files, which are uploaded to the Server at regular intervals. When the computations are interrupted, the Job assigned to the Techila Worker is terminated as with the non-snapshotting Project. The Job is then assigned to a new, available Techila Worker. The latest snapshot file is also transferred to the Techila Worker, which is used to resume computations.
When designing your snapshot routine, the following aspects are controlled by the End-User:
-
The information that is stored in the Snapshot file
-
The upload interval how often Snapshot files are uploaded to the Server
Remember these points when designing your snapshot routine:
-
Snapshot generation creates I/O activity, which can reduce system performance. Only generate snapshots at a reasonable frequency. It is also advisable that you profile your code locally to see how often snapshots are generated.
-
Snapshot transfers require network bandwidth. Only store relevant information in the snapshot file
The snapshot procedure also has a built-in limit that control the Snapshot process:
-
Snapshots are only made available for transfer at fixed time intervals. This interval is defined by the Techila Administrators. The default value is 30 minutes.
4.2. Streaming
Streaming is a feature that enables individual results to be downloaded as soon as they are available on the Techila Server. This differs from the normal convention, where all the results are transferred simultaneously to the End-Users computer after all the Jobs have been completed. Streaming has the following benefits:
-
Helps to reduce network congestion. The data transfers from the Server to the End-Users computer are distributed over a longer time period.
-
Enables post-processing activities to commence sooner. Individual result files streamed from the Server can be post-processed on-the-fly with the Callback Function. Click here for more information about callback functions.
Differences in how results are transferred back to the End-User are illustrated in the image below. When streaming is not used, the results are aggregated on the Server and transferred to End-Users computer after the last Job of the Project has been completed. With streaming, results are transferred to the End-User in a continuous manner.

4.3. Callback functions
A callback function is a function that is called through a function pointer. Callback functions can be also be used with the peach-function. The callback function is executed once for result file transferred from the Techila Server, providing a flexible way to process each result as soon as it has been downloaded from the Techila Server.
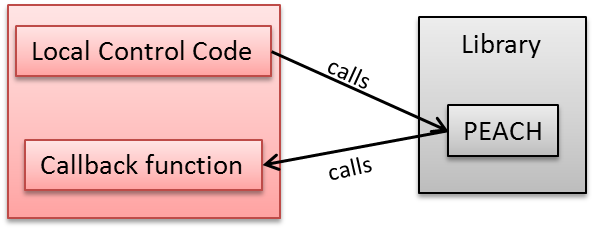
The callback function is often associated with the Streaming feature, where it can be used to post-process each result as soon as it has been transferred from the Server.
The callback function helps to reduce memory consumption on the End-Users computer. As results can be post-processed individually, the amount of data located in memory at any given time is reduced. Implementing the callback function feature requires that a callback function is added to the Local Control Code. The callback function can be used to operate directly on the result files or the function can be given values of individual results as input arguments.
The general process flow of a streamed Project utilizing a callback function is shown in the image below.
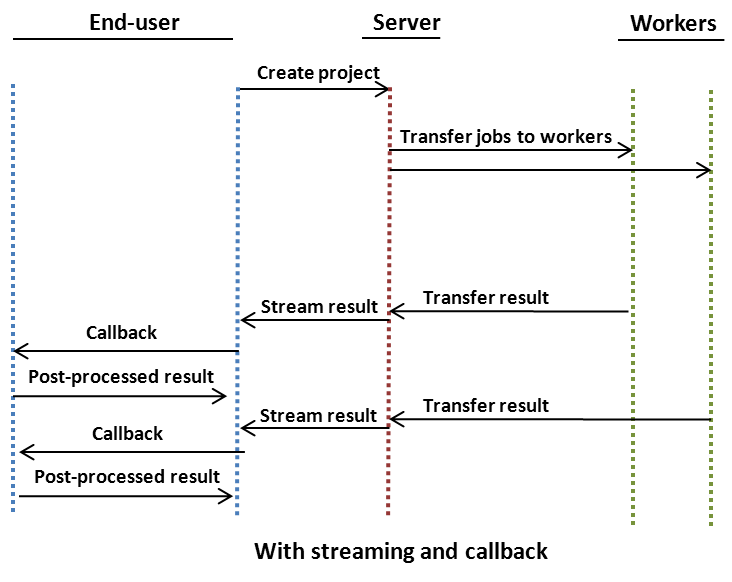
4.4. Job Input Files
Job Input Files enable the End-User to associate different input files for each Job. This is different from the normal convention, where all the files in Data Bundles are transferred to each Techila Worker. These differences are illustrated in in the image below
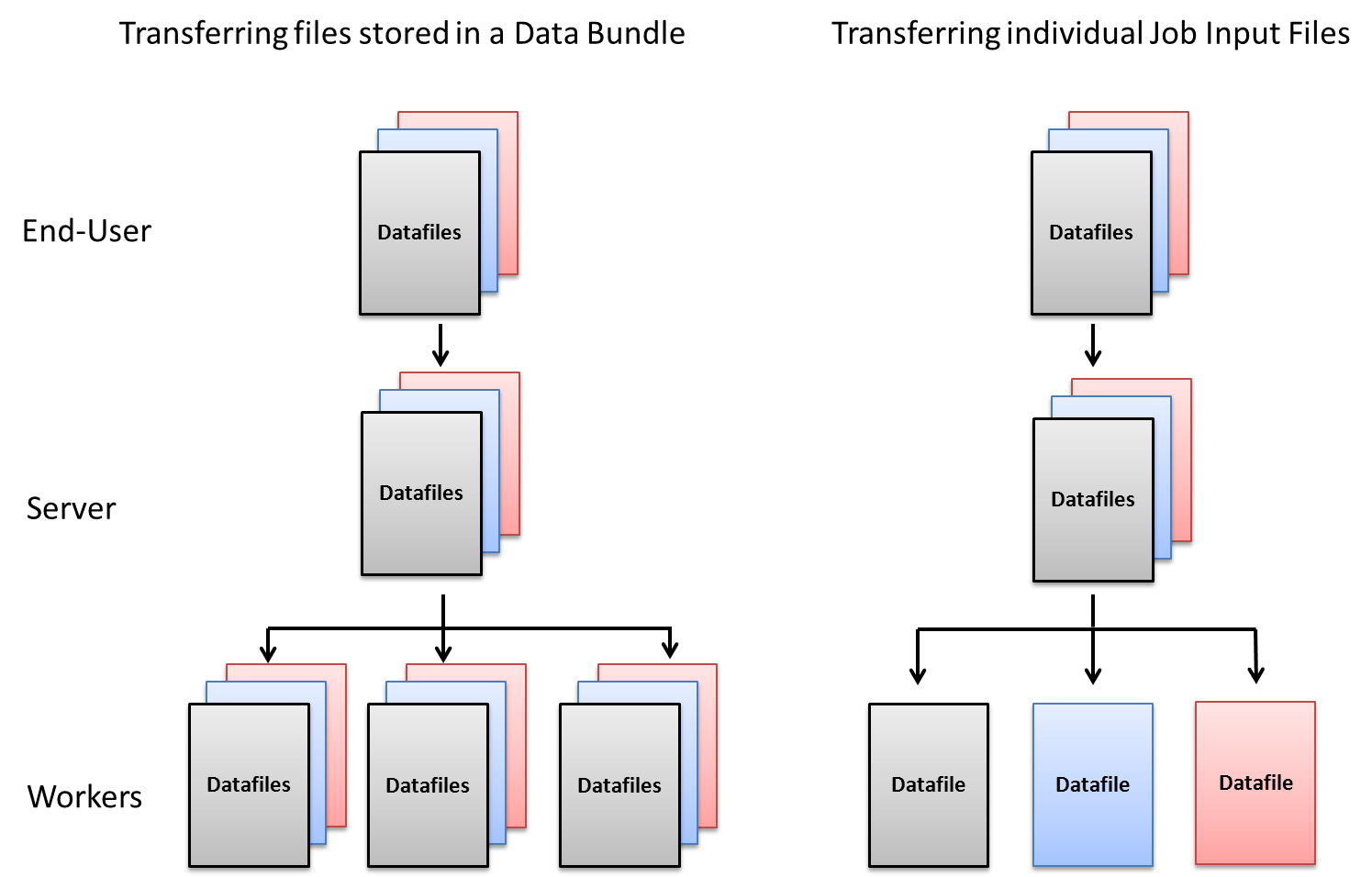
Consider an example scenario, where a set 100 data files are analysed and each Job only requires access to a specific data file. This means that transferring all of the data files to all Techila Workers is not required and only results in unnecessary network traffic. Individual input files can be used to reduce the amount of network traffic.
Depending on the application, transferring Job-specific input files can also:
-
Reduce memory consumption. Loading only the necessary input data into memory means that less memory is consumed.
-
Reduce memory overhead. Loading only the required input data into memory means that less time is required to perform the load procedure.
When Job Input Files are used, a separate Job Input Bundle is created that is used to transfer the data files to the Server. The Techila Server then distributes individual files from this Bundle to the Techila Workers that require them. The image below illustrates a situation, where the Job Input Files feature is used to transfer different input files for different Jobs. The names of these files are datafile1.dat, datafile2.dat and datafile3.dat. These files are stored in the Job input Bundle and transferred to the Server.
The Techila Server then distributes files from the Bundle to the Techila Workers that request them. When a file is transferred to a Techila Worker from the Server, it is renamed according to the parameters in the Local Control Code. The image below demonstrates a situation where the names have been defined to input.dat. The renaming is performed in order to provide a consistent way of accessing input files during each Job.
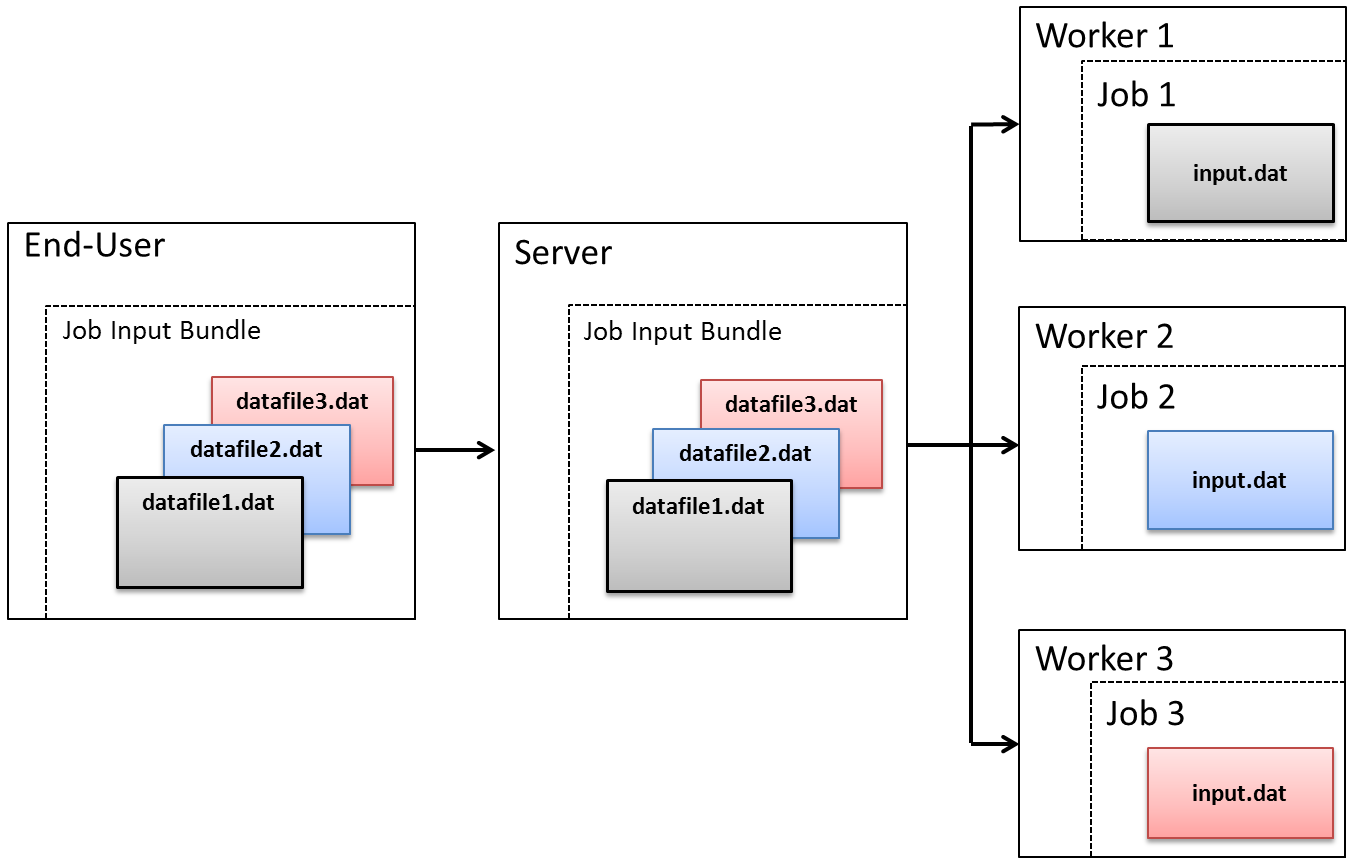
input.dat file name. For example, Techila Worker 1 knows datafile1.dat as input.dat, Techila Worker 2 knows datafile2.dat as input.dat etc.4.5. Precompiled Binaries
A precompiled binary can be distributed to the distributed computing environment with the peach-function or by directly using the Management Interface Methods. Techila Distributed Computing Engine can also be used to execute binaries for multiple operating systems and/ or architectures in a single Project, making utilization of heterogeneous computing resources more efficient
When distributing precompiled binaries, the peachclient wrapper will not be used to transfer input parameters. This means that input parameters for the binary must be defined manually as Project parameters. Input parameters that are defined in the Project parameters are available for all Jobs and can be referenced and used by the Techila Workers. Input parameters defined in the Project parameters can be referenced with the %P() notation, which returns the value of the parameter in the parentheses. For example, if the parameter param1 is defined in Project parameters, it can be referenced with %P(param1). Please note that the jobidx parameter is generated automatically on the Techila Server when the Project is split into Jobs, which means that defining it can be referenced with the %P(jobidx) notation without defining the parameter in the Project parameters.
4.6. Project Detaching
Normally, the Local Control Code used to create the computational Project waits for the completion of the Project. When a Project is detached, the program used to create the computational Project does not wait for the completion of the Project, but instead returns immediately after all of the computational data has been transferred to the Server. This means that the program can be used for other purposes while the Project is being computed.
The differences between a normal computational Project and a detached Project are illustrated in the image below.Jobs belonging to the detached Project are distributed to the Techila Workers and then computed as normal. The results are transferred to the Server where they are stored. Project results can be downloaded by using the Project ID number when making a download request.
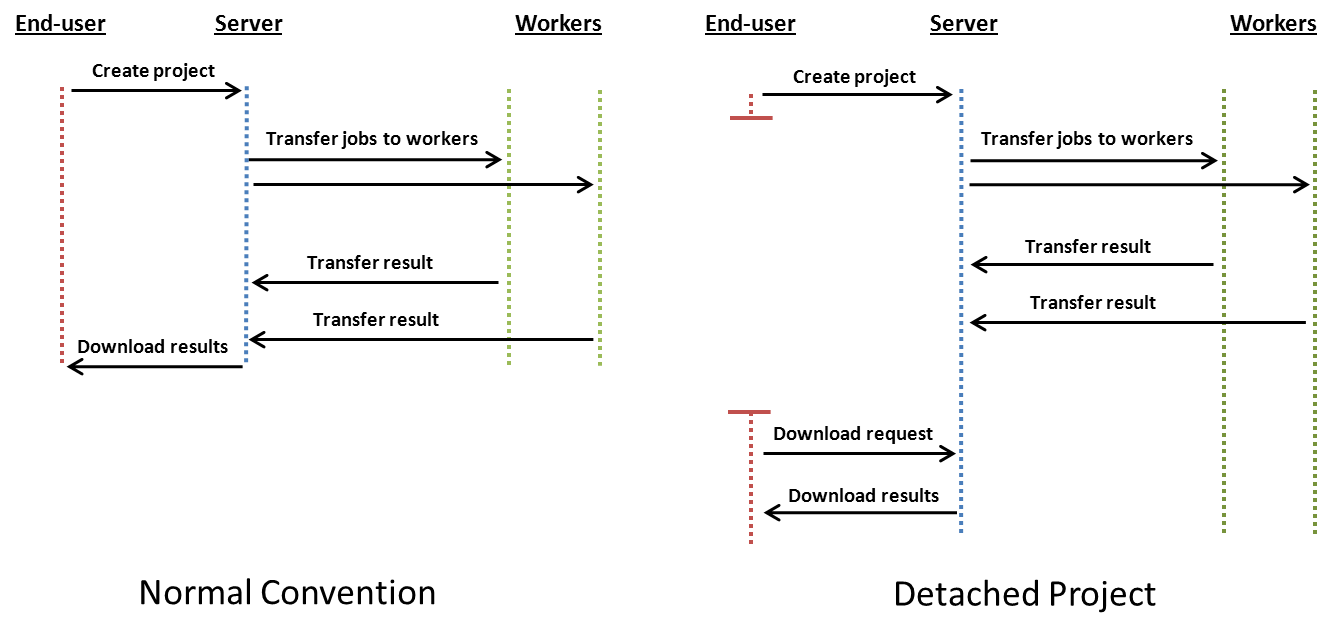
Download requests can be made for any previously completed Projects, as long as the results are still available on the Techila Server. This means Project results can also be downloaded in situations where the program used to distribute the computations crashed before results could be downloaded.
4.7. Remote Compiling
Remote Compiling makes it possible perform compilations on Techila Workers. Techila Workers can only be used in Remote Compilation Projects if they can provide a suitable compiler. Before taking Remote Compiling into use, please verify the terms of your compiler license.
The End-User can use these Techila Workers to compile binaries for the Techila Worker’s platform, making it possible to efficiently use Techila Workers running different operating systems.
For example, if you develop your application on a Linux platform and you want to also use Windows Techila Workers to power your Project, you can use Techila Distributed Computing Engine to compile your application automatically for remote platforms. Remote Compiling uses the compilers on your Techila Workers to build your application for the Windows platform. The Remote Compiled Windows executable can then be included in the computational Project. This enables computing the Project on a heterogeneous platform, which consists of Windows and Linux operating systems.
The differences in work flow with and without Remote Compiling in a heterogeneous computing environment are illustrated in the images below.
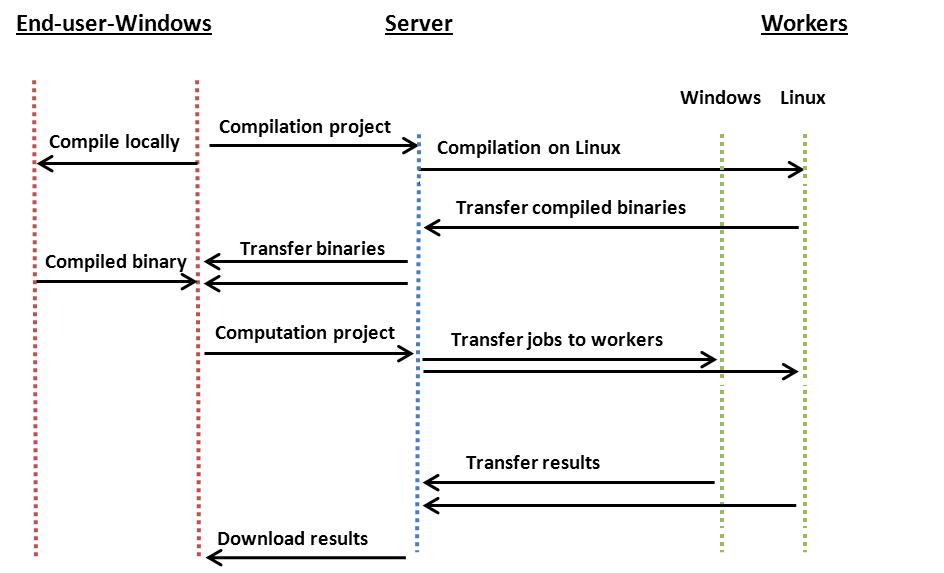
Work Flow with Remote Compiling: With Remote Compiling, separate Projects are created which are used to compile the binaries on all available platforms. By default, the End-Users computer is used to compile the binary for that specific platform. When the binaries have been compiled on the Techila Workers, the compiled binaries are transferred back to the End-Users computer. Binaries for different platforms can now be used to create a computational Project where Jobs can be assigned on Techila Workers of all platforms.
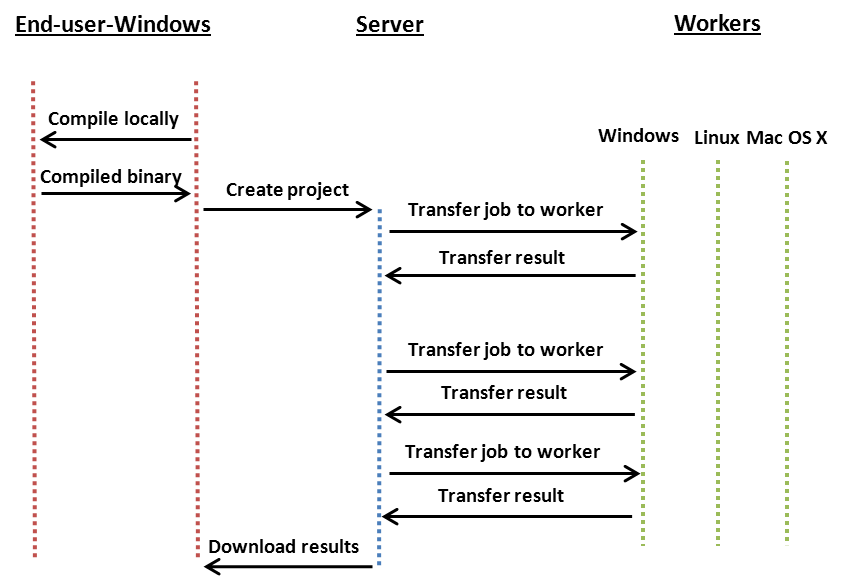
Workflow with NO Remote Compiling: When Remote Compiling is not used; Jobs can only be assigned to Techila Workers that have the same native operating system as the End-Users computer, which was used to compile the binary. Note that this limitation only applies to compiled languages.
4.8. Iterative Projects
Using iterative Projects is not so much a feature as it is a technique. Projects that use the output values of previous Projects as input values can be implemented for example by placing the peach-function inside a loop-structure. The general process flow with iterative Projects is shown in the image below.
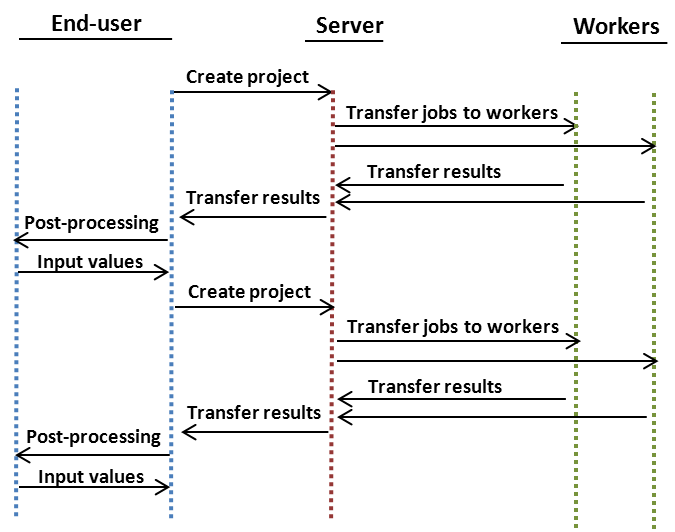
When designing iterative Projects, the state of the computations should be saved locally to a file on the End-Users computer every time a Project has been completed. This file can then be used as a restore point, which can be used to resume the iterative process in case of an interruption.
5. Advanced Features
This Chapter contains an overview of some of the more advanced Techila Distributed Computing Engine features and pointers to the documents where more information can be found on the subject.
Please note that using the advanced features described in this Chapter will require that your local Techila administrator has performed the necessary configurations. Please contact your local Techila administrator for more information.
5.1. Interconnect - Processing Parallel Workloads
The Techila interconnect feature allows the processing of parallel workloads in the Techila Distributed Computing Engine environment. More specifically, this feature allows Jobs in the same Project to transfer data to other Jobs in the same Project. This is done by adding the necessary Techila interconnect function calls to the code that is executed on the Techila Workers.
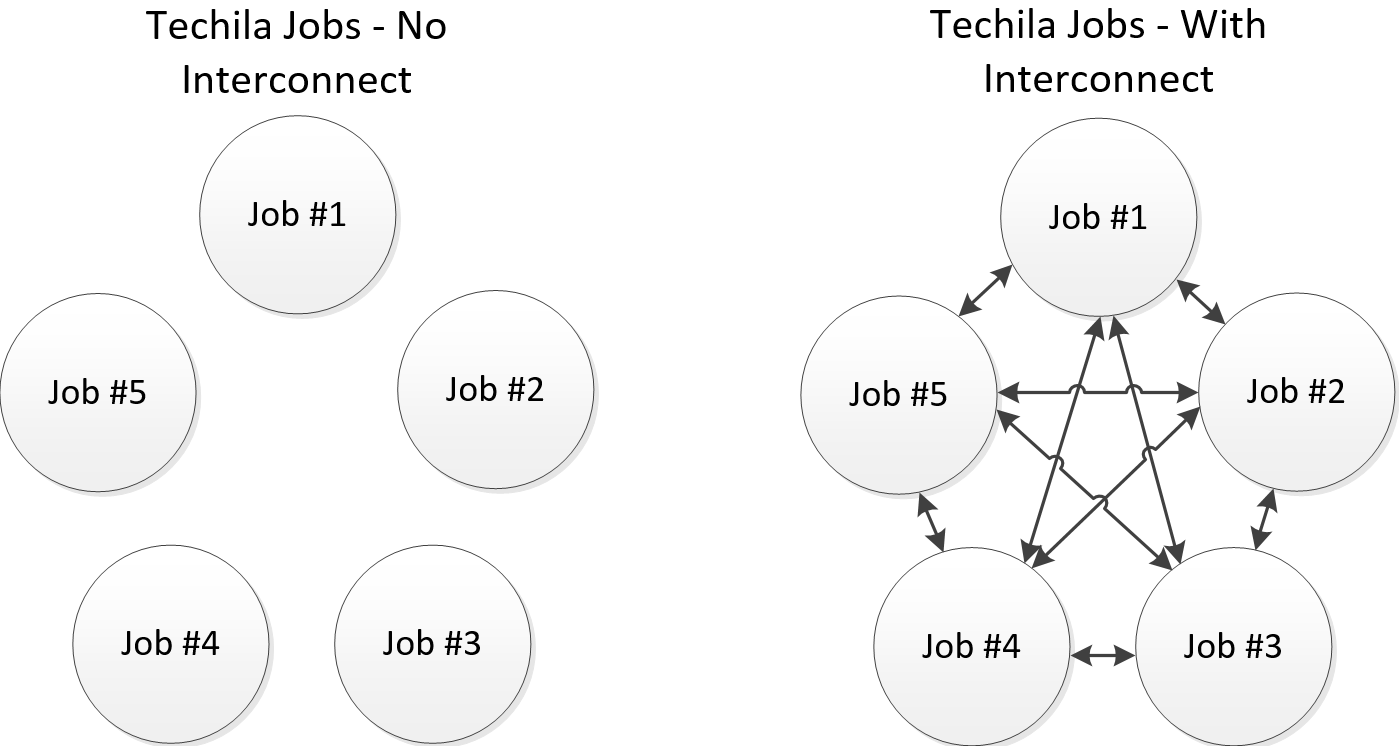
More information about this feature can be found in the Techila Interconnect document.
The Techila SDK also contains example material that illustrates how the Techila interconnect functions can be used with different programming languages. Walkthroughs of these examples can be found in the programming language specific "Techila Distributed Computing Engine with" document series.
5.2. Active Directory Impersonation - Accessing Restricted Data
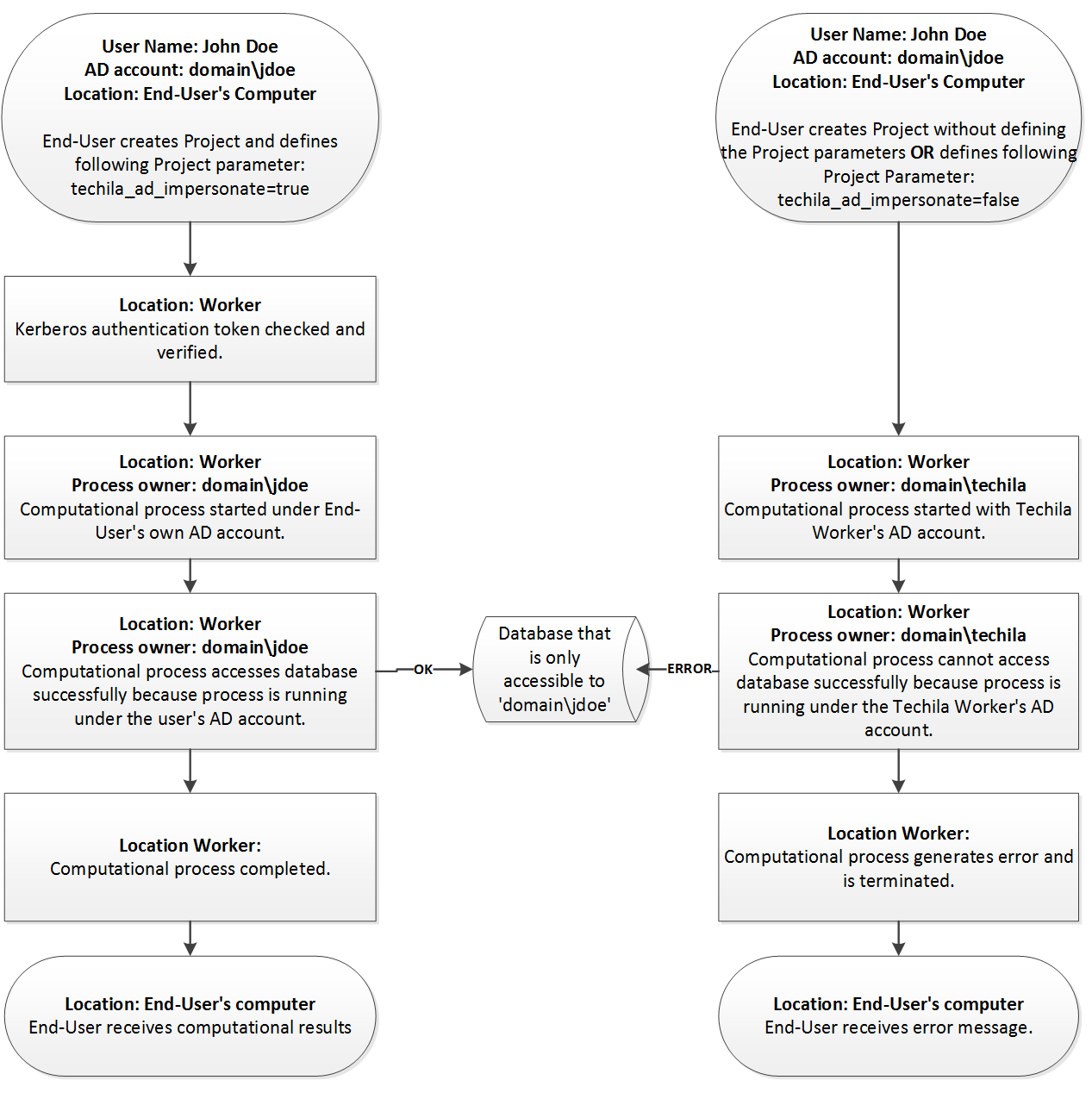
Techila Active Directory impersonation allows executing computational code on the Techila Worker using the End-User`s own Active Directory (AD) account. This means that the Jobs will have similar access permissions as the End-User`s AD account. This allows the computational code to access data resources that would be otherwise inaccessible and can be used to access e.g. resources of the following types:
-
Personal data files
-
Databases requiring AD authentication
In order for the End-User to use AD impersonation, the following Techila Project parameter will need to be enabled in code that is used to create the Project:
techila_ad_impersonate=true
Please note that before Active Directory impersonation can be used, the Techila Distributed Computing Engine environment will need to be configured accordingly. Please contact your local Techila administrator for more information about whether or not the feature can be used in your Techila Distributed Computing Engine environment.
In addition, the following criteria must be met for the End-User environment:
-
End-User must be using a computer with a Microsoft Windows operating system
-
End-User must be logged in using their own AD account
The figure below illustrates how enabling and disabling AD impersonation affects access permissions in a Techila Project.
5.3. Semaphores - Limiting Simultaneous Operations
Semaphores can be used to limit the number of operations that are performed at the same time during a Project. A typical situation where semaphores are needed can arise when working with a data source, which only allows a specific number of simultaneous connections. In this situation, semaphores can be used to limit the number of established connections from Jobs to the maximum number allowed by the data source.
The Techila Distributed Computing Engine system supports two different types of semaphores:
-
Project-specific semaphores
-
Global semaphores
Project-specific semaphores can be created by the End-User when they are creating the computational Project. Project-specific semaphores only exist for the duration of the Project, after which they will be automatically removed. Semaphore tokens from Project-specific semaphores can only be reserved in Jobs belonging to the same Project that is linked with the semaphore.
Global semaphores can only be created by Techila administrators. Global semaphores are not linked to any specific Project, meaning global semaphores will remain on the Techila Server until removed by a Techila administrator. Semaphore tokens from global semaphores can be reserved by any Job in the Techila Distributed Computing Engine environment.
Each semaphore has a specific number of semaphore tokens. These tokens can be reserved by using the functions included in the Techila Distributed Computing Engine API. Each time a token is reserved, the number of available tokens is reduced by one. When no available tokens exists, the requests will, by default, wait until a semaphore token becomes available (i.e. released from another Job).
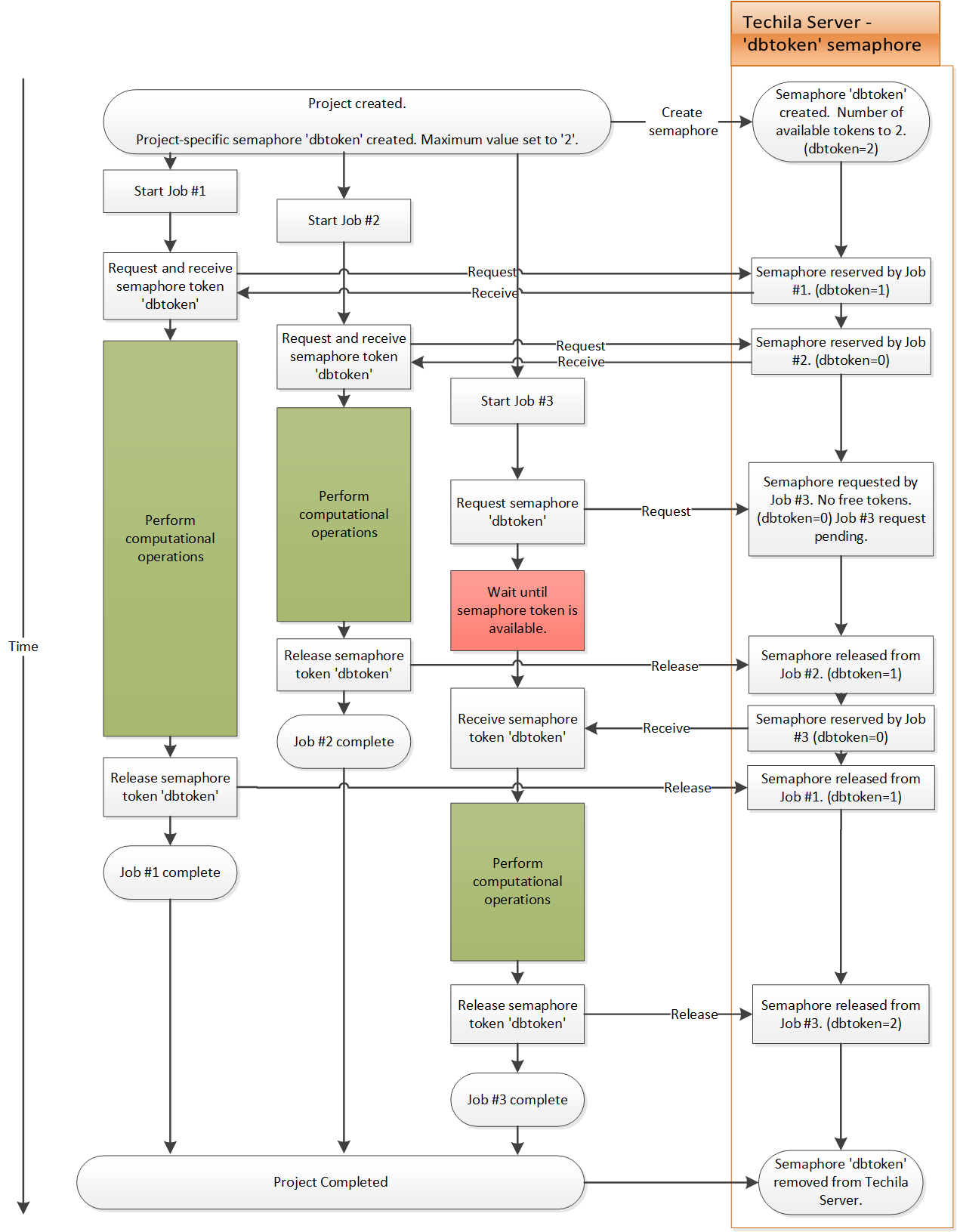
The figure on the following page illustrates how Project-specific semaphores can be used to limit the number of simultaneous operations in a Project.
In the figure, an End-User has created a Project, which defines that a Project-specific semaphore called dbtoken should be used. This will create the dbtoken semaphore on the Techila Server and set the maximum number of tokens to two. This means that a maximum number of two dbtoken semaphore tokens can be reserved by Jobs at any given time.
The first token request is made by Job 1. At this point the Techila Server has two tokens available, meaning the request can be filled. After a token has been reserved by Job 1, the free token count is reduced to one on the Techila Server.
After this, Job 2 request a token, which again can be filled because there is a free token on the Techila Server. After a token has been reserved by Job 2, the amount of free tokens will be reduced to zero on the Techila Server.
When Job 3 tries to reserve a token, there are no free tokens on the Techila Server. This means that Job 3 will queue until a free token becomes available. When Job 2 releases a token, the token will be reserved by Job 3. After the token is reserved, Job 3 can start performing the computational operations.
After all Jobs have been completed, the Project will also marked as complete. This will also cause the Project-specific semaphore information to be removed from the Techila Server.
5.4. Intermediate Data - Access Intermediate Results & Control Job Workflow
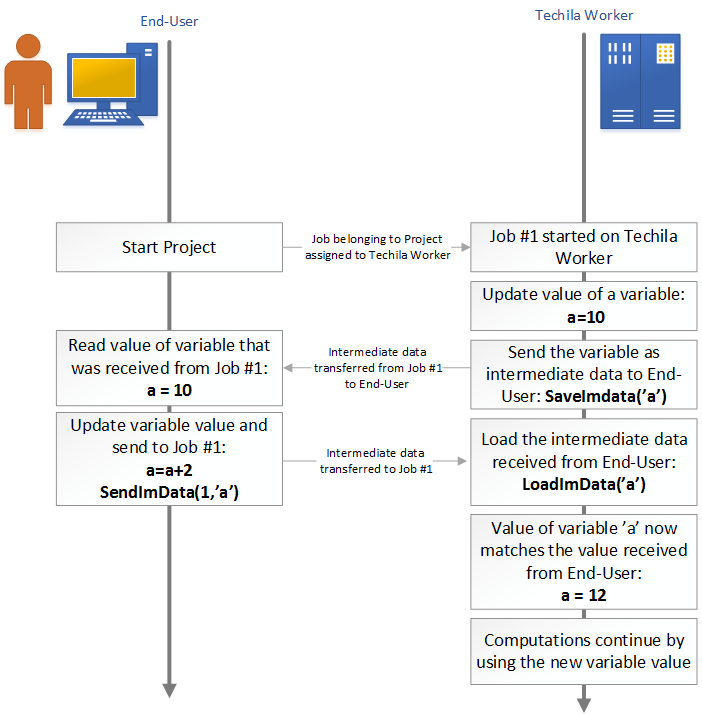
Intermediate data can be used to transfer result data from Jobs that are currently being processed, before the Job is completed. This allows you to e.g. view the values of variables at different stages of the computational Job while the Job is being processed.
Intermediate data also allows you to transfer data from your computer to the Job, while it is being processed on the Techila Worker. This means that you can send control signals to e.g. update the workspace variable values while the task is being processed without interrupting the computational Job.
Using intermediate data to transfer information to and from computational Jobs can be used to add flexible control logic to a distributed application and to add an interactive feel by viewing intermediate results when you are working with Jobs that have a very long execution time.
Intermediate data is currently available for the following programming languages:
Intermediate data is transferred by using programming language specific helper functions LoadImData, SaveImData and SendImData. Please see the programming language specific guides for the exact syntax on how to use these helper functions. The image below illustrates how these functions can be used to update the value of a variable during a computational Job.
|
Note
|
All intermediate data transfers that take place between the Jobs and the End-User are asynchronous. This means that the data transfers take place intermittently (as determined by internal polling intervals in the TDCE system) rather than in a steady stream. |
6. Distributing Computations with the Java API
The Java API contains the Java methods that are used to distribute computations, regardless of whether or not the peach-function is used. These Java methods can also be called by the End-User directly, if for some reason the End-User does not want to use the higher level API functions such as the peach-function.
When creating a computational Project using the Java API, each Java method needs to be called separately. This means that the amount of code in the Local Control Code is much larger and more complex when compared to a similar implementation that uses the peach-function. It is therefore highly recommended to use the peach-function when possible, at least when getting familiar with Techila Distributed Computing Engine system.
6.1. Local Control Code
The general activities occurring in the Local Control Code are the same, regardless of whether or not the peach-function is used. The Local Control Code contains information about what is executed on the Techila Workers, the number of Jobs and list of required files and parameters. A typical piece of Local Control Code used to create a computational Project will includes, at minimum, the following Java API methods.
| Java API method | Functionality |
|---|---|
init |
Initialise the interface library |
open |
Open a handle |
createSignedBundle(s) |
Bundles created for the binary and data files. This method is called once for every Bundle |
uploadBundle |
Uploads a Bundle associated with the handle (created with createSignedBundle) to the Techila Server. |
approveUploadedBundles |
Approve uploaded Bundles. All Bundles uploaded with the given handle are approved. Possible errors are recorded in the log. |
useBundle |
Set the Bundle to be used |
createProject |
Create a Project and Jobs with given parameters and assigns Techila Workers. |
waitCompletion |
Wait for Project completion |
downloadResult |
Download results from the Techila Server |
unzip |
Unzip the Project zip file associated with the handle. |
getResultFiles |
Get the unzipped result filenames. |
cleanup |
Cleans up temporary files |
close |
Closes the Project handle |
unload |
Unloads the Techila Distributed Computing Engine library and removes temporary folders |
6.2. Techila Worker Code
The Techila Worker Code is executed on the Techila Workers and contains all the computationally intensive operations. The execution is controlled by the parameters defined in the Local Control Code. On a general level, the Techila Worker Code is therefore responsible for:
-
receiving and using Job specific parameters and input files
-
performing the computationally intensive operations
-
storing the results in result files
When distributing computations without the peach-function, the parameters are transferred directly to the executable. This means that the End-User must ensure that the parameters are interpreted correctly by the executable.
7. Application Highlights
This Chapter contains some examples about more advanced implementations of the Techila Distributed Computing Engine technology and how it has been used to speed up computations.
7.1. Simulink
Simulink is a graphical add-on to MATLAB which can be used to model and simulate complex systems. Developing an accurate, realistic Simulink model takes time. An accurate model performs as expected and produces the desired results. But the added complexity can cause unacceptable simulation times. This article shows how to improve simulation performance, without breaking the bank.
Simulating accurate, realistic Simulink models with many parameter combinations can take very long times. The growing data requirements of modern business put engineers under pressure. Techila has a long history in enabling fast and scalable simulation and analysis in MATLAB. This example looks at how to speed up Simulink computing without having to cut corners.
In this Chapter, we provide an example how to run a Simulink model in Techila Distributed Computing Engine environment. We do this using a MathWorks example, which simulates the Van der Pol oscillator.
Our simulation in Techila Distributed Computing Engine environment is based on the publicly available Mathworks example, with a few modifications were made. First of all, we changed the solver to use fixed steps instead of variable steps. In some cases, this can give the engineer a better control over the simulation process and time to solution. This also makes the executable standalone. This enables scalable execution of the model in the Techila Distributed Computing Engine environment without need to install Simulink on the compute nodes.
The second change affects the startup performance of the executions. In the original example, the whole range of parameter values was saved into a single block parameter file which was indexed by the model binary. This is much slower than having a different block parameter file for each simulation.
In a separate test, we measured the execution time of compiled Simulink model with two different block parameter files. File #1 contained only one parameter set, file #2 contained 8821 parameter sets. The first parameter set was identical in both files. The test was repeated 10 times for both cases. The parameters and the average execution times can be seen below:
-
model.exe -p file1.mat -o output.mat : 0.877s
-
model.exe -p file2.mat@1 -o output.mat : 9.943s
For 8821 separate executions, this would mean over 22 hours extra time used only for reading and parsing parameters if the parameter sets are stored in a single block parameter file.
In our test project, we built the RSim executable for the model in the same way as in the step#2 (click steps for the original example). We also saved the default parameter set for the model into .mat file as in the step #3 of the original example. The steps #4, #5, #6 and #7 we replaced with our own implementation:
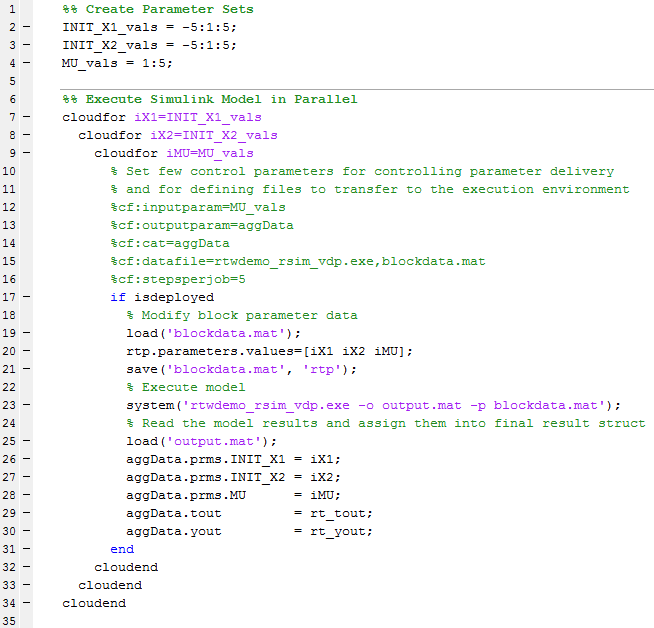
As you can see, we modified the original parameter set to include also MU values from 1 to 5. This makes the computation five times heavier. The cloudfor syntax used in the computation is part of Techila’s toolbox for MATLAB. The code inside cloudfor block is automatically distributed to the configured computation environment. It is possible to use also perfectly nested cloudfor structures. In perfectly nested for-loops, all content is inside the innermost for-loop as in the code above.
The number of different parameter sets in this example is 605. But because this model was very simple and fast to execute, five different parameter sets were set to be executed in each computational job. This was done using the configuration parameters %cf:stepsperjob=5 in the third cloudfor. So, the actual number of computational jobs was 121.
For the computation power, 2 x 32 CPU core instances were started in a public cloud platform. The Techila Distributed Computing Engine solution configured the instances automatically to support Simulink computing. The startup of the simulation and visualization happened on MATLAB that was running on a local desktop machine. Techila offloaded the computational workload seamlessly to the cloud instances and returned the results for local post-processing.
With this computational capacity we were able to speed-up this simple model with given parameter set from 2.5 minutes into 6 seconds.
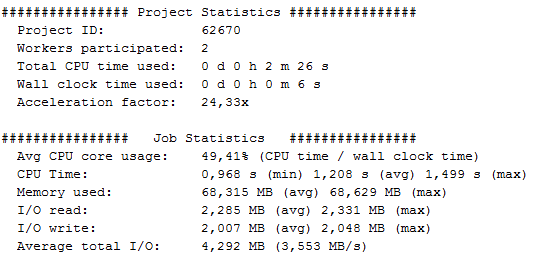
As we can see in the statistics, in this relatively simple model, even after combining multiple parameter sets into each computational job, the length of a single job was still extremely small, being about one second. This combined with the Simulink startup delays made the average CPU core usage stay under 50% and therefore the speedup acceleration factor also stayed much lower than the number of CPU cores.
When using Techila to speed up simulation of more demanding models, the CPU core utilization gets near to 100% and the acceleration factor can be very near to the actual number of CPU cores. Using Techila in the simulation of an accurate realistic model that uses a large data set can enable cutting computing times from weeks and days to hours or minutes.
For the post-processing we used again the code from the original example.
8. Troubleshooting
| Q: The program I used to distribute my computations has crashed before the results had been downloaded to my computer. Is there some way I can retrieve the results of that Project? |
|---|
A: Yes. You need the Project ID of the Project that crashed. You can find out the Project ID from the Techila Web Interface in the Completed Projects tab. Results can be downloaded by linking the peach-function call to the Project ID number. The syntax for this is provided in the programming specific examples in the Techila SDK. |
| Q: The computations are generating an error: "Native execution returned with exitcode: "-===== (0xC===5)." or "Error in creating process: ===" What’s wrong? |
|---|
A: 0xC===5 is a Windows exception code "Access Violation". Usually this has to do with a missing DLL-library, especially Microsoft Runtime libraries. The ===error message indicates that something is missing from the Windows side-by-side DLL-storage. |
| Q: Computations on a Windows Techila Worker is generating some other cryptic error message which is hard to interpret. Where can I find more information? |
|---|
A: Microsoft provides a list that contains a lot of error codes and also provides explanations on what might be causing them. The list can be found from: http://msdn.microsoft.com/en-us/library/ms681381.aspx. These codes can also be used to interpret error codes starting with 0xC==by removing the 0xC==and converting the remaining part to decimal representation. E.g. 0xC===5 → === → 5 = "Access is denied" |
| Q: The computations are generating a cryptic error message: "getModule failed: fi.techila.grid.Project.handler.base.ProjectException: Unable to resolve all the prerequisities: ava.lang.Exception: java.lang.Exception: java.lang.Exception: Exception thrown when invoking Bundles:get([==, abc, === Windows XP, x86]) called by ==: java.lang.Exception: java.lang.Exception: Unknown Bundle: abc:===Windows%XP, x86)" Whats wrong? |
|---|
A: The Bundle required by the computations is not available for that specific platform. The error message shows which Bundle is being requested and which operating system the Techila Worker is the requesting the Bundle for. In the example used here, the Bundle abc:===is not available for 32-bit Windows XP operating system. |
| Q: The computations are generating an error: "My Own Exception: Fatal error loading library …\\jar0\\x86\\Windows\\v==\bin\\win32\\mclmcr.dll Error: This application has failed to start because the application configuration is incorrect. Reinstalling the application may fix this problem." What’s wrong? |
|---|
A: The Microsoft Runtime libraries on the Techila Worker are obsolete. One possible solution is to install a newer version of the Microsoft Runtime Libraries on the Techila Worker. |
| Q: Why are my computations are generating a cryptic Exception -error. |
|---|
A: This is likely caused by an error state in the Techila Distributed Computing Engine environment as a result of which the Techila Worker in question has been removed from the Project. If the error reoccurs on the same Techila Worker, try reinstalling the Techila Worker. If the error is occurring on all Techila Workers, it is likely that there is something wrong with the computations. |
| Q: Where can I see the errors that occurred during computations? |
|---|
A: From the status bar or from the Techila Web Interface. The errors can be found under Projects → Active/Completed/Archived/Erroneous → Project ID → Errors. Instructions on how to enable the status bar are listed in Getting Started. |
| Q: My Monte-Carlo Jobs are all generating the same results. Why is that? |
|---|
A: You have to seed the random number generator for each Job individually. This can be done for example by using the jobidx parameter. |
| Q: When connecting to the Techila Server the following Exception is thrown and connection fails: "Failed initiating session: javax.net.ssl.SSLHandshakeException: Received fatal alert: certificate_unknown" |
|---|
A: Solution: Your Techila Key (certificate) has not been assigned and/or trusted on the Techila Server. Ask the Techila administrator to assign and mark the key as trusted on the Techila Server. |
| Q: Java is not found when using DLL. |
|---|
A: Solution: Rename TechilaDLL.conf.example file in the lib directory to TechilaDLL.conf. Edit the file contents and set the JVMPATH variable to point to the |
| Q: I`m using Java 7 and getting the following error when trying to use the DLL:"The program can`t start because MSVCR100.dll is missing…". How can I fix this? |
|---|
A: The jvm.dll included with Java 7 requires MSVCR100.dll. To fix this, install a suitable redistributable package containing the necessary Microsoft Runtime Libraries. For example on a 32-bit Windows computer, installing the following package should help: http://www.microsoft.com/en-us/download/details.aspx?id=5555 |
9. Glossary
| Term | Description |
|---|---|
Bundle |
Bundles are used to store computational data in a compressed Java Archive. Different Bundles are used to store different types of data. |
CPU |
A Central Processing Unit on a Techila Worker. A Central Processing Unit can contain several cores. |
CPU Core |
A core in the Central Processing Unit of a Techila Worker. By default, one Job is allocated to one core. |
End-User |
A person who has an End-User Techila Key and End-User privileges to the Techila environment. |
Job |
Smallest unit in a computational Project. Jobs are executed on Techila Workers and partial results are transferred back to the Techila Server. |
PID |
PID is an abbreviation of Project ID. See Project ID. |
Project |
A computational problem. A Project is created by the End-User and it is split into Jobs on the Techila Server. |
Project ID |
The Project Identification number. Every Project is given a unique Project Identification Number when the Project is created. |
Project Parameters |
Project parameters contain input parameters for the executable code as well as parameters that control the distribution process. |
Snapshot |
Snapshots contain intermediate results of the computations. Snapshot files are transferred to the Techila Server at regular intervals and can be used to resume computations. |
Techila Administrator |
A person who has a Techila Administrator Techila Key and administrative rights to the Techila Web Interface. |
Techila Key |
An End-User is provided an End-User Techila Key, which is used to sign the code that is transferred to the distributed computing environment. Signed code can be traced back to the End-User by the Techila Administrators. |
Techila Server |
The Techila Server manages the distributed computing environment and communicates with the End-Users program and the Techila Workers. The Server also splits the Projects into Jobs, assigns the Jobs to Techila Workers, handles the results and delivers the results back to the End-Users program. |
Techila Worker |
A Techila Worker is a computer that is connected to the Techila environment. Techila Workers provide the computational power of the distributed computing environment. By default, a single Job is assigned to a single core on the Techila Workers CPU. |