1. Introduction
This document is intended for Techila End-Users who are using Python as their main development environment. If you are unfamiliar with Techila terminology or the operating principles of the Techila system, please see Introduction to Techila Distributed Computing Engine for more information.
The structure of this document is as follows:
Introduction contains important information regarding the installation of required Python packages that enable you to use Techila with Python. This Chapter also contains a brief introduction on the naming convention of the Python-scripts and introduces the peach-function, which is used for distributing computations from Python to the Techila environment.
Python @techila Decorator contains an overview of the @techila decorators that can be used to mark functions to be executed in Techila Distributed Computing Engine (TDCE). This Chapter also contains walkthroughs of the decorator example material in the Techila SDK.
Peach Tutorial Examples contains walkthroughs of simplistic example code samples that use the peach-function. The example material illustrates how to control the core features of the peach-function, including defining input arguments for the executable function, transferring data files to the Workers and calling different functions from the Python script that is evaluated on the Worker. After examining the material in this Chapter you should be able split a simple locally executable program into two pieces of code (Local Control Code and Worker Code), which in turn can be used to perform the computations in the Techila environment.
Peach Feature Examples contains walkthroughs of several examples that illustrate how to implement different features available in the peach-function. Each subchapter in this Chapter contains a walkthrough of an executable piece of code that illustrates how to implement one or more peach-function features. Each Chapter is named according to the feature that will be the focused on. After examining the material in this Chapter you should be able implement several features available in the peach-function in your own distributed application.
Interconnect contains examples that illustrate how the Techila interconnect feature can be used to transfer data between Jobs in different scenarios. After examining the material in this Chapter, you should be able to implement Techila interconnect functionality when using the peach-function to distribute your application.
1.1. Installing the Techila Package
The techila Python package is included in the Techila SDK and contains Techila related Python functions required for creating computational Projects.
The following instructions are for Python 3.
Please follow the steps below to install and test the package.
-
Launch a command prompt / terminal
-
Change your current working directory to the following directory:
cd <full path>\techila\lib\python3
-
Install the
techilapackage using command:pip3 install --user .
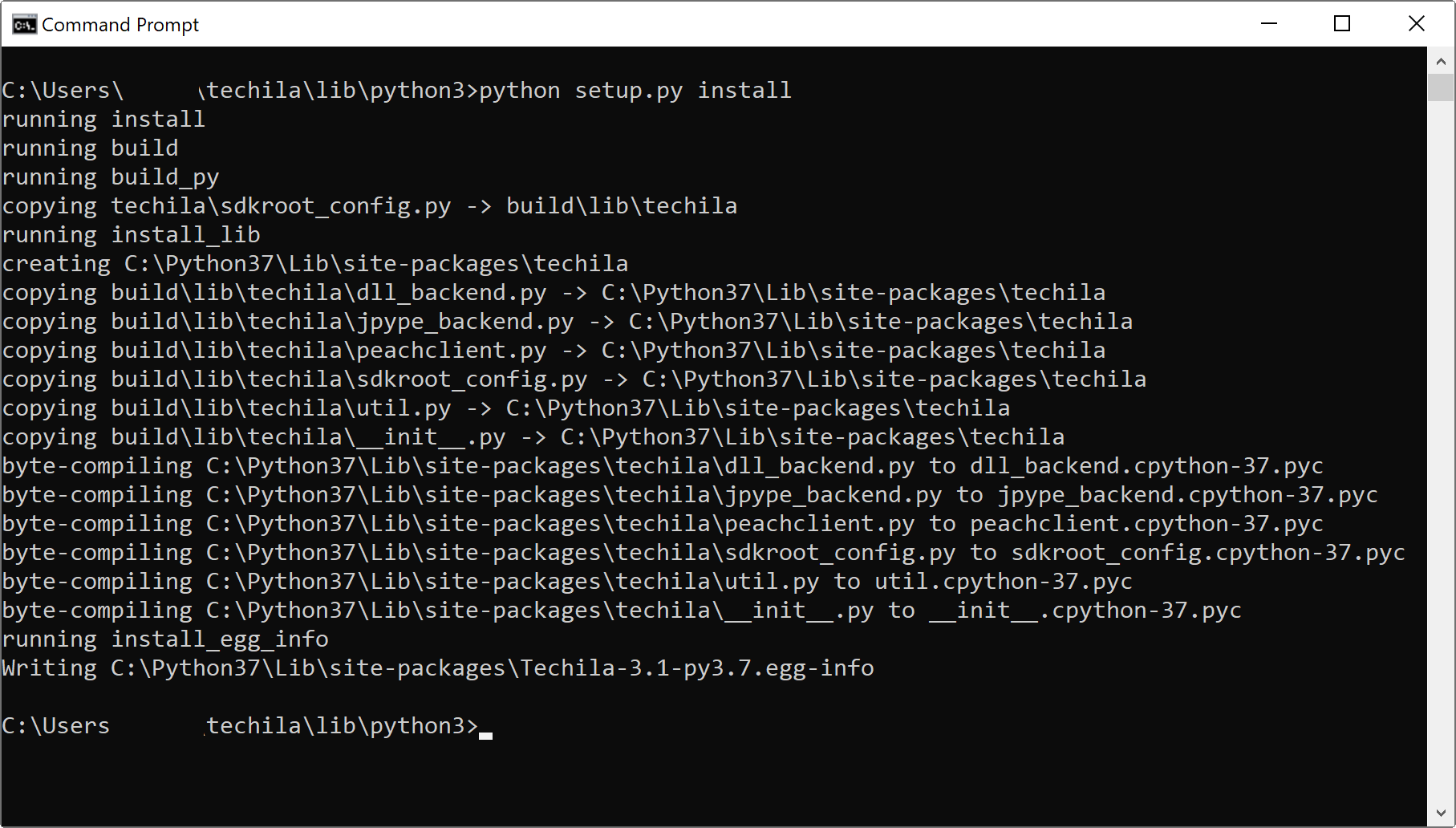 Figure 1. Installing the
Figure 1. Installing thetechilapackage.
1.2. Installing Package Dependencies
The techila package has package dependencies, which are listed in the requirements.txt file in techila/lib/python3 directory in the Techila SDK.
You can install the requirements changing your current working directory to techila/lib/python3 and by running the following pip command:
pip install -r requirements.txt
Alternatively, you can use the --user parameter to install the packages under your own user account:
pip install -r requirements.txt --user
1.3. Testing the techila Package
The following steps describe how you can test the techila package that you just installed to ensure that the network connection between the Techila SDK and the Techila Server works correctly.
-
Launch python. Note! Make sure that your current working directory is NOT the
techila/lib/python3directory. If you perform the following steps while in thetechila/lib/python3directory, thetechilapackage will not be loaded correctly. -
Test the installation by executing the following commands in python. The
techila.init()command will establish a network connection with the Techila Server and thetechila.uninit()command will terminate the connection.import techila techila.init() techila.uninit()
If prompted, enter your keystore password.
The screenshot below shows the expected output of a successful test.
Note! If you did not change your current working directory before launching python, the
techila.init()command will generate an error stating thatUnable to get sdkroot: (-1). In this case, close python, change your current working directory, and run the test again.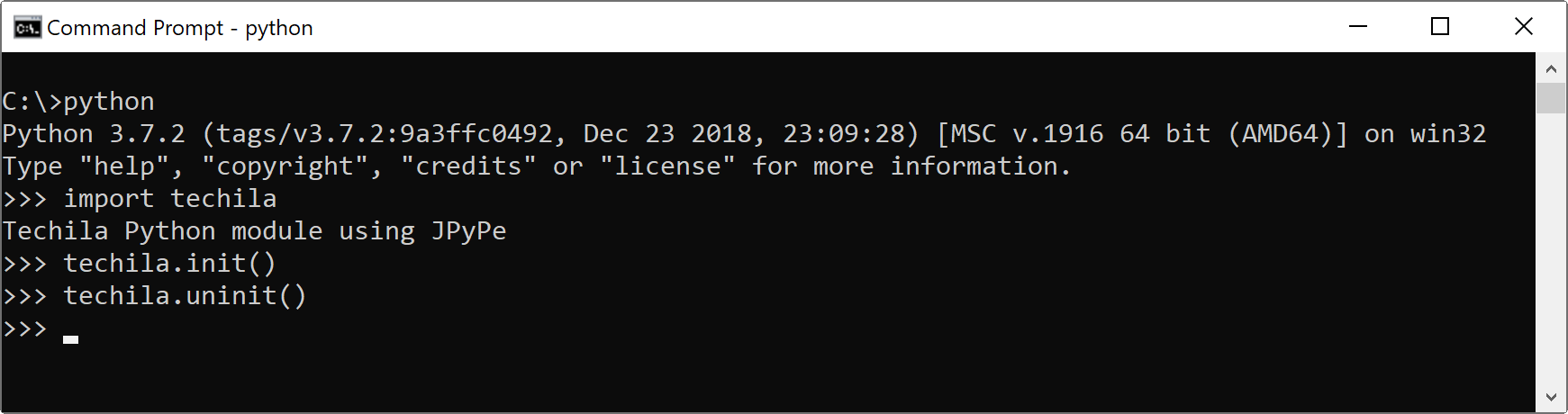 Figure 2. Testing the
Figure 2. Testing thetechilapackage.The following steps contain troubleshooting instructions for some errors that can be encountered when executing the
techila.init()function. -
If you receive an error code
-22, it means that the underlying Techila management library was not able to find the library containing the Java Virtual Machine (JVM) functionality.This problem can be fixed by specifying the location of the JVM library in the
TechilaDLL.conffile as explained below.-
Navigate to the
techila/libdirectory in the Techila SDK. Rename theTechilaDLL.conf.examplefile toTechilaDLL.conf(remove the .example suffix). -
Open the
TechilaDLL.conffile with a text editor and specify the location of your JVM library using the JVMPATH parameter. Depending on what operating system you are using, the JVM library file will be named differently as listed below:-
Windows: jvm.dll
-
Linux: libjvm.so
-
-
Save changes to the
TechilaDLL.conffile and run thetechila.init()function again. The screenshot below shows the contents of aTechilaDLL.conffile, where the location of the jvm.dll file has been set to: C:\Program Files\Java\jre1.8.0_65\bin\server\jvm.dll.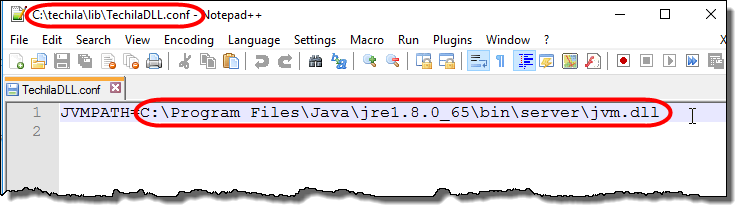 Figure 3. An example TechilaDLL.conf file on a Windows computer.
Figure 3. An example TechilaDLL.conf file on a Windows computer.
-
1.4. Example Material
The Python scripts containing the example material discussed in this document can be found in the Tutorial, Features and Interconnect folders in the Techila SDK. These folders contain subfolders, which contain the actual Python scripts that can be used to run the examples.
python folder in the Techila SDK1.4.1. Naming Convention of the Python Scripts
The typical naming convention of Python scripts presented in this document is explained below:
-
Python scripts ending with
distcontain the Worker Code, which will be distributed to the Workers when the Local Control Code is executed. -
Python scripts beginning with
run_contain the Local Control Code, which will create the computational Project when executed locally on the End-User’s own computer. -
Python scripts beginning with
local_contain locally executable code, which does not communicate with the Techila environment.
Please note that some Python scripts and functions might be named differently, depending on their role in the computational Project.
1.5. Introduction - Python @techila Decorators
As defined in the Python Wiki, a decorator is the name used for a software design pattern. Decorators dynamically alter the functionality of a function, method, or class without having to directly use subclasses or change the source code of the function being decorated.
The techila python package includes a @techila.distributable() decorator, which can be used to execute computationally intensive functions in a TDCE environment.
The code snippet below shows how you could decorate a function using @techila.distributable() and execute it in TDCE.
# The techila package includes the decorators
import techila
# Decorate the function that we want to execute in TDCE.
@techila.distributable()
def fun(x):
return x * 2
# Create a list of function calls that will be executed in TDCE.
# In this case, the list will only contain one element.
myresult = fun(21)
# Run the computations in TDCE.
techila.run()
print(type(myresult)) # this will print <class 'techila.TechilaItem'>
print(myresult) # this will print 42More information about @techila decorators can be found in Python @techila Decorator.
1.6. Introduction - Python Peach Function
The peach-function provides a simple interface that can be used to distribute Python programs or precompiled binaries. Each peach-function input argument is a named parameter, which refer to a computer language`s support for function calls that state the name of each parameter within the function call itself.
A minimalistic Python peach-function syntax typically includes the following parameters:
-
funcname
-
params
-
files
-
peachvector
-
datafiles
These parameters can be used to define input arguments for the executable function and transfer additional files to the Workers. An example of a peach-function syntax using these parameters is shown below:
techila.peach(funcname = 'example_function', # Function executed on Workers
params = [var1,var2], # Input arguments to the function
files = ['codefile.py'], # Evaluated at the start of a Job
datafiles = ['file1','file2'], # Files transferred to Workers
peachvector = [2,4,6,8,10] # Peachvector definition
)Examples and more detailed explanations of these parameters can be found in Peach Feature Examples. General information on available peach-function parameters can also be displayed by executing the following commands in Python.
import techila
help(techila.peach)1.7. Process Flow in Computational Projects
When a Project is created with the peach-function, each Job in a computational Project will have a separate Python session. When a Job is started on a Worker, functions and variables are loaded by evaluating the Python script that was defined in the files parameter and by loading the parameters stored in the techila_peach_inputdata file. These parameters will include the parameters defined in the params peach-function parameter.
When a Job is started on a Worker, the peachclient.py script (included in the techila package) is called. The peachclient.py file is a Python script that acts as a wrapper for the Worker Code and is responsible for calling the executable function, passing input arguments to the function and returning the final computational results. This functionality is hidden from the End-User. The peachclient.py will be used automatically in computational Projects created with peach-function.
The peachclient.py wrapper also sets a preliminary seed for the random number generator by using the Python seed() function from the package random. Each Job in a computational Project will receive a unique random number seed based on the current system time and the jobidx parameter, which will be different for each Job. The preliminary random number seeding can be overridden by calling the seed() function in the Worker Code with the desired random seed.
1.7.1. Process Flow When Using Peach Function
The list below contains some of the Python specific activities that are performed automatically when the peach-function is used to create a computational Project.
-
The peach-function is called locally on the End-Users computer
-
Python scripts listed in the
filesparameter are transferred to Workers -
Files listed in the
datafilesparameter are transferred to Workers -
The
peachclient.pyfile is transferred to Workers -
Input parameters listed in the
paramsparameter are stored in a file calledtechila_peach_inputdata, which is transferred to Workers. -
Optional files listed in the
filesanddatafilesparameters and the filestechila_peach_inputdataandpeachclient.pyare copied to the temporary working directory on the Worker -
The
peachclient.pywrapper is called on the Worker. -
Variables stored in the file
techila_peach_inputdataare loaded -
Files listed in the
filesparameter are imported using Pythonfrom <filename> import *command. The<filename>notation will be replaced with values defined infilesparameter, without the file suffix (.py). -
The
<param>notation is replaced with apeachvectorelement -
The peachclient calls the function defined in the
funcnameparameter with the input parameters defined inparams -
The peachclient saves the result in to a file, which is returned from the Worker to the End-User
-
The peach-function reads the output file and stores the result in a list element (If a callback function is used, the result of the callback function is returned).
-
The entire list is returned by the peach-function.
1.7.2. Process Flow When Using @techila Decorators
The list below contains some of the Python specific activities that are performed when the @techila.distributable() is used to create a computational Project.
-
Decorate the function that you want to execute in TDCE using
@techila.distributable() -
Call the decorated function. This will store the function call and the input arguments in to an internal list as a
TechilaItemobject. This means the original function is not executed at this point. This call returns theTechilaItemobject and is a placeholder for the results. -
Repeat the previous step as many times as applicable in your use-case.
-
Call the
techila.run()function. -
Create a
peachvectorbased on the internal list created earlier. -
The peach-function is called locally on the End-Users computer. The operations following this are similar to the ones descibed above and the original function is executed on Techila Workers with the input arguments.
-
Results are streamed to End-User’s computer and the
TechilaItem.resultdata is updated to contain the result.
1.8. Techila Environment Variables
The table below contains descriptions of environment variables used by the Techila SDK on the End-User`s computer. These environment variables can be used to define e.g. the path of the Techila SDK`s techila directory on your computer or to define the version of Python runtime components used during computational Projects.
| Environment variable | Description | Example value |
|---|---|---|
TECHILA_SDKROOT |
Defines the path of the root directory of the Techila SDK. |
C:\techila |
TECHILA_PYTHON_VERSION |
Defines the Python Runtime Bundle version that will be used in Projects. This parameter can be used e.g. if the Techila environment does not have a Python Runtime Bundle with the same version as your local Python environment. The version of the Runtime Bundle is defined using the syntax <major><minor><micro>. (As returned by command |
273 |
TECHILA_PYTHON_BACKEND |
Can be used to specify which backend is used when processing Techila SDK commands on the End-User’s computer. Available backends are 'jpype' and 'dll'. Values are case sensitive. |
dll |
2. Conda-Pack Support
conda-pack is a tool for creating archives of conda environments that can be transferred and installed on other systems and locations. Techila SDK includes helper functions that utilize conda-pack to transfer conda environments to Techila Workers and to run computational code in the environments.
Running code using conda environments consists of the following two steps:
-
Creating a bundle:
techila.create_conda_bundle(bundlename='unique_string') -
Running your parallelized code:
techila.peach_conda(<paramereters>)
The steps below contain a more detailed walkthrough on how to create a new conda test environment, transfer it to a Techila Worker and execute code in the environment. Similar steps can be applied to transfer conda environments you are using to run your code.
-
Create and activate the env
conda create --name demoenv conda activate demoenv
-
Cd into
techila\lib\python3and install thetechilapackage and the requirements.conda install cloudpickle conda install jpype1 pip install .
-
Install
conda-packconda install conda-pack
-
Start python and run the code shown below.
The code will create a bundle from the currently active conda environment, transfer it to the Techila Workers and run the
funfunction in the environment. The version information will be returned from the TDCE environment and printed after the project has been completed and should match the versions you are using locally. You can apply a similar approach of usingtechila.create_conda_bundleandtechila.peach_condacalls in your own code to run computationally intensive functions on Techila Workers.If you make changes to your conda environment, you can force the system to create a new bundle by giving the bundle a new name by using the
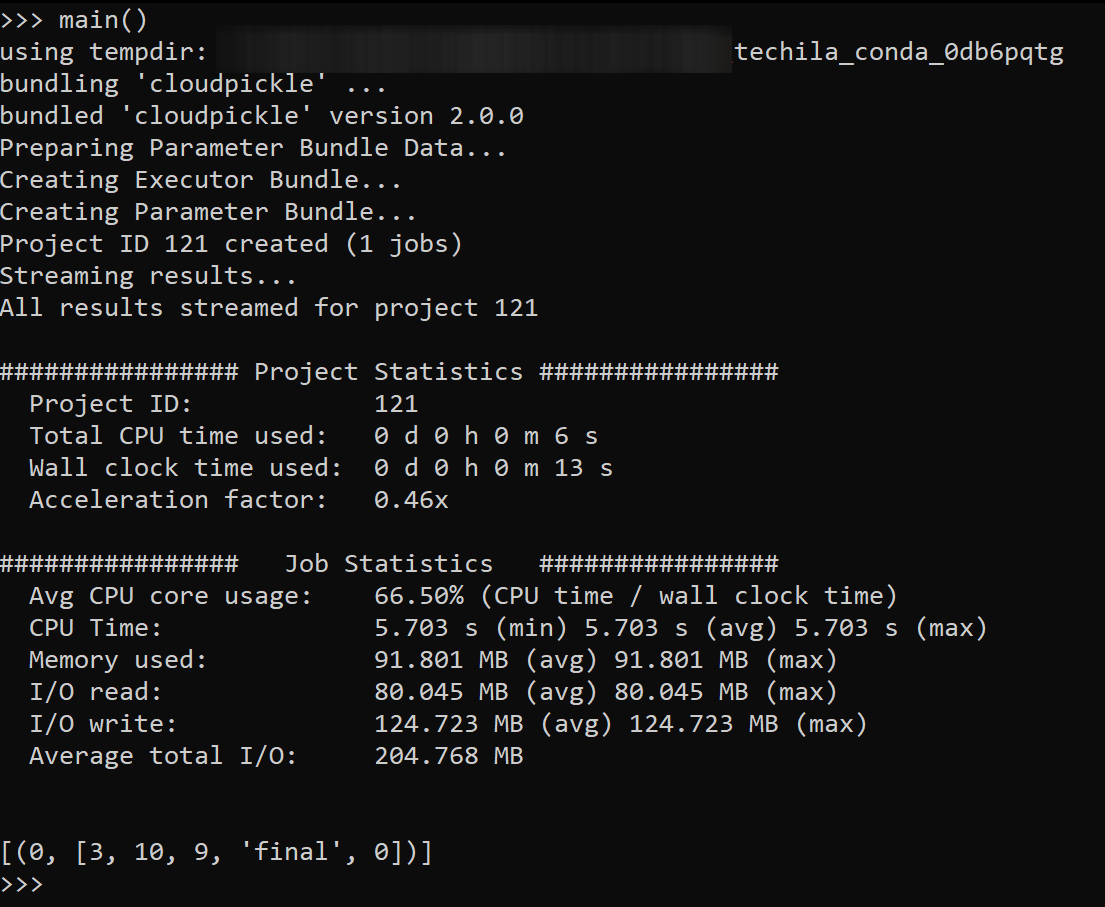
conda_bundleparameter.import sys import techila def fun(x): ver = list(sys.version_info) return (x, ver) def main(): # change the bundle name when conda env is changed. bundlename = "my_test_env_v1" techila.create_conda_bundle(bundlename=bundlename) result = techila.peach_conda( conda_bundle=bundlename, funcname=fun, params=["<param>"], peachvector=range(1), stream=True, ) print(result) main()The screenshot below illustrates what the output of the example should look like. Exact versions and paths will most likely differ in your environment.
3. Python @techila Decorator
This Chapter starts with an Overview of the @techila decorators, which contains code snippets that illustrate how decorators can be used to perform computations in TDCE.
If you are intersted in running the example material included in the Techila SDK, walkthroughs of the example material start from the following Chapter: Example 1 - Running Your First Decorated Function in TDCE.
Please note that the example material in this Chapter is only intended to illustrate the core mechanics related to distributing computation with the @techila decorators. The operations performed may be computationally trivial, but will illustrate how various features and operations can be performed in TDCE.
3.1. Overview
The techila python package includes a @techila.distributable() decorator, which can be used to execute computationally intensive functions in a TDCE environment. In order to decorate functions, you will need to import the techila package.
# The techila package includes the decorators
import techilaAfter the techila package has been imported, you can decorate the function that you want to execute in TDCE by using the techila.distributable() decorator.
# Decorate the function that you want to execute in TDCE.
@techila.distributable()
def fun(x):
return x * 2After decorating the function, calling the function will no longer execute it on your computer, but will instead create a TechilaItem object that contains the fun function call and values of the input arguments (x in this case).
res = fun(10) # Res will contain a TechilaItem object.The actual fun function call can be performed in TDCE by calling the techila.run() command:
techila.run() # This runs function call stored in TDCEAfter the command has been executed, the res variable created earlier will contain a modified TechilaItem object, which contains the result returned by fun.
print(res) # This would print 20, as 10 * 2 = 20.The following Chapters contain small code snippets that illustrate how decorators can be used. Walkthroughs of Techila SDK example material start from Chapter Example 1 - Running Your First Decorated Function in TDCE.
3.1.1. Executing one function once in TDCE
The code snippet below shows how you could decorate a function named fun using @techila.distributable() and execute the fun function in TDCE.
If you want, you can copy-paste the code snippet below to your Python environment and run it in your own TDCE environment.
# The techila package includes the decorators
import techila
# Decorate the function that we want to execute in TDCE.
@techila.distributable()
def fun(x):
return x * 2
# Create a list of function calls that will be executed in TDCE.
# In this case, the list will only contain one element.
myresult = fun(21)
# This will print <class 'techila.TechilaItem'>
print(type(myresult))
# At this point, this will print None, as the function has not
# yet been executed in TDCE.
print(myresult)
# Run the computations in TDCE. This will execute function 'fun' once in TDCE.
techila.run()
print(type(myresult)) # This will still <class 'techila.TechilaItem'>
print(myresult) # This will now print 42
myresult_final = myresult.result # Get the result value of the computations.
print(type(myresult)) # This will print <type 'int'>3.1.2. Executing one function several times in TDCE
Each call to a decorated function will append the function with its arguments to a list that will be executed in TDCE during a Project when techila.run() is called. This means that by calling the decorated function multiple times you can create a list of functions that will be executed in TDCE simultaneously.
For example, the following code snippet could be used to define a list of 4 function calls and execute each function simultaneously with different input arguments in the TDCE environment.
If you want, you can copy-paste the code snippet below to your Python environment and run it in your own TDCE environment.
# The techila package includes the decorators
import techila
# Decorate the function that we want to execute in TDCE.
@techila.distributable()
def fun(x):
return x * 2
# Create a list of function calls that will be executed in TDCE.
# In this case, the list will only contain one element.
myresult1 = fun(21)
myresult2 = fun(22)
myresult3 = fun(23)
myresult4 = fun(24)
# Run the computations in TDCE. The Project would contain 4 Jobs.
# Each Job would execute the function once, with a different input
# argument value.
techila.run()
print(myresult1) # this will print 42
print(myresult2) # this will print 44
print(myresult3) # this will print 46
print(myresult4) # this will print 483.1.3. Decorating functions using a for loop.
You can build the list of function calls in a more efficient manner by using, for example, a for loop. The following example syntax could be used to create a list of 100 function calls and execute them in the TDCE environment.
If you want, you can copy-paste the code snippet below to your Python environment and run it in your own TDCE environment.
# The techila package includes the decorators
import techila
# Decorate the function that we want to execute in TDCE.
@techila.distributable()
def fun(x):
return x * 2
# Create a list of function calls that will be executed in TDCE.
# In this case, the list will only contain 100 elements.
results = []
for x in range(100):
results.append(fun(x))
# Run the computations in TDCE.
# The Project would contain 100 Jobs, each executing the function once.
techila.run()
print(results[0]) # This prints 0
print(results[99]) # This prints 1983.1.4. Executing a function multiple times in each Job.
By default, each Job executes the function once. However, by using the steps parameter, you can specify that each Job should execute the function multiple times. Grouping function calls can improve performance in situations where one function call takes a relatively short time, but you have a very large range of input arguments to process.
For example, the following syntax could be used to specify that each Job should perform 50 function executions.
techila.run(steps=50) # Each Job performs 50 function calls.The code snippet below illustrates the use of this parameter.
If you want, you can copy-paste the code snippet below to your Python environment and run it in your own TDCE environment.
# The techila package includes the decorators
import techila
# Decorate the function that we want to execute in TDCE.
@techila.distributable()
def fun(x):
return x * 2
# Create a list of function calls that will be executed in TDCE.
# In this case, the list will only contain 100 elements.
results = []
for x in range(100):
results.append(fun(x))
# Run the computations in TDCE.
# The Project would contain 2 Jobs, each Job executing the function 50 times.
techila.run(steps=50)
print(results[0]) # This prints 0
print(results[99]) # This prints 1983.1.5. Decorating functions using perfectly nested for loops.
In situations where your computationally intensive function is located inside multiple, perfectly nested for loops, you can follow the same approach to decorate the function.
The following example syntax could be used to create a list of 10000 function calls and execute them in the TDCE environment.
If you want, you can copy-paste the code snippet below to your Python environment and run it in your own TDCE environment.
# The techila package includes the decorators
import techila
# Decorate the function that we want to execute in TDCE.
@techila.distributable()
def fun(x):
return x * 2
# Create a list of function calls that will be executed in TDCE.
# In this case, the list will only contain 100 elements.
results = []
for x in range(100):
for y in range(100):
results.append(fun(x*y))
# Run the computations in TDCE.
# The Project would contain 10 Jobs, each executing the function 1000 times.
techila.run(steps=1000)
print(results[0]) # This prints 0
print(results[9999]) # This prints 196023.1.6. Executing different functions in different Jobs.
By decorating different functions, you can execute different functions in different Jobs inside one Project that is executed in TDCE.
For example, the following syntax could be used to create a list of 4 function calls and execute them in the TDCE environment. Two Jobs would execute fun and the remaining two Jobs would execute fun2
If you want, you can copy-paste the code snippet below to your Python environment and run it in your own TDCE environment.
# The techila package includes the decorators
import techila
# Decorate the function that we want to execute in TDCE.
@techila.distributable()
def fun(x):
return x * 2
# Decorate the function that we want to execute in TDCE.
@techila.distributable()
def fun2(x):
return x * 10
# Create a list of function calls that will be executed in TDCE.
# In this case, the list will only contain 100 elements.
res1 = fun(1)
res2 = fun(2)
res3 = fun2(1)
res4 = fun2(2)
# Run the computations in TDCE. The Project would contain 4 Jobs,
# each executing a function once. Jobs 1-2 would execute fun and
# Jobs 3-4 would execute fun2.
techila.run()
print(res1) # This prints 2
print(res2) # This prints 4
print(res3) # This prints 10
print(res4) # This prints 203.1.7. Returning various data types
Result data returned from the TDCE environment can be stored in variables defined in the function call. The following code snippet shows how you could return numpy data types from TDCE to your computer.
If you want, you can copy-paste the code snippet below to your Python environment and run it in your own TDCE environment.
# The techila package includes the decorators
import techila
# Decorate the function that we want to execute in TDCE.
@techila.distributable()
def fun(x):
import numpy as np
return np.random.random(x)
# Create a list of function calls that will be executed in TDCE.
# In this case, the list will only contain elements
res = fun(2)
# Run the computations in TDCE. The Project would contain 1 Job,
# which executes the function once.
techila.run()
# At this point, results contains TechilaItem-objects.
print(type(res))
# Get the values using a for loop.
final_result = res.resultThe example code snippet below shows how you can execute the same function multiple times in TDCE and return a numpy data type from each Job.
If you want, you can copy-paste the code snippet below to your Python environment and run it in your own TDCE environment.
# The techila package includes the decorators.
import techila
import numpy as np
# Decorate the function that we want to execute in TDCE.
@techila.distributable()
def fun(x):
import numpy as np
return np.random.random(x) # Returns numpy data
# Create an empty numpy array.
results = np.array([])
for x in range(10):
results = np.append(results,fun(1))
# Run the computations in TDCE. The Project would contain 10 Job,
# which executes the function once.
techila.run()
# At this point, results contains TechilaItem-objects.
print(type(results[0]))
# Get the values using a for loop.
final_results = [x.result for x in results]3.2. Example 1 - Running Your First Decorated Function in TDCE
The purpose of this example is to:
-
Demonstrate how to modify a simple, locally executable Python script so that the computational operations will be performed in TDCE.
-
Demonstrate the basic syntax of the
@techila.distributable()decorator
The material discussed in this example is located in the following folder in the Techila SDK:
-
techila\examples\python\decorator\1_distribution
3.2.1. Local Version
The Python script local_function.py containing the locally executable version is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_decorator_1_distribution
# Copyright Techila Technologies Ltd.
# This file contains the locally executable function, which can be
# executed on the End-Users computer. This function does not
# communicate with the Techila environment.
#
# Usage:
# result = local_function(x)
# x: the number of iterations in the for loop.
#
# Example:
# result = local_function(5)
def fun():
return 1 + 1
def local_function(x):
result = []
for i in range(x):
result.append(fun())
return resultThe file contains two function definitions:
-
local_function- Used to run the example on your computer. Contains oneforloop, which executesfunduring each iteration. -
fun- Performs a simple summation operation: 1+1. In this version, the summation operation will be performed locally.
All operations in this example will be executed locally. In the Distributed Version, the fun function will be decorated, which means it will be executed in TDCE.
3.2.2. Distributed Version
The Python script run_distribution.py containing the distributed version is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_decorator_1_distribution
# Copyright Techila Technologies Ltd.
# This file contains the Local Control Code, which will create the
# computational Project. It also contains the function that will be
# executed during computational Jobs. Each Job will perfom the same
# computational operations: calculating 1 + 1.
#
# Usage:
# result = run_distribution(jobcount)
#
# jobcount: number of Jobs in the Project
#
# Example:
# result = run_distribution(5)
import techila
@techila.distributable()
def fun():
return 1 + 1
def run_distribution(x):
result = []
for i in range(x):
result.append(fun())
techila.run()
return resultThe file contains two function definitions:
-
run_distribution- Used to run the example on your computer. Contains oneforloop, which executes the decoratedfunduring each iteration. -
fun- A function decorated with the@techila.distributable()decorator. This means thatfunwill be executed in TDCE, not on your computer.
When the run_distribution function is executed, the for loop will execute the decorated fun function. Each time the decorated function is executed, a TechilaItem object will be returned and stored in a list. This means that after the for loop has been completed, the result list will contain multiple TechilaItem objects.
For example, if x=5, the result list will contain 5 TechilaItem objects.
When the code reaches the techila.run() command, a computational Project will be created. The number of Jobs in the Project will be equal to the amount of TechilaItem objects. For example, if there are 5 TechilaItem objects, the Project will consist of 5 Jobs.
Each Job will execute the fun function and return the result of the summation operation (1+1) as the result. These results will be automatically streamed to the End-User’s computer and stored in the result list.
After the Project has been completed, the result list will contain 5 TechilaItem objects. Each TechilaItem object contains a result member variable, which contains the result of the summation operation. The example syntaxes shown below illustrate how you could retrieve these values.
res1 = result[0].result # Result of Job #1
res5 = result[4].result # Result of Job #53.2.3. Running the Examples
The files needed to run this example are located in the following Techila SDK directory:
-
techila\examples\python\decorator\1_distribution
To run the local version, change your current working directory to the directory containing the example material and execute the following commands:
from local_function import *
local_function(5)To run the distributed version, change your current working directory to the directory containing the example material and execute the following commands:
from run_distribution import *
run_distribution(5)3.3. Example 2 - Passing Input Arguments
The purpose of this example is to:
-
Demonstrate how to pass input arguments to the execututable function when using the
@techila.distributable()decorator.
The material discussed in this example is located in the following folder in the Techila SDK:
-
techila\examples\python\decorator\2_parameters
3.3.1. Local Version
The Python script local_function.py containing the locally executable version is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_decorator_2_parameters
# Copyright Techila Technologies Ltd.
# This function contains the locally executable function, which
# can be executed on the End-Users computer. This function
# does not communicate with the Techila environment.
#
# Usage:
# result = local_function(multip, loops)
# multip: value of the multiplicator
# loops: the number of iterations in the 'for' loop.
#
# Example:
# result = local_function(2, 5)
def fun(multip, x):
return multip * x
def local_function(multip, loops):
result = []
for x in range(1, loops + 1):
result.append(fun(multip, x))
print(result)
return(result)The file contains two function definitions:
-
local_function- Used to run the example on your computer. Contains oneforloop, which executesfunduring each iteration. -
fun- Performs a simple arithmetic operation that multiplies the input arguments given tofun. In this version, the multiplication operation will be performed locally.
All operations in this example will be executed locally, each iteration multiplying different values. In the Distributed Version, the fun function will be decorated, which means it will be executed in TDCE using a set of different input arguments for each Job.
3.3.2. Distributed Version
The Python script run_parameters.py containing the distributed version is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_decorator_2_parameters
# Copyright Techila Technologies Ltd.
# This function contains the Local Control Code, which will create the
# computational Project. It also contains the function that will be
# executed during computational Jobs. Each Job will multiply the
# values of the two input arguments, 'multip' and 'x'. 'multip'
# will be same for all Jobs, 'x' will receive a different
# value for each call.
#
# Usage:
# result = run_parameters(multip, jobs)
# multip: value of the multiplicator
# jobs: the number of iterations in the 'for' loop.
#
# Example:
# result = run_parameters(2, 5)
import techila
@techila.distributable()
def fun(multip, x):
return multip * x
def run_parameters(multip, loops):
result = []
for x in range(1, loops + 1):
result.append(fun(multip, x))
techila.run()
print(result)
return(result)The file contains two function definitions:
-
run_parameters- Used to run the example on your computer. Contains oneforloop, which executes the decoratedfunduring each iteration. -
fun- A function decorated with the@techila.distributable()decorator. This means thatfunwill be executed in TDCE, not on your computer. Each function call will have a different set of input arguments.
When the run_parameters function is executed, the for loop will execute the decorated fun function. Each time the decorated function is executed, a TechilaItem object will be returned and stored in a list. This TechilaItem will also include the values of the input arguments multip and x. This means that after the for loop has been completed, the result list will contain multiple TechilaItem objects, with different sets of input arguments
For example, if loops=5 and multip=2, the result list will contain 5 TechilaItem objects with the following input arguments.
| TechilaItem # | Value of multip | value of x |
|---|---|---|
1 |
2 |
1 |
2 |
2 |
2 |
3 |
2 |
3 |
4 |
2 |
4 |
5 |
2 |
5 |
When the code reaches the techila.run() command, a computational Project will be created. The number of Jobs in the Project will be equal to the amount of TechilaItem objects. For example, if there are 5 TechilaItem objects, the Project will consist of 5 Jobs.
Each Job will execute the fun function and return the result of the multiplication operation as the result. These results will be automatically streamed to the End-User’s computer and stored in the result list.
Assuming values loops=5 and multip=2 are used to run the example, the Jobs will perform the following operations.
| Job # | Operation performed | Result returned |
|---|---|---|
1 |
2 * 1 |
2 |
2 |
2 * 2 |
4 |
3 |
2 * 3 |
6 |
4 |
2 * 4 |
8 |
5 |
2 * 5 |
10 |
After the Project has been completed, the result list will contain 5 TechilaItem objects. Each TechilaItem object contains a result member variable, which contains the result of the multiplication operation. The example syntaxes shown below illustrate how you could retrieve these values.
res1 = result[0].result # Result of Job #1
res5 = result[4].result # Result of Job #53.3.3. Running the Examples
The files needed to run this example are located in the following Techila SDK directory:
-
techila\examples\python\decorator\2_parameters
To run the local version, change your current working directory to the directory containing the example material and execute the following commands:
from local_function import *
local_function(2,5)To run the distributed version, change your current working directory to the directory containing the example material and execute the following commands:
from run_parameters import *
run_parameters(2,5)3.4. Example 3 - Using Datafiles
The purpose of this example is to:
-
Demonstrate how data files can be transferred from your computer to the TDCE environment when using the
@techila.distributable()decorator.
The material discussed in this example is located in the following folder in the Techila SDK:
-
techila\examples\python\decorator\3_datafiles
3.4.1. Local Version
The Python script local_function.py containing the locally executable version is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_decorator_3_datafiles
# Copyright Techila Technologies Ltd.
# This function contains the locally executable function, which can be
# executed on the End-Users computer. This function does not
# communicate with the Techila environment.
#
# Usage:
# result = local_function()
# Import the csv package
import csv
def fun(filename, idx):
# Read the file from the current working directory
rows = list(csv.reader(open('datafile.txt', 'r'), delimiter=' '))
row_int = map(int, rows[idx]) # Convert the values to integers
sum_row_int = sum(row_int) # Sum the integers
return sum_row_int
def local_function():
# Create empty list for results
contents = []
for idx in range(4): # For each row
contents.append(fun('datafile.txt', idx))
print('Sums of rows: ', contents) # Display the sums
return(contents) # Return list containing summation resultsThe file contains two function definitions:
-
local_function- Used to run the example on your computer. Contains oneforloop, which executesfunduring each iteration. -
fun- Reads data from a local file calleddatafile.txtand sums the values on a specific row as determined by the value of the loop counter index. Each iteration sums the values on a different row.
All operations in this example will be executed locally. In the Distributed Version, the fun function will be decorated, which means the file datafile.txt will be transferred to TDCE and accessed on Techila Workers.
3.4.2. Distributed Version
The Python script run_datafiles.py containing the distributed version is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_decorator_3_datafiles
# Copyright Techila Technologies Ltd.
# This function contains the Local Control Code, which will create the
# computational Project. It also contains the function that will be
# executed during computational Jobs. Each Job will sum the values in
# a specific row in the file 'datafile.txt' and return the value as
# the output.
# Import the csv package
import csv
import techila
@techila.distributable()
def fun(filename, idx):
# Read the file from the current working directory
rows = list(csv.reader(open('datafile.txt', 'r'), delimiter=' '))
row_int = map(int, rows[idx]) # Convert the values to integers
sum_row_int = sum(row_int) # Sum the integers
return sum_row_int
def run_datafiles():
# Create empty list for results
contents = []
for idx in range(4): # For each row
contents.append(fun('datafile.txt', idx))
techila.run(datafiles=['datafile.txt'])
print('Sums of rows: ', contents) # Display the sums
return(contents) # Return list containing summation resultsThe file contains two function definitions:
-
run_datafiles- Used to run the example on your computer. Contains oneforloop, which executes the decoratedfunduring each iteration. -
fun- A function decorated with the@techila.distributable()decorator. This means thatfunwill be executed in TDCE, not on your computer.
When the run_datafiles function is executed, the for loop will execute the decorated fun function. Each time the decorated function is executed, a TechilaItem object will be returned and stored in a list. This TechilaItem object will contain the function call to the original function fun, meaning the file datafile.txt will need to be available on the Techila Workers when the function is executed.
When the code reaches the techila.run(datafiles=['datafile.txt']) command, a computational Project will be created. The datafiles parameter is used to transfer the file datafile.txt from the current working directory on your computer to the Techila Workers. After the file has been transferred to the Techila Workers, it will be stored in the same temporary working directory that is used to execute the Job.
Each Job will then run fun function and will read the file from the current working directory on the Techila Worker. This means that the same syntax can be used to read the file on the Techila Worker as was used in the local version.
# File read operation performed on Techila Workers.
rows = list(csv.reader(open('datafile.txt', 'r'), delimiter=' '))After the Project has been completed, the result list will contain 5 TechilaItem objects. Each TechilaItem object contains a result member variable, which contains the result of the summation operation. The example syntaxes shown below illustrate how you could retrieve these values.
res1 = result[0].result # Result of Job #1
res5 = result[4].result # Result of Job #53.4.3. Running the Examples
The files needed to run this example are located in the following Techila SDK directory:
-
techila\examples\python\decorator\3_datafiles
To run the local version, change your current working directory to the directory containing the example material and execute the following commands:
from local_function import *
local_function()To run the distributed version, change your current working directory to the directory containing the example material and execute the following commands:
from run_datafiles import *
run_datafiles()3.5. Example 4 - Running Different Functions
The purpose of this example is to illustrate how you can execute different functions in different Jobs in a single Project.
The material discussed in this example is located in the following folder in the Techila SDK:
-
techila\examples\python\decorator\4_multiplefunction
3.5.1. Local Version
The Python script local_multiple_functions.py containing the locally executable version is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_decorator_4_multiplefunction
# Copyright Techila Technologies Ltd.
# This Python-script contains two locally executable functions, which
# can be executed on the End-Users computer. These functions
# do not communicate with the Techila environment.
#
# Usage:
# result = local_multi_function()
def function1():
# When called, this function will return the value 2.
return(1 + 1)
def function2():
# When called, this function will return the value 100.
return(10 * 10)
def local_multi_function():
results = []
for i in range(4):
if i == 0:
res = function1()
else:
res = function2()
results.append(res)
return resultsThe file contains 3 function definitions:
-
local_multiple_functions- Used to run the example on your computer. Contains oneforloop, which executesfunction1during the first iteration andfunction2during all other iterations. -
function1- Performs a simple summation operation. -
function2- Performs a simple multiplication operation.
All operations in this example will be executed locally. In the Distributed Version, functions function1 and function2 will be decorated, and will be executed in TDCE.
3.5.2. Distributed Version
The Python script run_multi_function.py containing the distributed version is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_decorator_4_multiplefunction
# Copyright Techila Technologies Ltd.
# This function contains the Local Control Code, which will create the
# computational Project. It also defines the two functions that will
# be run in a computational job. First job will run the first function
# and the other jobs will run the second function.
#
# Usage:
# result = run_multi_function()
import techila
@techila.distributable()
def function1():
# When called, this function will return the value 2.
return(1 + 1)
@techila.distributable()
def function2():
# When called, this function will return the value 100.
return(10 * 10)
def run_multi_function():
results = []
for i in range(4):
if i == 0:
res = function1()
else:
res = function2()
results.append(res)
techila.run()
return resultsThe file contains 3 function definitions:
-
run_multi_function- Used to run the example on your computer. Contains oneforloop, which executes the decorated functionfunction1during the first iteration andfunction2during all other iterations. -
function1- A function decorated with the@techila.distributable()decorator. -
function2- A function decorated with the@techila.distributable()decorator.
When the run_multi_function function is executed, the for loop will execute function1 during the first iteration of the for loop, meaning the first TechilaItem object will contain a call to function1. As function2 will be executed during all other iterations, all other TechilaItem objects will contain a call to function2.
When techila.run() is executed, a computational Project will be created. Function function1 will be executed during Job #1 and function2 in all other Jobs (Job #2 - Job #N).
3.5.3. Running the Examples
The files needed to run this example are located in the following Techila SDK directory:
-
techila\examples\python\decorator\4_multiplefunction
To run the local version, change your current working directory to the directory containing the example material and execute the following commands:
from local_multiple_functions import *
local_multi_function()To run the distributed version, change your current working directory to the directory containing the example material and execute the following commands:
from run_multi_function import *
run_multi_function()3.6. Example 5 - Using Callback Functions to Postprocess Results
This example illustrates how to use a callback function to postprocess results.
The material discussed in this example is located in the following folder in the Techila SDK:
-
techila\examples\python\decorator\callback
3.6.1. Distributed Version
The Python script run_callback.py containing the distributed version is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_decorator_callback
# Copyright Techila Technologies Ltd.
# This Python script contains the Local Control Code, which will be
# used to distribute computations to the Techila environment. It also
# contains the Worker Code, which will be distributed and evaluated on
# the Workers. The values of the input argument will be set according
# to the parameters defined in the Local Control Code.
#
# Results will be streamed from the Workers in the order they will be
# completed. Results will be visualized by displaying intermediate
# results on the screen.
#
# Usage:
# result = run_callback(jobs, loops)
# jobs: number of Jobs in the Project
# loops: number of iterations performed in each Job
#
# Example:
# result = run_callback(10, 10000000)
import random
# Load the techila library
import techila
# Function that will be executed on Workers.
@techila.distributable()
def mcpi_dist(loops):
count = 0 # No random points generated yet, init to 0.
i = 0
while i < loops:
if pow(pow(random.random(), 2) + pow(random.random(), 2), 0.5) < 1:
count = count + 1
i = i + 1
return({'count': count, 'loops': loops}) # Return the results as a dict object
# This is the callback function, which will be executed once for each
# Job result received from the Techila environment.
@techila.callback()
def callbackfun(jobresult):
global total_jobs
global total_loops
global total_count
total_jobs = total_jobs + 1 # Update the number of Job results processed
total_loops = total_loops + int(jobresult.get('loops')) # Update the number of Monte Carlo loops performed
total_count = total_count + int(jobresult.get('count')) # Update the number of points within the unitary circle
result = 4 * float(total_count) / total_loops # Update the Pi value approximation
# Display intermediate results
print('Number of results included:', total_jobs, 'Estimated value of Pi:', result)
return(jobresult)
# When executed, this function will create the computational Project
def run_callback(jobs, loops):
global total_jobs
global total_loops
global total_count
# Initialize the global variables to zero.
total_jobs = 0
total_loops = 0
total_count = 0
results = []
for i in range(jobs):
res = mcpi_dist(loops)
results.append(callbackfun(res))
techila.run()
return(results)The file contains 3 function definitions:
-
run_callback- This function is used to start the example. -
mcpi_dist- This function has been decorated with@techila.distributable(), meaning it will be executed in TDCE. This function will be used to generate random points inside an unitary circle. The ratio of points inside the unitary circle will be returned and used to calculate an approximated value for Pi. -
callbackfun- This function has been decorated with@techila.callback(), meaning it can be used to postprocess results that have been received from the TDCE environment.
The function run_callback takes two input arguments: jobs and loops. The jobs argument will determine the number of Jobs in the Project. The loops argument determines the number of loops calculated in each Job.
When the techila.run() function is executed, a computational Project will be created. When Jobs are completed, the results will be automatically streamed to the End-User’s computer. Each time a new result has been received, the decorated function callbackfun will be executed and will be used to process the results returned from the Job. In this example, the callback function will be used to calculate an approximated valuf for Pi.
3.6.2. Running the Example
The files needed to run this example are located in the following Techila SDK directory:
-
techila\examples\python\decorator\callback
To run the distributed version, change your current working directory to the directory containing the example material and execute the following commands:
from run_callback import *
result = run_callback(100,10000) # Will create a Project with 100 Jobs.3.7. Example 6 - Using Custom Packages
The purpose of this example is to illustrate how you can transfer packages from your computer to the TDCE environment.
The material discussed in this example is located in the following folder in the Techila SDK:
-
techila\examples\python\decorator\custom_package
3.7.1. Distributed Version
The Python script run_packagetest.py containing the distributed version is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_decorator_custom_package
# Copyright Techila Technologies Ltd.
# This script contains the Local Control Code containing function
# definition for running packagetest example. It also contains the
# Worker Code, packagetest_dist function that will be executed in each
# computational Job.
#
# Usage:
#
# result=run_packagetest()
#
# Import the techila package
import techila
import techilatest.functions as test
# Define the function that will be called on Workers, the packages
# parameter for the decorator defines the packages needed by the
# function
@techila.distributable(packages=['techilatest'])
def packagetest_dist(a, b):
# Call the functions defined in the 'techilatest' package
res1 = test.summation(a, b)
res2 = test.multiplication(a, b)
res3 = test.subtraction(a, b)
res4 = test.division(a, b)
# Return results in a list
return([res1, res2, res3, res4])
# This function is used to create a computational Project
def run_packagetest():
results = []
for i in [1, 2, 4, 8, 16]:
result = packagetest_dist(i, 2)
results.append(result)
techila.run()
# Display the results
for row in results:
print(row)This example also uses functionality from the techilatest/functions.py file shown below for reference.
# Example documentation: https://docs.techilatechnologies.com/help/techila-distributed-computing-engine/python-techila-distributed-computing-engine.html#_example_6_using_custom_packages
def summation(a, b):
return(a + b)
def multiplication(a, b):
return(a * b)
def subtraction(a, b):
return(a - b)
def division(a, b):
af = float(a)
bf = float(b)
return(af / bf)In order to use functionality from the custom package on the Techila Workers, the package will need to be transferred to the TDCE environment. This can be done by passing the following parameter to the decorator:
@techila.distributable(packages=['techilatest'])This parameter defines that a package called techilatest should be transferred from your computer to the TDCE environment.
Additional packages can be transferred by listing them as comma separated list.
@techila.distributable(packages=['techilatest','someadditionalpackage'])3.7.2. Running the Example
In order to run this example, you will first need to install the techilatest package using the following command:
pip3 install --user .After installing the package, you can run the example by executing the following commands in python:
from run_packagetest import *
run_packagetest()4. Peach Tutorial Examples
This Chapter contains four minimalistic examples on how to implement and control the core features of the peach-function. The example material discussed in this Chapter, including Python scripts and data files can be found in the subdirectories under the following folder in the Techila SDK:
-
techila\examples\python\Tutorial
Each of the examples contains three pieces of code:
-
A script containing a locally executable Python function. This function will be executed locally and will not communicate with the distributed computing environment in any way. This script is provided as reference material to illustrate what modifications are required to execute the computations in the Techila environment.
-
A script containing the Local Control Code, which will be executed locally on the End-Users computer. This script contains the peach-function call, which will distribute the computations in the Worker Code to the distributed computing environment
-
A script containing the Worker Code, which will be executed on the Workers. This script contains the computationally intensive part of the locally executable script.
Please note that the example material in this Chapter is only intended to illustrate the core mechanics related to distributing computation with the peach-function. More information on available features can be found in Peach Feature Examples and by executing the following commands in Python.
import techila
help(techila.peach)4.1. Executing a Simple Python Function on Workers
This example is intended to provide an introduction on distributed computing using Techila with Python using the peach-function. The purpose of this example is to:
-
Demonstrate how to modify a simple, locally executable Python script that contains one function so that the computational operations will be performed in the Techila environment
-
Demonstrate the difference between Local Control Code and Worker Code in a Python environment
-
Demonstrate the basic syntax of the peach-function in a Python environment
The material discussed in this example is located in the following folder in the Techila SDK:
-
techila\examples\python\Tutorial\1_distribution
4.1.1. Locally Executable Python Function
The Python script local_function.py contains one function called local_function, which consists of one for-loop. The algorithm of the locally executable function used in this example is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_tutorial_1_distribution
# Copyright Techila Technologies Ltd.
# This function contains the locally executable function, which can be
# executed on the End-Users computer. This function does not
# communicate with the Techila environment.
#
# Usage:
# result = local_function(x)
# x: the number of iterations in the for loop.
#
# Example:
# result = local_function(5)
def local_function(x):
result = []
for j in range(x):
result.append(1 + 1)
return resultThe function takes one input argument, which defines the number of iterations that will be performed in the for-loop. Every iteration performs the same arithmetic operation: 1+1. The result of the latest iteration will be appended to the result list.
For example, when performing five iterations the result list would contain the following values.
| Number of iterations: 5 | |
|---|---|
index |
0 1 2 3 4 |
value |
2 2 2 2 2 |
To execute the locally executable function in Python, use the commands shown below:
from local_function import *
result=local_function(5)4.1.2. Distributed Version of the Program
All arithmetic operations in the locally executable function are performed in the for-loop. There are no recursive data dependencies between iterations, meaning that the all the iterations can be performed simultaneously. The iterations can be performed simultaneously by placing the arithmetic operations to a separate file (distribution_dist.py), which can be then transferred and executed on Workers.
The file containing the Local Control Code (run_distribution.py) will be used to create the computational Project. The Worker Code (distribution_dist.py) will be transferred to the Workers, where it will be automatically imported using command:
from distribution_dist import *This import process will take place at the preliminary stage of Job. After the functions have been imported, the function distribution_dist will be executed. The result returned by the function will be returned from the Job.
4.1.3. Local Control Code
The Local Control Code used to create the computational Project is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_tutorial_1_distribution
# Copyright Techila Technologies Ltd.
# This function contains the Local Control Code, which will create the
# computational Project.
#
# Usage:
# result = run_distribution(jobcount)
#
# jobcount: number of Jobs in the Project
#
# Example:
# result = run_distribution(5)
def run_distribution(jobcount):
# Import the techila package
import techila
# Create the computational Project with the peach function.
result = techila.peach(funcname = 'distribution_dist', # Function that will be called on Workers
files = 'distribution_dist.py', # Python-file that will be sourced on Workers
jobs = jobcount, # Number of Jobs in the Project
)
# Display results after the Project has been completed. Each element
# will correspond to a result from a different Job.
print(result)
return(result)The code consists of one function called run_distribution. This function takes one input argument called jobcount (integer). This variable will be used during the peach-function call to define the value of the jobs parameter, which defines the number of Jobs in the Project.
Techila helper functions (including peach) are made available by importing the techila package.
The computational Project is created with a peach-function call. After the computational Project has been completed, the results will be stored in the result list. The number of list elements will be the same as the number of Jobs in the Project. Each list element will contain the result returned from one Job.
The parameters of the peach-function call are explained below.
funcname = 'distribution_dist'The funcname parameter shown above defines that the function distributed_dist will be executed in each Job. This function will be defined when the file distribution_dist.py is evaluated as explained below.
files = 'distribution_dist.py'The parameter shown above defines that code in file named distributed_dist.py should be imported using command from distribution_dist import *. This import process will make all variables and functions defined in the file accessible during the computational Job. In this example, the file contains the definition for the distribution_dist function.
jobs = jobcountThe jobs parameter shown above defines the number of Jobs in the Project. In this example, the number of Jobs will be based on the value of the jobcount variable. The number of Jobs in the Project could also be defined by using the peachvector parameter. For more information on how to define the peachvector, please see Using Input Parameters.
After the Project has been completed, the results stored in result will be printed. Each element in the array will contain the result for one Job in the Project.
The function will return the result variable as the output.
4.1.4. Worker Code
The Worker Code that will be executed on the Workers is in the file called distribution_dist.py. The content of the file is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_tutorial_1_distribution
# Copyright Techila Technologies Ltd.
# This function contains the function that will be executed during
# computational Jobs. Each Job will perfom the same computational
# operations: calculating 1 + 1.
def distribution_dist():
# Store the sum of 1 + 1 to variable 'result'
result = 1 + 1
# Return the value of the 'result' variable. This value will be
# returned from each Job and the values will be stored in the list
# returned by the peach-function.
return(result)Operations performed in the Worker Code correspond to the operations performed during one iteration of the locally executable for-loop structure. Each Job will simply sum two integers (1+1) and store the value of the summation to the result variable. The result variable will returned from the Job will be eventually received by the End-User as a one of the list elements returned by the peach-function in the Local Control Code.
The interaction between the Local Control Code and the Worker Code is illustrated below.
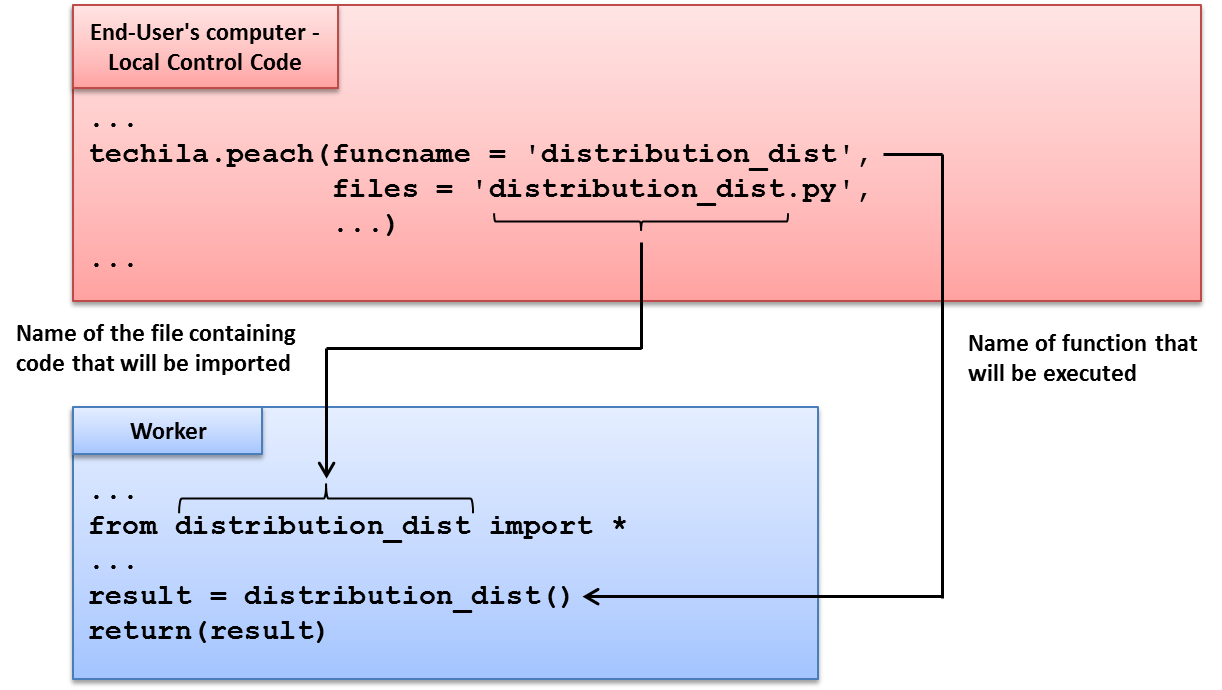
files parameter. In this example, the file distribution_dist.py will be transferred to all Workers and code in the file will be imported at the preliminary stages of the computational Job. The function that will be called is defined with the funcname parameter. In this example, the function distribution_dist will be called in each computational Job.4.1.5. Creating the Computational Project
To create the computational Project, change your current working directory (in Python) to the directory containing the example material for this example.
After having navigated to the correct directory, create the computational Project using commands shown below:
from run_distribution import *
result = run_distribution(5)The computational Jobs will be extremely short as each Job consists of simply summing up two integers; 1+1. The computations occurring during the Project are illustrated below.
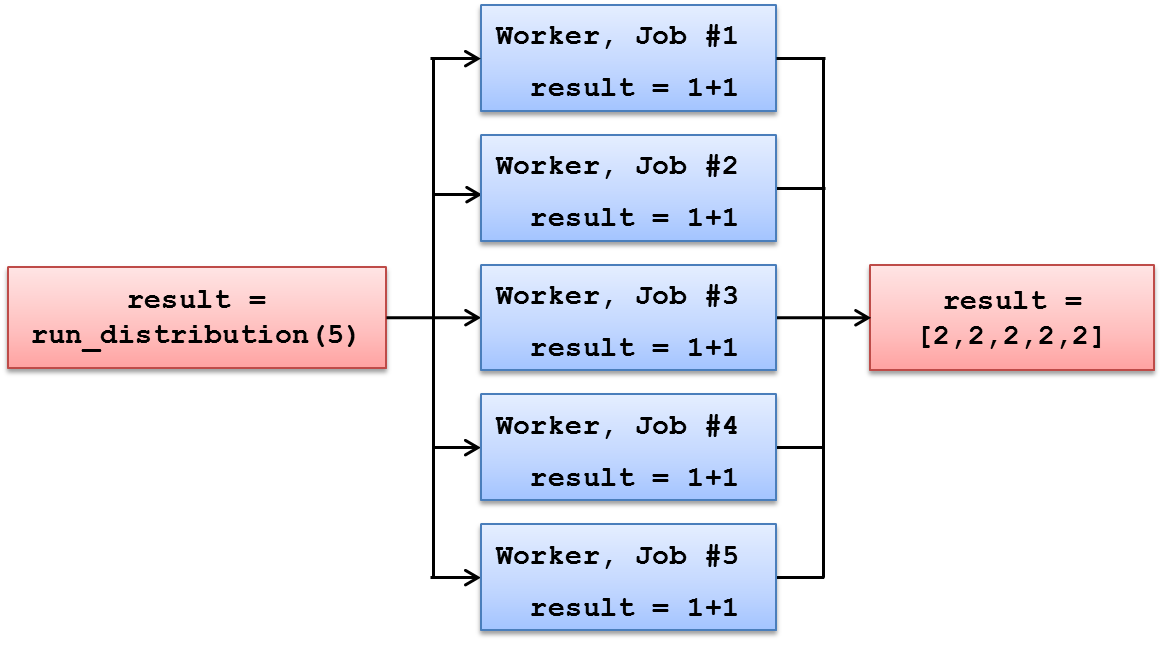
run_distribution will be used to determine the number of Jobs in the Project. The same arithmetic operation, 1+1, is performed in each Job. Results are delivered back to the End-Users computer where they will be stored as list elements in the result list.4.2. Using Input Parameters
This purpose of this example is to demonstrate:
-
How to transfer input parameters to the executable function
The material discussed in this example is located in the following folder in the Techila SDK:
-
techila\examples\python\Tutorial\2_parameters
In this example, parameters will be transferred to the Workers and passed to the executable function as input arguments. This will be performed by using the params parameter of the peach-function.
The general syntax for defining input arguments for the executable function is shown below:
params = <list of input arguments>The <list of input arguments> notation will need to be replaced with a comma separated list of variables that you wish to pass as input arguments. For example, the following syntax would define two input arguments var1 and var2 for the function that will be executed on Workers.
params = [var1, var2]The values of the input arguments will be read from your current Python session, meaning you can transfer any parameters that are currently defined.
Dynamic input arguments (arguments that will have a different value for each Job) can be passed to the executable function by using the '<param>' notation. This notation will be replaced by a different element of the peachvector in each Job.
For example, the following syntax will pass three input arguments for the executable function. The first two input arguments (var1 and var2) have the same values for all Jobs. The third input argument ('<param>') will be replaced with peachvector elements. Job #1 will receive the first element (value 2), Job #2 will receive the second element (value 4) and so on.
params = [var1, var2, '<param>'],
peachvector = [2,4,6,8,10]Please note that when defining the peachvector, the length of the peachvector will also define the number of Jobs in the Project. With the example shown above, the Project would consist of five Jobs.
Another parameter that can be used when performing parameter sweep type computations is the vecidx parameter. When used, this notation will be replaced by the corresponding peachvector index for each Job.
For example, the following syntax will pass two input arguments to the executable function. The first input argument ('<param>') will be replaced with peachvector elements and the second input argument ('<vecidx>') with the corresponding peachvector index values.
params = ['<param>', '<vecidx>'],
peachvector = [2,4,6,8,10]The input arguments that would be passed to the executable functions during different Jobs are shown below.
| Job # | Argument #1 ('<param>') | Argument #2 ('<vecidx>') |
|---|---|---|
Job #1 |
2 |
0 |
Job #2 |
4 |
1 |
Job #3 |
6 |
2 |
Job #4 |
8 |
3 |
Job #5 |
10 |
4 |
4.2.1. Locally Executable Python Function
The algorithm for the locally executable function used in this example is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_tutorial_2_parameters
# Copyright Techila Technologies Ltd.
# This function contains the locally executable function, which
# can be executed on the End-Users computer. This function
# does not communicate with the Techila environment.
#
# Usage:
# result = local_function(multip, loops)
# multip: value of the multiplicator
# loops: the number of iterations in the 'for' loop.
#
# Example:
# result = local_function(2, 5)
def local_function(multip, loops):
result = []
for x in range(1, loops + 1):
result.append(multip * x)
print(result)
return(result)This function takes two input arguments; multip and loops. The parameter loops determines the number of iterations in the for-loop. The parameter multip is a number, which will be multiplied with the iteration counter represented by x. The result of this arithmetic operation will be appended to a list called result, which will be returned as the output value of the function.
An example result list (five iterations) is shown below.
| multip = 2; loops=5 | |
|---|---|
index |
0 1 2 3 4 |
result |
2 4 6 8 10 |
The locally executable function can be executed in python using the commands shown below:
from local_function import *
result=local_function(5)After executing the commands, numerical values stored in the result list will be displayed.
4.2.2. Distributed Version of the Program
All the computations in locally executable Python function are performed in the for-loop and there are no dependencies between the iterations. As a result of this, the locally executable program can be converted to a distributed version by extracting the arithmetic operation into a separate piece of code (parameters_dist.py), which will be executed on Workers.
The Local Control Code (run_parameters.py) contains the peach-function call that will be used to create the computational Project. In order to perform similar operations in the Project as in the local version, input arguments need to be given to the executable function to simulate different iterations of the for-loop. These input arguments will be transferred by the using the params parameter of the peach-function.
4.2.3. Local Control Code
The Local Control Code used to create the computational Project is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_tutorial_2_parameters
# Copyright Techila Technologies Ltd.
# This function contains the Local Control Code, which will create the
# computational Project.
#
# Usage:
# result = run_parameters(multip, jobs)
# multip: value of the multiplicator
# jobs: the number of iterations in the 'for' loop.
#
# Example:
# result = run_parameters(2, 5)
def run_parameters(multip, jobs):
# Load the techila package
import techila
# Create the computational Project with the peach function.
result = techila.peach(funcname = 'parameters_dist', # Function that will be called on Workers
params = [multip, '<param>'], # Parameters for the function that will be executed
files = ['parameters_dist.py'], # Files that will be sourced at the preliminary stages
peachvector = range(1, jobs + 1), # Number of Jobs. Peachvector elements will also be used as input parameters.
)
# Display the results after the Project is completed
print(result)
return(result)Input arguments for the function that will be executed on the Worker are defined with the params parameter. In this example, two input arguments will be passed to the executable function. The first input argument (multip) will be identical for all Jobs and will correspond to the value passed as an input argument to the run_parameters function. The second input argument ('<param>') will be replaced with a different peachvector element for each Job. These elements will be used to simulate the value of for-loop counter used in the locally executable function.
The peachvector will contain elements from one (1) to the value of the jobs parameter. As the '<param>' notation was used in the params parameter, these elements will be passed as input arguments to the executable function. Job #1 will receive the first element (value 1), Job #2 will receive the second element (value 2) and so on.
The number of elements in the peachvector will also define the number of Jobs in the Project. In this example, the number elements will be the same as the value of the jobs variable.
The value returned by the peach-function will be stored in the result list. Each list element will contain the result returned from one of the Jobs.
4.2.4. Worker Code
The function that will be executed on Workers (in file parameters_dist.py) is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_tutorial_2_parameters
# Copyright Techila Technologies Ltd.
# This function contains the function that will be executed during
# computational Jobs. Each Job will multiply the values of the two
# input arguments, 'multip' and 'jobidx'. 'multip' will be same for
# all Jobs, 'jobidx' will receive a different peachvector element.
def parameters_dist(multip, jobidx):
# Multiply the values of variables 'multip' and 'jobidx'
result = multip * jobidx
# Return the value of the 'result' variable from the Job.
return(result)The Local Control Code discussed earlier defined two parameters in the params parameter, which will be passed to the executable function (parameters_dist) as input arguments. The first input argument (multip) will have the same value in all Jobs. The second input argument (jobidx) will be replaced with different peachvector elements. The value of the jobidx parameter will fundamentally be used to simulate the value of the loop counter that was used in the locally executable function.
The interaction between the Local Control Code and the Worker Code is illustrated below.
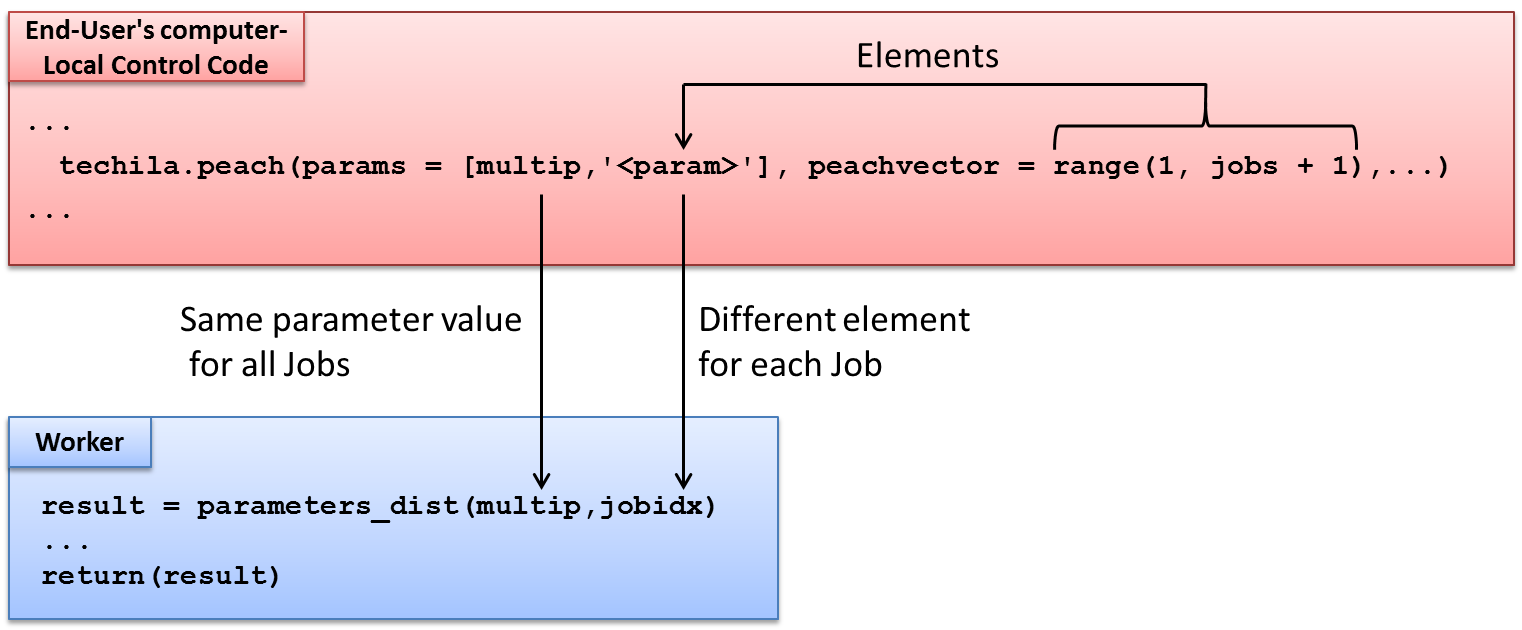
params parameter will be passed to executable function as input arguments. The '<param>' notation is used to transfer elements of the peachvector to the Worker Code. The value of the jobs variable is defined by the End-User and it is used to define the length of the peachvector. The value of the jobs parameter therefore also defines the number of Jobs.4.2.5. Creating the Project
To create the computational Project, change your current working directory (in Python) to the directory that contains the example material for this example.
After having navigated to the correct directory, create the computational Project using commands shown below:
from run_ parameters import *
result = run_parameters(2,5)If prompted, enter the password to your keystore file. The Project will be created and information on the Project progress will be displayed in the console. After all Jobs have been completed, the result list will be printed. Each element in the result list will contain the value returned from one Job. The Jobs will be extremely short as each Job consists of simply multiplying two integers.
The computational operations occurring during the Project are illustrated below.
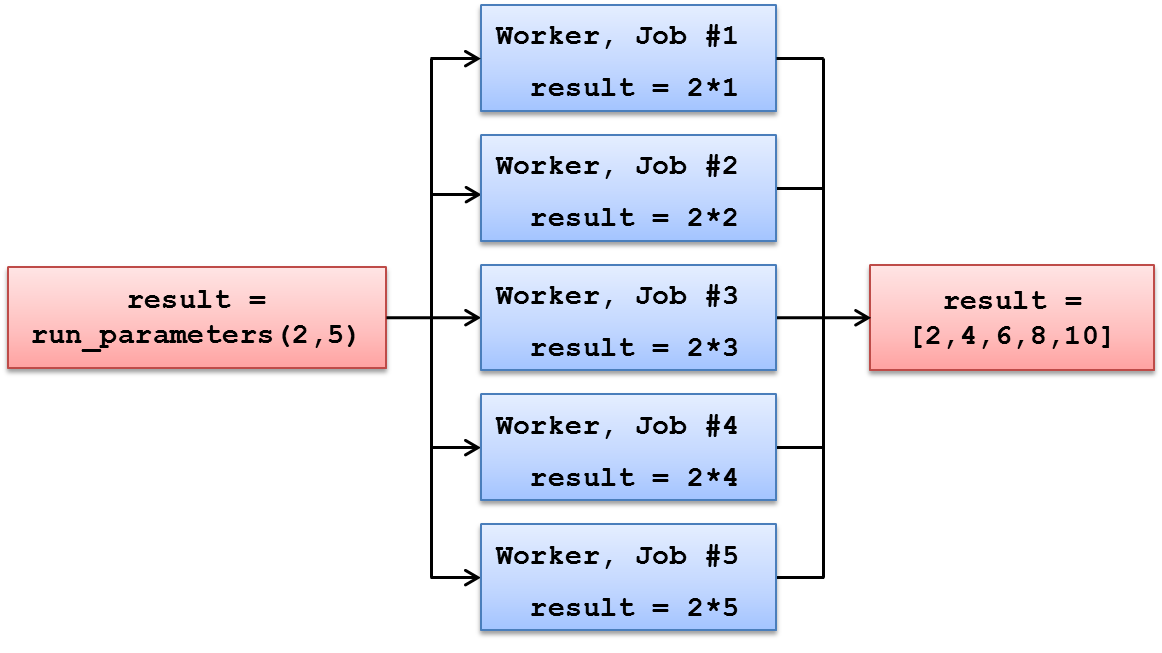
peachvector and each Job will receive a different element. The peach-function will return the Job results as a list called result as defined in the Local Control Code.4.3. Transferring Data Files
This purpose of this example is to demonstrate:
-
How to transfer data files to the Workers
The material used in this example is located in the following folder in the Techila SDK:
-
techila\examples\python\Tutorial\3_datafiles
Files can be transferred to Workers by using the datafiles parameter of the peach-function. The general syntax for using the parameter is explained below:
datafiles=['<list of files>']The <list of files> notation will need to be replaced with a comma separated list of files that you wish to transfer to Workers. For example, the following syntax would transfer files called file1 and file2 (located in the current working directory) to the Workers.
datafiles=['file1','file2']If the files that you wish to transfer to Workers are not located in your current working directory, the path of the file needs to be defined. For example, the following syntax would transfer file1 from the current working directory and file2 from the directory C:\temp (backslashes \ need to be escaped by adding another backslash \\).
datafiles=['file1','C:\\temp\\file2']Please note that after the files have been transferred to Workers, all files will be stored in the same temporary working directory with the executable code. In cases where you are using path definitions in your file access methods, you might need to modify those commands to access the files from the current working directory on the Worker.
Also note that the datafiles parameter should only be used to transfer small files that change frequently. This is because the files will be stored in the Parameter Bundle, which will be re-created automatically when creating a new computational Project.
If you plan to transfer large files, or files that will not change frequently, it is advisable that you create a separate Data Bundle to transfer the files. Instructions on how to use a Data Bundle to transfer data files can be found in Data Bundles.
4.3.1. Locally Executable Python Function
The locally executable Python script used in this example is shown in below.
# Example documentation: http://www.techilatechnologies.com/help/python_tutorial_3_datafiles
# Copyright Techila Technologies Ltd.
# This function contains the locally executable function, which can be
# executed on the End-Users computer. This function does not
# communicate with the Techila environment.
#
# Usage:
# result = local_function()
# Import the csv package
import csv
def local_function():
# Read the file from the current working directory
rows = list(csv.reader(open('datafile.txt', 'r'), delimiter=' '))
# Create empty list for results
contents=[]
for row in rows: # For each row
row_int = map(int,row) # Convert the values to integers
sum_row_int=sum(row_int) # Sum the integers
contents.append(sum_row_int) # Append the summation result
print('Sums of rows: ', contents) # Display the sums
return(contents) # Return list containing summation resultsDuring the initial steps of the function, the file datafile.txt will be opened and the rows will be read and stored in the rows variable. This file contains four rows of numbers, where each number is separated by white space.
The function also contains a for-loop, which will be used to sum the values on each row and append the summation result in the contents list. After all rows have been processed the results will be displayed.
To execute the locally executable function in python, use the commands shown below:
from local_function import *
result=local_function()4.3.2. Distributed Version of the Program
Each row in the datafile.txt can be processed independently, meaning Jobs in the computational Project can be configured to process different rows simultaneously. This can be achieved by transferring the file datafile.txt to Workers by using the datafiles parameter of the peach-function.
Each Job can then be configured to process one of the rows in the data file. This can be achieved by using the indexes of the peahcvector (notation (<vecidx>)) to index the file and process a different row in each Job.
4.3.3. Local Control Code
The Local Control Code that is used to create the computational Project is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_tutorial_3_datafiles
# Copyright Techila Technologies Ltd.
# This function contains the Local Control Code, which will create the
# computational Project.
#
# Usage:
# result = run_datafiles()
def run_datafiles():
# Import the techila package
import techila
jobs = 4 # Will be used to define the 'peachvector'.
result = techila.peach(funcname = 'datafiles_dist', # The function that will be executed
params = ['<vecidx>'], # Input argument for the executable function
files = ['datafiles_dist.py'], # Files that will be evaluated on Workers
datafiles = ['datafile.txt'], # Datafiles that will be transferred to Workers
peachvector = range(1, jobs + 1), # Length of the peachvector determines the number of Jobs.
)
print('Sums of rows: ', result) # Display the sums
return(result) # Return list containing summation resultsInput arguments for the executable function are defined using the params parameter. In this example, the notation '<vecidx>' has been defined which means index values of the peachvector will be passed as an input arguments to the function. The value of the notation will be zero (0) for Job #1, one (1) for Job #2 and so on. These index values will be used to choose which row should be processed from the data file.
Data files are transferred to Workers using the datafiles parameter. In this example, the file datafile.txt has been defined and will be transferred to Workers. After the file has been transferred to the Worker, it will be copied in the same temporary working directory with the executable code.
4.3.4. Worker Code
The algorithm of the Worker Code used in this example is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_tutorial_3_datafiles
# Copyright Techila Technologies Ltd.
# This script contains the function that will be executed during
# computational Jobs. Each Job will sum the values in a specific
# row in the file 'datafile.txt' and return the value as the
# output.
# Import the csv package
import csv
def datafiles_dist(jobidx):
# Read the file 'datafile.txt' from the temporary working directory.
rows = list(csv.reader(open('datafile.txt', 'r'), delimiter=' '))
# Sum the values in the row. The row is chosen based on the value
# of the 'jobidx' parameter.
row = rows[jobidx] # Choose row based on the 'jobidx' parameter
row_int = map(int,row) # Convert to integers
sum_row_int=sum(row_int) # Sum the values on the row
return(sum_row_int) # Return summation as the resultThe code starts by importing the csv package that will be used when reading the contents of the file. All packages included in the standard Python distribution will be automatically available for use on the Workers. Additional packages can be made available by using the bundleit command as explained in Using Custom Python Packages in Computational Projects
The function that will be executed on Workers takes one input argument (jobidx), which will be replaced by the index values of the peachvector as explained earlier (<vecidx> notation in the Local Control Code). This input argument will be used to select which row should be processed.
The first operations in the function will select the row that matches the value of the jobidx variable and sum the values on that row. This corresponds to the operations that are performed in one iteration of the for-loop structure in the locally executable function.
After processing the row, the summation result will be returned as the result from the computational Job.
The interaction between the Local Control Code and the Worker Code are shown below.
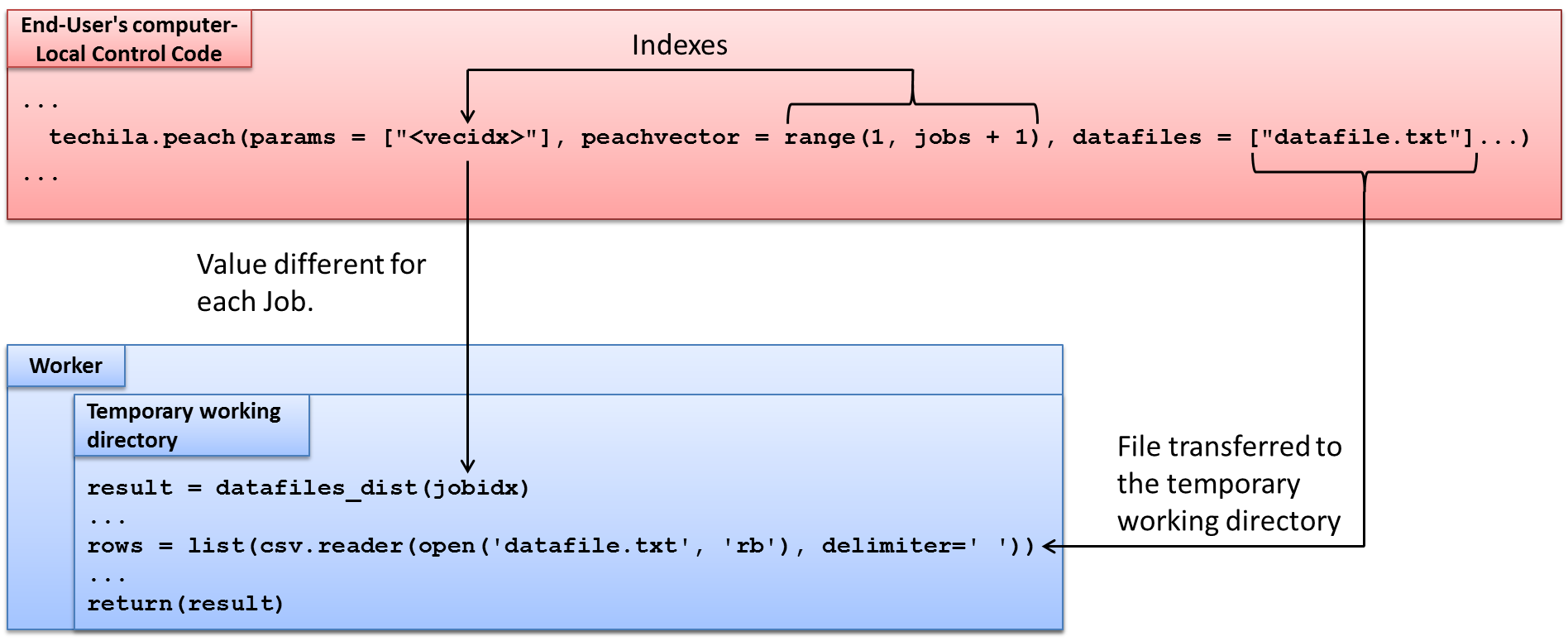
params parameter will be given as input arguments to the executable function. The datafile.txt file will be transferred to the same temporary directory with the executable code. The syntax for loading the datafile.txt will be the same as in the locally executable function.4.3.5. Creating the Computational Project
To create the computational Project, change your current working directory (in Python) to the directory that contains the example material for this example. After having navigated to the correct directory, create the computational Project using commands shown below:
from run_datafiles import *
result = run_datafiles()If prompted, enter the password to your keystore file. The Project will be created and information on the Project progress will be displayed in the console. The number of Jobs in the Project will be automatically fixed to four according to the value of the jobs parameter defined in the Local Control Code.
4.4. Multiple Functions in a Python Script
The purpose of this example is to demonstrate:
-
How to define multiple functions in the Worker Code
-
How to use different functions as the entry point when starting a Job on the Workers
The material used in this example is located in the following folder in the Techila SDK:
-
techila\examples\python\Tutorial\4_multiplefunctions
4.4.1. Locally Executable Python Function
The Python script containing the locally executable functions is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_tutorial_4_multiplefunctions
# Copyright Techila Technologies Ltd.
# This Python-script contains two locally executable functions, which
# can be executed on the End-Users computer. These functions
# do not communicate with the Techila environment.
def function1():
# When called, this function will return the value 2.
return(1 + 1)
def function2():
# When called, this function will return the value 100.
return(10 * 10)To execute the functions on your local computer, please define the functions using the commands shown below:
from local_multiple_functions import *After the functions have been defined, function1 can be executed using command:
result = function1()When called, function1 will perform the summation 1+1 and return 2 as the result.
Respectively, the function2 can be executed with command:
result = function2()When called, function2 will perform the multiplication 10*10 and return 100 as the result.
4.4.2. Distributed Version of the Program
In the locally executable version of the example, the Python script contains two function definitions.
In the distributed version, the functions can be made available on Workers by including both function definitions in the Python script that will be evaluated at the preliminary stage of the Job. This can be achieved by using the files parameter. As the file containing the functions will be evaluated before any functions are called, this also means that either one of these functions can be used as an entry point in the computational Job (values for the funcname parameter).
4.4.3. Local Control Code
The Local Control Code used to create the computational Project is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_tutorial_4_multiplefunctions
# Copyright Techila Technologies Ltd.
# This function contains the Local Control Code, which will create the
# computational Project. The value of the input argument will
# determine which function will be executed in the computational Jobs.
#
# Usage:
# result = run_multi_function(funcname)
# Example:
# result = run_multi_function('function1')
def run_multi_function(funcname):
# Load the techila library
import techila
# Create the computational Project with the peach function.
result = techila.peach(funcname = funcname, # Executable function determined by the input argument of 'run_multi_function'
files = ['multi_function_dist.py'], # The Python-script that will be evaluated on Workers
peachvector = [1], # Set the number of Jobs to one (1)
)
print(result)
return(result)The function run_multi_function takes one input argument, which will be used to define the value of the funcname parameter. This means that the input argument will be used to determine, which function will be executed during a Job.
The files parameter lists one file called multifunction_dist.py, which contains the same function definitions that were defined in the locally executable version of this example. This either one of the functions (function1 and function2) can be used as an entry point.
4.4.4. Worker Code
The file containing the Worker Code ('multi_function_dist.py') used in this example is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_tutorial_4_multiplefunctions
# Copyright Techila Technologies Ltd.
# This Python-script will be evaluted at the preliminary stages of a
# computational Job. When evaluated, two functions will be defined.
# Either one of these functions can be then used as an entry point
# by defining the applicable function name as the value of
# the funcname parameter in the Local Control Code.
def function1():
# When called, this function will return the value 2.
return(1 + 1)
def function2():
# When called, this function will return the value 100.
return(10 * 10)As can be seen, the Worker Code contains the same function definitions as the locally executable version of the program. The Python script containing the function definitions will be evaluated at the preliminary stages of a computational Job, meaning both functions will be defined and can be called during a computational Job.
This also means either function can also be used as the entry point when defining the funcname parameter in the Local Control Code.
4.4.5. Creating the Computational Project
To create the computational Project, change your current working directory (in Python) to the directory that contains the example material for this example.
After having navigated to the correct directory, create the computational Project using commands shown below:
from run_multi_function import *After having evaluated the Local Control Code, a computational Project that executes function1 on Workers can be created using command shown below:
result = run_multi_function('function1')This will create a computational Project that consists of one (1) Job. The computational operations occurring during the Project are illustrated below.
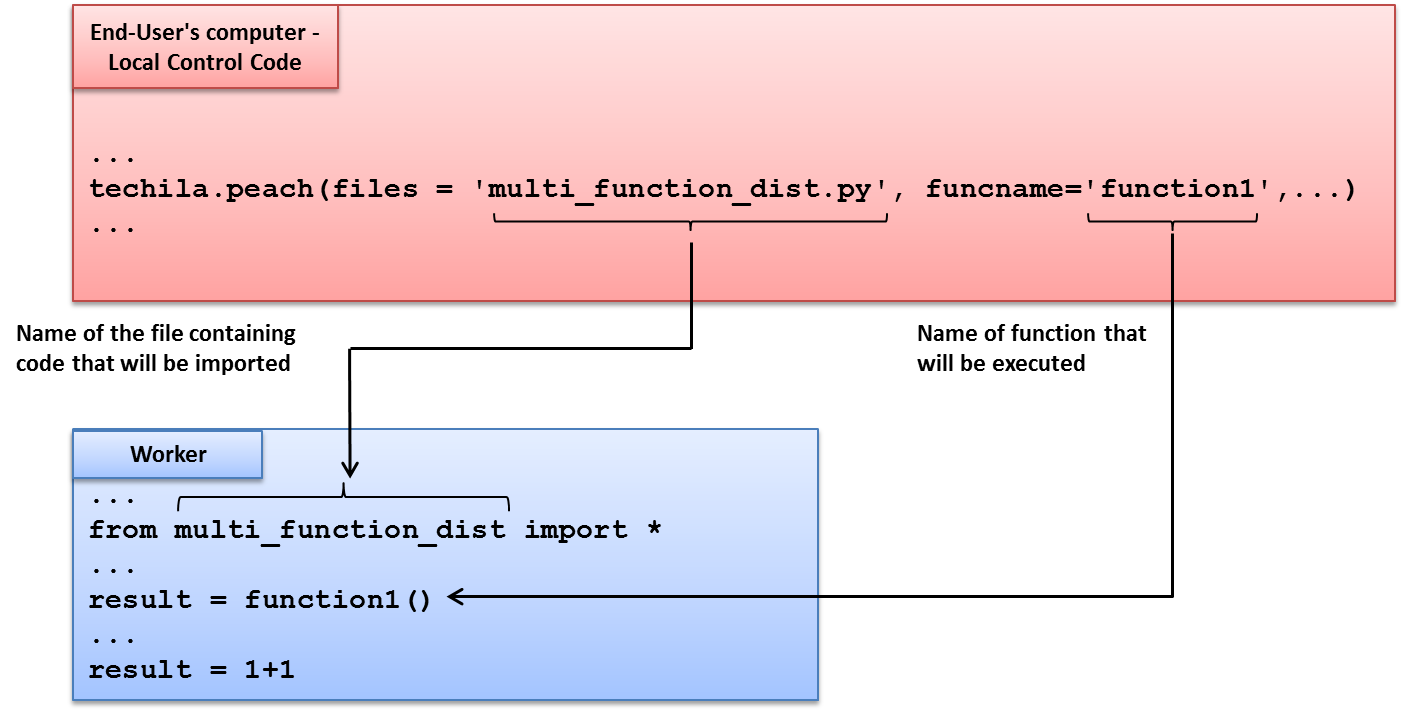
function1 will be called.Respectively, function2 can be executed on the Worker by using the command:
result = run_multi_function('function2')The computational operations occurring during the Project are illustrated below.
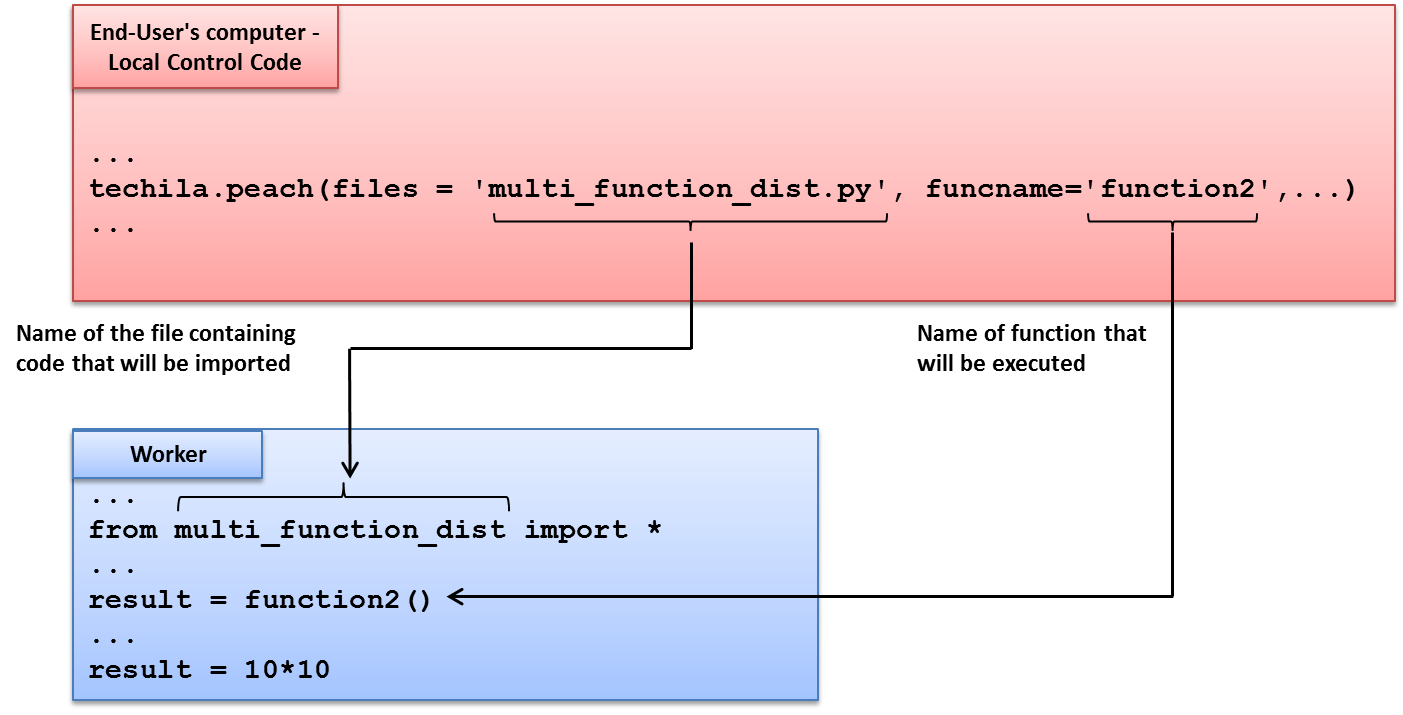
function2) can be defined by giving the applicable value to the funcname parameter.5. Peach Feature Examples
The basic methodology and syntax of distributing computations with the peach-function was illustrated in the Tutorial in Peach Tutorial Examples. In addition to the basic mechanics, the peach-function offers a wide range of optional features.
Several of the examples will use the approximation of Pi with a Monte Carlo method as a framework when demonstrating the mechanics of different features. The basic implementation for the Monte Carlo method can be found in Monte Carlo Pi with Peach. This implementation and can be used as a reference point to see what changes are required for implementing different features.
The example material discussed this Chapter, including Python scripts and data files can be found in the example specific directories under the following directory in the Techila SDK:
-
techila\examples\python\Features\<example specific directories>
Please note that the example material discussed in this Chapter does not contain examples on all available peach-function features. For a complete list on available features, execute the following command in Python:
import techila
help(techila.peach)Monte Carlo Method
A Monte Carlo method is used in several of the examples for evaluating the value of Pi. This section contains a short introduction on the Monte Carlo method used in these examples.
The Monte Carlo method is a statistical simulation where random numbers are used to model and solve a computational problem. This method can also be used to approximate the value of Pi with the help of a unit circle and a random number generator.
The area of the unit circle shown in the figure is determined by the equation π∙r^2 and the area of the square surrounding it by the equation (2 * r)^2. This means the ratio of areas is defined as follows:
ratio of areas = (area of the unit circle)/(area of the square) = (pi * r ^ 2 /( (2 * r) ^2 )=( pi * r ^ 2 / (4 * r ^ 2 )= pi / 4 = 0.7853981
When a random point will be generated, it can be located within or outside the unit circle. When a large number of points are being generated with a reliable random number generator, they will be spread evenly over the square. As more and more points are generated, the ratio of points within circle compared to the total number of points starts to approximate the ratio of the two areas.
ratio of points * ratio of areas
(points within the circle)/(total number of points) = (area of the unit circle)/(area of the square)
(points within the circle)/(total number of points) = pi / 4
For example, in a simulation of 1000 random points, the typical number of points within the circle is approximately 785. This means that the value of Pi is calculated in the following way.
785 / 1000 * pi / 4
pi * 4 * 785 / 1000 = 3.14
Algorithmic approaches are usually done only using one quarter of a circle with a radius of 1. This is simply because of the fact that number generating algorithms on many platforms generate random numbers with a uniform(0,1) distribution. This does not change the approximation procedure, because the ratios of the areas remain the same.
5.1. Monte Carlo Pi with Peach
The purpose of this example is to demonstrate:
-
How to approximate the value of Pi using Monte Carlo method
-
Converting a locally implemented Monte Carlo method to a distributed version
The material used in this example is located in the following folder in the Techila SDK:
-
techila\examples\Python\Features\basic_monte_carlo_pi
5.1.1. Locally executable function
The locally executable function for approximating the value of Pi used in this example is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_features_basic_monte_carlo_pi
# Copyright Techila Technologies Ltd.
# This function contains the locally executable function, which can be
# executed on the End-Users computer. This function does not
# communicate with the Techila environment. The function implements a
# Monte Carlo routine, which approximates the value of Pi.
#
# Usage:
# result = local_function(loops)
# loops: the number of iterations in Monte Carlo approximation
#
# Example:
# result = local_function(100000000)
import random
def local_function(loops):
# Initialize counter to zero.
count = 0
# Perform the Monte Carlo approximation.
i = 0
while i < loops:
if pow(pow(random.random(), 2) + pow(random.random(), 2), 0.5) < 1:
count = count + 1
i = i + 1
# Calculate the approximated value of Pi based on the generated data.
pivalue = 4 * float(count) / loops
# Display results
print 'The approximated value of Pi is:', pivalue
return(pivalue)The function takes one input argument called loops, which determines the number of iterations in the for-loop. During each iteration, two random numbers will be generated, which will be used as the coordinates of the random point. The coordinates of the point are then used to calculate the distance of the point from the centre of the unit circle. If the distance is less than one, the point is located within the unit circle and the counter is incremented by one. After all iterations have been completed, the value of Pi will be calculated.
To execute the function locally on your computer, use the commands shown below:
from local_function import *
result = local_function(10000000)This will approximate the value of Pi using 10,000,000 randomly generated points. The operation will take approximately one minute, depending on your CPU. If you wish to perform a shorter approximation, reduce the number of random points generated to e.g. 1,000,000.
After the approximation is completed, the approximated value of Pi will be displayed.
5.1.2. Distributed version of program
The computationally intensive part in the Monte Carlo method is the random number sampling, which is performed inside the for-loop in the locally executable function. There are no dependencies between the iterations, meaning that the sampling process can be divided into a separate function and executed simultaneously on Workers.
Note that the seed of the random number generator is initialized automatically on the Workers by the peachclient as explained in Process Flow in Computational Projects. If you wish to use a different seeding method, please seed the random number generator directly in the Worker Code.
5.1.3. Local Control Code
The Local Control Code used in this example to create the computational Project is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_features_basic_monte_carlo_pi
# Copyright Techila Technologies Ltd.
# This Python script contains the Local Control Code, which will be
# used to distribute computations to the Techila environment.
#
# The Python script named 'mcpi_dist.py' will be distributed and
# evaluated on Workers. The 'loops' parameter will be transferred to all
# Jobs as an input argument. The 'run_mcpi' function will return the value
# of the 'result' variable, which will contain the approximated value of Pi.
#
# Usage:
# result = run_mcpi(jobcount, loops)
# jobcount: number of Jobs in the Project
# loops: number of iterations performed in each Job
#
# Example:
# result = run_mcpi(10, 100000)
# Load the techila package
import techila
def run_mcpi(jobcount, loops):
# Create the computational Project with the peach function.
result = techila.peach(funcname = 'mcpi_dist', # Function that will be executed on Workers
params = [loops], # Parameters for the executable function
files = ['mcpi_dist.py'], # Files that will be evaluated on Workers
jobs = jobcount # Number of Jobs in the Project
)
# Calculate the approximated value of Pi based on the results received.
result = 4 * float(sum(result)) / (jobcount * loops)
# Display results
print('The approximated value of Pi is:', result)
return(result)The file contains one function called run_mcpi, which takes two input arguments: jobcount and loops. The jobcount parameter will be used to define the value for the jobs parameter (in the peach-function call) and will define the number of Jobs in the Project. The loops parameter will be passed as an input argument (by using params) to the mcpi_dist function that will be executed on Workers.
After all Jobs have been completed, the peach-function will return a list called result. Each list element will correspond to the result generated in one Job and will contain the number of points within the unitary circle. These values will be combined and used to calculate the approximate value of Pi.
5.1.4. Worker Code
The Worker Code used in this example is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_features_basic_monte_carlo_pi
# Copyright Techila Technologies Ltd.
# This Python script contains the Worker Code, which will be
# distributed and sourced on the Workers. The values of the input
# parameters will be received from the parameters defined in the Local
# Control Code.
import random
def mcpi_dist(loops):
count = 0 # No random points generated yet, init to 0.
i = 0
while i < loops:
if pow(pow(random.random(), 2) + pow(random.random(), 2), 0.5) < 1:
count = count + 1
i = i + 1
return(count) # Return the resultThe function mcpi_dist is very similar to the algorithm of the locally executable function. The function takes one input argument called loops which will be used to determine the number of iterations performed during the Job. During each iteration, the distance of a randomly generated point from the centre will be calculated. If the distance is less than one, the point is within the unit circle and the count is incremented by one.
No post-processing activities are performed in the Worker Code, as the results from individual Jobs will be post-processed in the Local Control Code after all Jobs have been completed.
5.1.5. Creating the computational project
To create the computational Project, change your current working directory in your Python environment to the directory that contains the example material for this example.
After having navigated to the correct directory, create the computational Project using commands shown below:
from run_mcpi import *
result = run_mcpi(10,1000000)This will create a Project consisting of ten Jobs, each containing 1,000,000 iterations. The Jobs will be distributed to Workers, where the Monte Carlo routine in the Worker Code is executed. When a Worker finishes the Monte Carlo routine, results are transferred to the Techila Server. After all the Workers have transferred the results to the Techila Server, the results are transferred to the End-Users computer. After the results have been downloaded, the post-processing operations will be performed and the approximated value of Pi will be displayed.
5.2. Streaming & Callback Function
Streaming enables individual results generated in computational Jobs to be transferred to your computer as soon as they become available. This is different from the default implementation, where all the results will be transferred in a single package after all of the Jobs have been completed.
Callback functions can be used to post process individual results as soon as they have been streamed from the Techila Server to End-User. The callback function is called once for each result file that will be transferred from the Techila Server.
The example presented in this Chapter uses streaming and a callback function.
The material used in this example is located in the following folder in the Techila SDK:
-
techila\examples\Python\features\streaming_callback
Streaming is disabled by default. Streaming can be enabled with the following parameter pair:
stream = TrueA callback function can be defined by using the following parameter pair:
callback=<callback function name>The notation <callback function name> will need to be replaced with the name of the function you wish to use. For example, the following syntax would set the function callbackfun as the callback function.
callback = callbackfunThe callback function will then be called every time a new Job result has been streamed from the Techila Server to End-User. The callback function will automatically receive one input argument, which will contain the result returned from the function that was executed on the Worker.
Values returned by the callback function will be stored as elements in the list that will be returned by the peach-function.
The implementation of the Streaming and Callback features will be demonstrated using the Monte Carlo Pi method. In the distributed version of the program, Job results will be streamed as soon as they have become available. The callback function is used to print the approximated value of Pi each time a new result has been received.
5.2.1. Local Control Code
The Python script containing the Local Control Code for this example is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_features_streaming_callback
# Copyright Techila Technologies Ltd.
# This Python script contains the Local Control Code, which will be
# used to distribute computations to the Techila environment.
#
# The Python script named 'mcpi_dist.py' will be distributed to
# Workers, where the function mcpi_dist will be executed according to
# the defined input parameters.
#
# The peachvector will be used to control the number of Jobs in the
# Project.
#
# Results will be streamed from the Workers in the order they will be
# completed. Results will be visualized by displaying intermediate
# results on the screen.
#
# Usage:
# result = run_streaming(jobs, loops)
# jobs: number of Jobs in the Project
# loops: number of iterations performed in each Job
#
# Example:
# result = run_streaming(10, 10000000)
# Load the techila library
import techila
# This is the callback function, which will be executed once for each
# Job result received from the Techila environment.
def callbackfun(jobresult):
global total_jobs
global total_loops
global total_count
total_jobs = total_jobs + 1 # Update the number of Job results processed
total_loops = total_loops + int(jobresult.get('loops')) # Update the number of Monte Carlo loops performed
total_count = total_count + int(jobresult.get('count'))# Update the number of points within the unitary circle
result = 4 * float(total_count) / total_loops # Update the Pi value approximation
# Display intermediate results
print('Number of results included:', total_jobs, 'Estimated value of Pi:', result)
return(jobresult)
# When executed, this function will create the computational Project
# by using peach.
def run_streaming(jobs, loops):
global total_jobs
global total_loops
global total_count
# Initialize the global variables to zero.
total_jobs = 0
total_loops = 0
total_count = 0
result = techila.peach(funcname = 'mcpi_dist', # Name of the executable function
params = [loops], # Input parameters for the executable function
files = ['mcpi_dist.py'], # Files for the executable function
peachvector = range(1, jobs + 1), # Length of the peachvector will determine the number of Jobs in the Project
stream = True, # Enable streaming
callback = callbackfun, # Name of the callback function
)
return(result)The Local Control Code used in this example contains of two functions, run_streaming and callbackfun.
The run_streaming function contains the peach-function call, which will be used to distribute the computations using the peach-function. The syntax of the peach-function defines that individual Job results should be streamed (stream = True) and that the results should be processed by using a callback function ('callback=callbackfun').
The function callbackfun is the callback function that will be executed every time a new Job result is streamed from the Techila Server to your computer. This function is used to combine the individual results and to display the approximation result each time a new Job result has been received.
The input argument of the callback function (jobresult) will be a dict object, which is returned by the code that is executed on the Workers. In this example, the object will contain the number of points inside the unitary circle (count) and the number of iterations performed in the Job (loops). The values returned from Jobs will be added together and stored in the global variables (variables starting with total_) in order to preserve the values between function calls.
Each time a new Job result has been processed, the current value of the approximation will be displayed. The callback function will return the individual Job results in the same format as they were received. These returned values will be stored as a list element in the list returned by the peach-function.
5.2.2. Worker Code
The Worker Code used in this example is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_features_streaming_callback
# Copyright Techila Technologies Ltd.
# This Python scrip contains the Worker Code, which will be
# distributed and evaluated on the Workers. The values of the input
# argument will be set according to the parameters defined in the Local
# Control Code.
import random
# Function that will be executed on Workers.
def mcpi_dist(loops):
count = 0 # No random points generated yet, init to 0.
i = 0
while i < loops:
if pow(pow(random.random(), 2) + pow(random.random(), 2), 0.5) < 1:
count = count + 1
i = i + 1
return({'count': count, 'loops': loops}) # Return the results as a dict objectThe code is similar to the basic implementation introduced in Monte Carlo Pi with Peach. The differentiating factor is that the function returns a dict object, which will contain the number of iterations performed in the Job (loops) and the number of points within the unitary circle (count). This object will be automatically passed as an input argument to the callback function callbackfun defined in the Local Control Code.
5.2.3. Creating the computational project
To create the computational Project, change your current working directory (in Python) to the directory that contains the example material for this example.
After having navigated to the correct directory, create the computational Project using commands shown below:
from run_streaming import *
result = run_streaming(20,1000000)This will create a computational Project consisting of 20 Jobs, each Job performing a Monte Carlo routine that consists of 1,000,000 iterations. Results will be streamed from the Techila Server to End-User as they are completed and the approximated value continuously as more results are streamed.
5.3. Job Input Files
Job Input Files can be used in scenarios, where individual Jobs only require access to some files in a larger dataset. Job-specific input files will be stored in a Job Input Bundle and will be transferred to the Techila Server. Techila Server will transfer files from the Bundle to the Workers requiring them. These files will be stored on the Worker in the temporary working directory for the duration of the Job. The files will be removed from the Worker as soon as the Job has completed.
The material used in this example is located in the following folder in the Techila SDK:
-
techila\examples\Python\features\job_input_files
The names of Job-specific input files that you wish to transfer to Workers are defined by using the jobinputfiles parameter. This parameter is a dictionary object which has the following keywords:
-
The
datafileskeyword is used to define a list of files that should be transferred to Workers. -
The
filenameskeyword is used to define the name of the file on the Workers -
The
datadirkeyword can be used to specify the path where the files are located on your computer. If not defined, files will be accessed from the current working directory.
An example of a jobinputfiles parameter definition is shown below:
jobinputfiles = {'datafiles' : ['file1', 'file2'],
'filenames' : ['workername']}The syntax shown above would transfer file file1 to Job #1 and file file2 to Job #2. Both files would be renamed to workername after they have been transferred to Workers.
Note! When using Job-specific input files, the number of entries in the datafiles parameter must be equal to the number of Jobs in the Project.
If the files you wish to transfer are not located in the current working directory, the path of the file needs to be specified. For example, the following syntax would transfer file1 from the directory C:\temp.
jobinputfiles = {'datafiles' : ['file1'],
'datadir' : 'C:\\temp\\',
'filenames' : ['workername']}The use of Job input Files is illustrated using four text files. Each of the text files contains one row of numbers, which will be summed and the value of the summation will be returned as the result. The computational work performed in this example is trivial and is only intended to illustrate the mechanism of using Job-Specific Input Files.
5.3.1. Local Control Code
The Local Control Code for creating a project that uses Job-Specific Input Files is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_features_job_input_files
# Copyright Techila Technologies Ltd.
# This function contains the Local Control Code, which will be used to
# distribute computations to the Techila environment.
#
# The Python script named 'inputfiles_dist.py' will be distributed and
# evaluated on Workers. Job specific input files will be transferred
# with each Job, each Job receiving one input file.
#
# Usage:
# result = run_inputfiles()
#
# Note: The number of Jobs in the Project will be automatically set to 4.
# Load the techila library
import techila
def run_inputfiles():
# Will be used to set the number of jobs to 4 to match the number of input files
jobs = 4
result = techila.peach(funcname = 'inputfiles_dist', # Name of the executable function
files = ['inputfiles_dist.py'], # Files that will be evaluated on Workers
jobs = jobs, # Set the number of Jobs to 4
jobinputfiles = { # Job Input Bundle
'datafiles' : [ # Files for the Job Input Bundle
'input1.txt', # File input1.txt for Job 1
'input2.txt', # File input2.txt for Job 2
'input3.txt', # File input3.txt for Job 3
'input4.txt' # File input4.txt for Job 4
],
'filenames' : ['input.txt'] # Name of the file on the Worker
},
)
return resultThe peach-function syntax used in the example will create a Project consisting of four Jobs. Each of the Jobs will receive one of input files specified in the jobinputfiles parameter. File input1.txt will be transferred to with Job #1, file input2.txt is transferred with Job #2 and so on. Note that the number of entries in the list is equal to the number Jobs in the Project.
After the files have been transferred to Workers, they will be copied to the same temporary working directory with the executable code. Each file will also be renamed to input.txt during this process.
5.3.2. Worker Code
Worker Code used to perform operations on the Job-specific input files is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_features_job_input_files
# Copyright Techila Technologies Ltd.
# This file contains the Worker Code, which will be distributed
# and evaluated on the Workers. The Jobs will access their Job-specific
# input files with the name 'input.txt', which is defined in the Local
# Control Code
# Import required packages
import csv
# The function that will be executed in each Job
def inputfiles_dist():
# Read the file 'input.txt' from the temporary working directory.
data = list(csv.reader(open('input.txt', 'r'), delimiter=' '))
# Sum the values onthe row.
row_int = map(int,data[0]) # Convert to integers
sum_row_int = sum(row_int) # Sum the values on the row
return(sum_row_int) # Return summation as the resultIn this example, all Jobs will access the input files by using the file name input.txt which was defined in the Local Control Code. These files will be accessed from the same temporary working directory that contains the executable code, meaning no path definitions will be required. Each Job will sum the numbers in the Job-specific input file and return the value of the summation as the result.
5.3.3. Creating the computational project
To create the computational Project, change your current working directory (in Python) to the directory that contains the example material for this example.
After having navigated to the correct directory, create the computational Project using commands shown below:
from run_inputfiles import *
result = run_inputfiles()This will create a Project consisting of four Jobs. The system will automatically assign a Job-specific input file to each Job, according to definition of the jobinputfiles parameter in the Local Control Code. This is illustrated below.
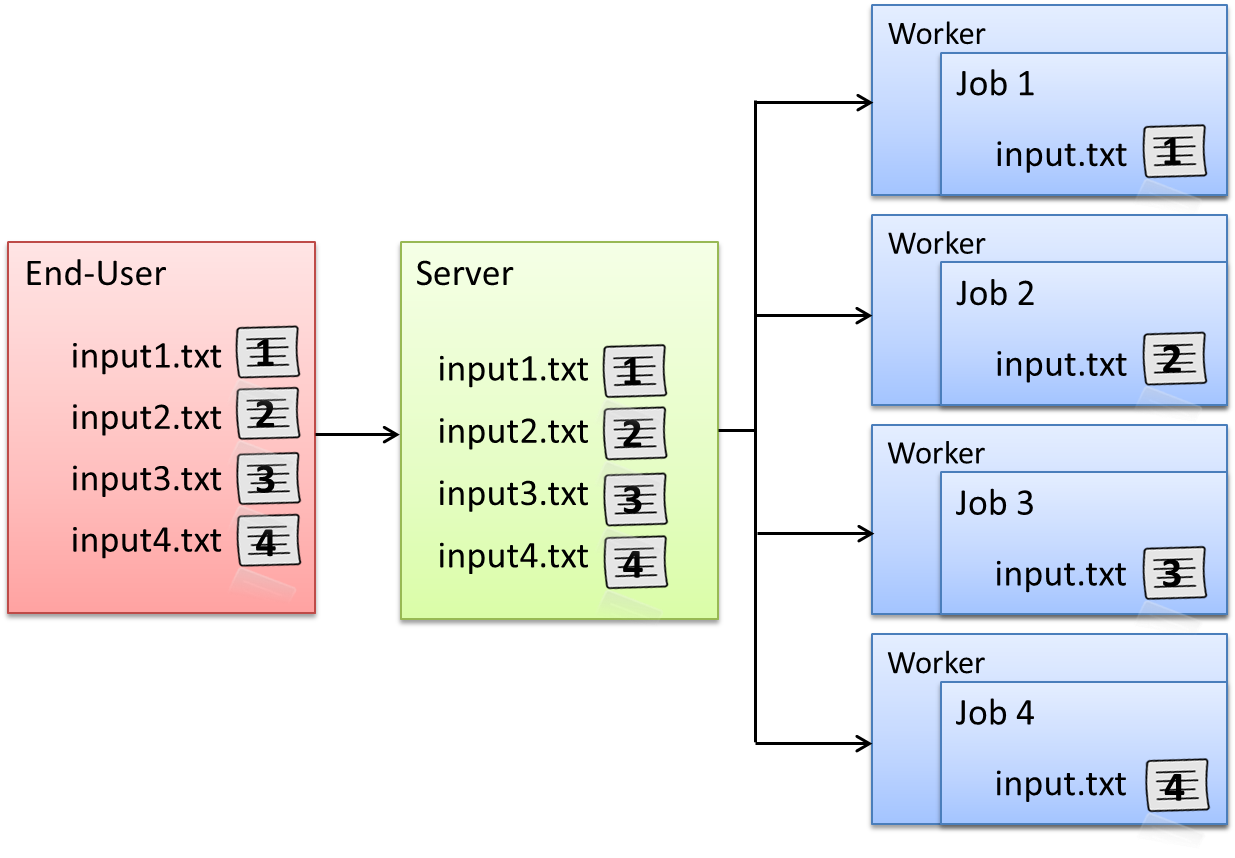
input.txt and copied to a temporary working directory on the Workers.5.4. Project Detaching
When a Project is detached, the peach-function will return immediately after all of the computational data has been transferred to the Server. This means that Python can be used for other purposes while the Project is being computed. Results of a Project can be downloaded later by performing another peach-function call that will link to the Project ID number of the Project that was created earlier.
The material used in this example is located in the following folder in the Techila SDK:
-
techila\examples\Python\Features\detached_project
Projects can be detached using following parameter:
donotwait = True
This will cause the peach-function to return immediately after the Project has been created and all computational data transferred to the Techila Server. The peach-function call will return the Project ID number, which can be used in the download process.
Results can be downloaded by linking the peach-function call to an existing Project ID number using following parameter pair:
projectid = <pid>
The <pid> notation should be replaced by the Project ID number of the Project you wish to download the results for. For example, the following syntax would download results of Project 1466.
projectid = 1466
It is also possible to download results of a previously completed Project, even when the original Project was not detached with the donotwait parameter. Please note however that results can only be downloaded if they have not been removed from the Techila Server. Project ID numbers of previously completed Projects can be viewed from the Techila Web Interface.
The following example demonstrates how to detach a Project and download results using the peach-function.
5.4.1. Local Control Code
The Local Control Code (run_detached.py) used in this example is shown below.
# Example documentation: https://docs.techilatechnologies.com/help/techila-distributed-computing-engine/python-techila-distributed-computing-engine.html#_project_detaching
# Copyright Techila Technologies Ltd.
# This file contains the Local Control Code, which contains two
# functions:
#
# * run_detached - used to create the computational Project.
# * download_result - used to download the results
#
# The run_detached function will return immediately after all
# necessary computational data has been transferred to the server. The
# function will return the Project ID of the Project that was created.
#
# Usage:
#
# Create Project with command:
# pid = run_detached(jobs, loops)
#
# jobs = number of jobs
# loops = number of iterations performed in each Job
#
# Download results with command:
# result = download_result(pid)
#
# pid = Project ID number
# Load the techila library
import techila
# Function for creating the computational Project
def run_detached(jobs, loops):
pid = techila.peach(funcname = 'mcpi_dist', # Function that will be executed on Workers
params = [loops], # Input parameters for the executable function
files = ['mcpi_dist.py'], # Files that will be sourced on Workers
peachvector = range(1, jobs + 1), # Length of the peachvector determines the number of Jobs.
donotwait = True, # Detach project and return the Project ID number
)
return(pid)
# Function for downloading the results of a previously completed Project
def download_result(pid):
results = techila.peach(projectid = pid) # Link to an existing Project.
points = 0 # Initialize result counter to zero
for res in results: # Process each Job result
points = points + int(res.get('count')) # Calculate the total number of points within the unitary
result = 4 * float(points) / (len(results) * int(results[0].get('loops'))) # Calculate the approximated value of Pi
return(result)The code contains two functions, run_detached and download_result.
The run_detached function contains the peach-function call, which will be used to create the computational Project. The peach-function syntax contains the following parameter that specifies that the Project should be detached after all necessary data has been transferred to the Techila Server.
donotwait = True
This parameter will also cause the peach-function to return the Project ID number of the Project that was created. This Project ID number will be stored in the variable pid and will be used later when downloading the results for the Project.
After creating the Project, the download_result function can be used to download the results. This function takes one input argument (pid), which will be used to link the peach-function call to a previously created Project.
After results have been downloaded, the results will be stored in the results list. Each list element will contain the result returned from one Job. The list elements will then be combined and used to calculate an approximated value for Pi.
5.4.2. Worker Code
The code that is executed on the Workers is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_features_detached_project
# Copyright Techila Technologies Ltd.
# This Python scrip contains the Worker Code, which will be
# distributed and evaluated on the Workers. The value of the input
# parameter will be received from the parameters defined in the Local
# Control Code.
# Import necessary packages
import random
def mcpi_dist(loops):
count = 0 # No random points generated yet, init to 0.
i = 0
while i < loops:
if pow(pow(random.random(), 2) + pow(random.random(), 2), 0.5) < 1:
count = count + 1
i = i + 1
return({'count': count, 'loops': loops}) # Return the results as a listThe code used in this example performs the same Monte Carlo routine as in the basic implementation introduced in Monte Carlo Pi with Peach. The differentiating factor is that the function returns a dict object, which will contain the number of iterations performed in the Job (loops) and the number of points within the unitary circle (count).
The number of iterations is stored in order to preserve information that is required in the post-processing. Storing all variables required in post-processing in the result files means, that the post-processing activities can be performed correctly regardless of when the results are downloaded.
5.4.3. Creating the computational Project and downloading results
To create the computational Project, change your current working directory (in Python) to the directory that contains the example material for this example.
After having navigated to the correct directory, create the computational Project using commands shown below:
from run_detached import *
pid = run_detached(10,10000000)This creates a Project consisting of ten Jobs. After all of the computational data has been transferred to the Techila Server, the Project ID number will be returned and stored to the 'pid' variable. This Project ID number can be used to download the results of the Project after all the Jobs have been completed.
After the Project has been completed, the results can be downloaded from the Techila Server with the download_result function using the syntax shown below. Please note that if you execute the function before the Project has been completed, the peach-function will wait for the Project to be completed.
results = download_result(pid)
5.5. Iterative Projects
Creating Projects iteratively is not so much as a feature as it is a technique. Using this type of an approach is typically used in scenarios where output values of previously completed Projects will be used as input values in future Projects. Creating several consecutive Projects can be achieved by for example placing the peach-function call inside a loop structure.
The material used in this example is located in the following folder in the Techila SDK:
-
techila\examples\python\Features\iterative_projects
5.5.1. Local Control Code
The Local Control Code used to create several, consecutively created projects is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_features_iterative_projects
# Copyright Techila Technologies Ltd.
# This Python script contains the Local Control Code, which will be
# used to distribute computations to the Techila environment.
#
# The Python script named 'mcpi_dist.py' will be distributed and
# evaluated Workers. Several consecutive Projects will be created,
# during which the value of Pi will be calculated using the Monte
# Carlo method. Results of the Projects will be used to improve the
# accuracy of the approximation. Projects will be created until the
# amount of error in the approximation is below the threshold value.
#
# Usage:
# result=run_iterative()
#
# Note: The number of Jobs in the Project will be automatically set to
# 20.
import math
import techila
def run_iterative():
threshold = 0.00004 # Maximum allowed error
jobs = 20 # Number of Jobs
loops = 1e7 # Number of iterations performed in each Job
total_result = 0 # Initial result when no approximations have been performed.
iteration = 1 # Project counter, first Project will
current_error = math.pi # Initial error, no approximations have been performed
techila.init()
while abs(current_error) >= threshold:
result = techila.peach(
funcname = 'mcpi_dist', # Function that will be executed
params = [loops, '<param>', iteration], # Input parameters for the executable function
files = ['mcpi_dist.py'], # Files that will be evaluated on Workers
peachvector = range(1, jobs + 1), # Length of the peachvector is 20 -> set the number of Jobs to 20
messages = False, # Disable message printing
)
# If result is None after peach exits, stop creating projects.
if result == None or len(result) == 0:
break
total_result = total_result + sum(result) # Update the total result based on the project results
approximated_pi = float(total_result) * 4 / (loops * jobs * iteration) # Update the approximation value
current_error = approximated_pi - math.pi # Calculate the current error in the approximation
print('Amount of error in the approximation = ', current_error) # Display the amount of current error
iteration = iteration + 1 # Store the number of completed projects
# Display notification after the threshold value has been reached
print('Error below threshold, no more Projects needed.')
techila.uninit()
return current_errorThe Local Control Code used in this example contains three logical steps:
-
Step 1: Initializing the connection to the Techila Server
-
Step 2: Iterative Project creation
-
Step 3: Uninitializing the connection
These steps are explained below:
Step 1: The connection to the Techila Server will be initialized by calling the init function before performing the peach-function call. When init is called before the peach-function, the peach-function will not uninitialize the connection after downloading the results. This means that the connection will remain available for subsequent peach-function calls. This also means that when creating several consecutive Projects, performing a separate connection initialization is typically more efficient than performing a new initialization with each peach-function call.
Step 2: The peach-function call used to create the computational Projects is placed inside a loop structure, which is implemented with a while statement. Each computational Project will be used to compute an approximation for the value of Pi. The results generated in the Projects will be combined and compared to the value of Pi (math.pi) to compute the current error in the approximation.
New computational Projects will be created until the error in the approximation is below the predefined threshold value. The amount of error in the approximation will be printed every time a new Project has been completed. Note that messages have been disabled (messages = False) in order to provide a more clear illustration of the results received from Projects.
Step 3: After the error in the approximation drops below the threshold, the loop structure will be exited. The connection to the Techila Server will be uninitialized by using the uninit function, which will also remove all temporary files created by the peach-function.
The run_iterative-function will return the amount of error in the approximation after all Projects have been completed.
5.5.2. Worker Code
The algorithm for the Worker Code is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_features_iterative_projects
# Copyright Techila Technologies Ltd.
# This Python scrip contains the Worker Code, which will be
# distributed and sourced on the Workers. The values of the input
# parameters will be received from the parameters defined in the Local
# Control Code.
import random
def mcpi_dist(loops, jobidx, iteration):
random.seed(jobidx * iteration)
count = 0 # No random points generated yet, init to 0.
i = 0
while i < loops:
if pow(pow(random.random(), 2) + pow(random.random(), 2), 0.5) < 1:
count = count + 1
i = i + 1
return count # Return the results as a listThe executable function takes three input arguments: loops, jobidx and iteration. The loops variable is used to define the number of iterations performed in the while-loop. The jobidx and iteration variables are used to specify the seed of the random number generator. This is done in order to ensure that the number of required Projects required stays within a reasonable limit.
Apart from the modifications described above, the computational operations performed in the Worker Code are similar as in the basic implementation presented in Monte Carlo Pi with Peach, returning the number of random points that are located within the unitary circle.
5.5.3. Creating the computation Project
To create the computational Projects, change your current working directory (in Python) to the directory that contains the example material relevant to this example.
After having browsed to the correct directory, create the computational Projects using commands:
from run_iterative import *
result=run_iterative()Executing the commands shown above will create several, consecutively created Projects each consisting of 20 Jobs. New Projects will be created until the error in approximation is smaller than the threshold value. The error of the approximation will be printed every time a Project has been completed.
5.6. Data Bundles
Data Bundles can be used to efficiently transfer and manage large amounts of data in computational Projects. After being created, Data Bundles will be stored on the Techila Server from where they will be automatically used in future Projects, assuming that the content of the Data Bundle does not change. If the content of the Data Bundle changes (e.g. new files added, existing files removed or the content of existing files modified), a new Data Bundle will be automatically created and transferred to the Techila Server.
The material used in this example is located in the following folder in the Techila SDK:
-
techila\examples\python\Features\data_bundle
Files can be stored in Data Bundles by using the databundle parameter. For example, the syntax shown below would store files called file1 and file2 in to a Data Bundle
databundles = [{'datafiles' : ['file1','file2']}]The listed files will be transferred to Workers, where they will be copied to the same temporary working directory with the executable code.
An expiration period can be defined for the Data Bundle, which will determine the time period how long an unused Bundle will be stored on a Worker. If a value is not defined, the default expiration periods will be used. For example, an expiration period of 30 minutes can be defined with the following syntax:
databundles = [{'datafiles' : ['file1','file2'],
'parameters' : {'ExpirationPeriod' : '30 m'}}]Several Data Bundles can be created by defining additional list entries for the databundles parameter. For example, the syntax shown below would create two Data Bundles. The first Data Bundle contains files file1 and file2 and the second Data Bundle contains files file3 and file4.
databundles = [{'datafiles' : ['file1','file2']},
{'datafiles' : ['file3','file4']}]By default, the files listed in the datafiles parameter will be read from the current working directory. If the files are not located in the current working directory, the path of the files can be defined with the datadir parameter. For example, the syntax shown below would read files file1 and file2 from the path C:\temp. Files file3 and file4 would be read from the current working directory.
databundles = [{'datafiles' : ['file1','file2'],
'datadir' : 'C:\\temp'},
{'datafiles' : ['file3','file4']}]This example illustrates how to transfer data files using two Data Bundles
5.6.1. Local Control Code
The Local Control Code used in this example is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_features_data_bundle
# Copyright Techila Technologies Ltd.
# This Python script contains the Local Control Code, which will be used to
# distribute computations to the Techila environment.
#
# The Python script named 'databundle_dist.py' will be distributed and
# evaluated on Workers. Necessary data files will be transferred to Workers
# in Data Bundles.
#
# Usage:
# result = run_databundle()
# Import the techila package
import techila
def run_databundle():
# Create the computational Project with the peach function.
result = techila.peach(
funcname = 'databundle_dist', # Function that will be executed on Workers
files = ['databundle_dist.py'], # Files that will be evaluated on Workers
jobs = 1, # Set the number of Jobs to 1
databundles = [ # Define a databundle
{ # Data Bundle #1
'datadir' : './storage/', # The directory from where files will be read from
'datafiles' : [ # Files for Data Bundle #1
'file1_bundle1',
'file2_bundle1',
],
'parameters' : { # Parameters for Data Bundle #1
'ExpirationPeriod' : '60 m', # Remove the Bundle from Workers if not used in 60 minutes
}
},
{ # Data Bundle #2
'datafiles' : [ # Files for Data Bundle #2, from the current working directory
'file1_bundle2',
'file2_bundle2',
],
'parameters' : { # Parameters for Data Bundle #2
'ExpirationPeriod' : '30 m', # Remove the Bundle from Workers if not used in 30 minutes
}
}
]
)
return(result)The Local Control Code used in this example will create two Data Bundles. Files file1_bundle1 and file2_bundle1 will be read from a folder called storage and stored in the first Data Bundle. Files file1_bundle2 and file2_bundle2 will be read from the current working directory and stored in the second Data Bundle. Expiration periods of the Data Bundles will be set to 60 minutes for the first Bundle and 30 minutes for the second Bundle.
5.6.2. Worker Code
The Worker Code used in this example is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_features_data_bundle
# Copyright Techila Technologies Ltd.
# This function contains the Worker Code, which will be distributed
# and executed on the Workers. The databundle_dist function will
# access each file stored in two databundles and return results based
# on the values in the files.
import csv
# The function that will be executed on Workers.
def databundle_dist():
# Read the files from temporary working directory.
a = list(csv.reader(open('file1_bundle1', 'r'), delimiter=' '))
b = list(csv.reader(open('file2_bundle1', 'r'), delimiter=' '))
c = list(csv.reader(open('file1_bundle2', 'r'), delimiter=' '))
d = list(csv.reader(open('file2_bundle2', 'r'), delimiter=' '))
# Cast values to integers
a_int = map(int,a[0])
b_int = map(int,b[0])
c_int = map(int,c[0])
d_int = map(int,d[0])
return([a_int,b_int,c_int,d_int]) # Return values in a listThe Worker Code contains instruction for reading each of the files included in the Data Bundles. The files in the Data Bundles will be copied to the same temporary working directory as the executable Python code, meaning the files can be accessed without any additional path definitions.
After reading the files, the executable function will return a list containing the values read from the files. The value returned from the Job will be eventually returned by the peach-function defined in the Local Control Code.
5.6.3. Creating the computational Project
To create the computational Project, change your current working directory (in Python) to the directory that contains the example material for this example.
After having navigated to the correct directory, create the computational Project using commands shown below:
from run_databundle import *
result = run_databundle()This creates a Project consisting of one (1) Job. Two Data Bundles will be created and transferred to the Techila Server, from where they will be transferred to the Worker. Please note that if you execute the Local Control Code several times, the Data Bundles will only be created with the first Project. Any subsequent Projects will use the Data Bundles stored on the Techila Server.
5.7. Function handle
Function handles (pointers to another function) can be used as values for the funcname parameter. When passing a function handle as a value to the funcname parameter, no separate Python script for the Worker Code will be required. This means that the files parameter does not need to be defined.
The material used in this example is located in the following folder in the Techila SDK:
-
techila\examples\python\Features\function_handle
Function handles can be used for defining the executable function using the syntax shown below:
funcname = <function handle>
The <function handle> notation should be replaced with the function you wish to execute on Workers. For example, the following syntax would execute a function called testfun on all Workers.
funcname = testfun
Please note that the function needs to be defined, before it can be used as the value of the funcname parameter. Also note that when referring to a function handle, quotation marks are not used. If the function performs calls to additional functions, these functions will not be available on the Worker. In order to make multiple functions available, please use the files parameter.
If the function you want to execute in Jobs has dependencies to other functions, these dependencies can be defined by using the funclist parameter. For example, the following syntax could be used to transfer a function called myfunc1 to the the Techila Distributed Computing Engine environment. With these parameters, you would be able to call myfunc1 from testfun.
funcname = testfun, funclist = [myfunc1]
Multiple function dependencies can be transferred by listing the functions as a comma separated list. For example, the example syntax below could be used to transfer functions called myfunc1 and myfunc2.
funclist = [myfunc1, myfunc2]
This example illustrates how to use the funcname parameter to execute a function that is defined in the local Python environment on the Workers.
5.7.1. Local Control Code
The Local Control Code used in this example is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_features_function_handle
# Copyright Techila Technologies Ltd.
# This Python contains the Local Control Code, which will be used to
# distribute computations to the Techila environment.
#
# Usage:
# result = run_funchandle(jobcount,loops)
#
# jobcount: number of Jobs in the Project
# loops: number of Monte Carlo approximations performed per Job
#
# Example:
# result = run_funchandle(10, 100000)
import random
import techila
# This function executed on Workers. The values of the input parameters will be
# received from the parameters defined in the Local Control Code.
def mcpi_dist(loops):
count = 0
i = 0
while i < loops:
if point_dist() < 1:
count = count + 1
i = i + 1
return count
# This is a subfunction called from mcpi_dist and executed also on Workers.
def point_dist():
return pow(pow(random.random(), 2) + pow(random.random(), 2), 0.5)
# This function will distribute create the computational Project by
# using peach.
def run_funchandle(jobcount, loops):
result = techila.peach(funcname = mcpi_dist, # Execute the mcpi_dist-function on Workers
funclist = [point_dist], # Additional function required on Workers
params = [loops], # Input argument to the mcpi_dist-function
jobs=jobcount, # Number of Jobs in the Project
)
# Calculate the approximated value of Pi
result = 4 * float(sum(result)) / (jobcount * loops)
# Display results
print('The approximated value of Pi is:', result)
return resultThe Local Control Code shown above defines two functions; mcpi_dist and run_funchandle.
The run_funchandle-function contains the peach-function call that will be used to create the computational Project. The funcname parameter of the peach-function call refers to the mcpi_dist-function and is entered without quotation marks.
An additional function dependency has beed defined by using the funclist parameter. With the syntax used in this example, the point_dist function will also be transferred to the Techila Distributed Computing Engine environment and can be used during the computational Jobs.
The mcpi_dist-function contains the executable code that will be executed on Workers to start the computational Jobs. During the computational Job, the point_dist function is used to generate the random points.
Please note that the files parameter is not used, meaning that no Python scripts will be sourced during the preliminary stages of a computational Job.
5.7.2. Creating the computational Project
To create the computational Project, change your current working directory in your Python environment to the directory that contains the example material for this example.
After having navigated to the correct directory, create the computational Project using commands shown below:
from run_funchandle import *
result = run_funchandle(10,1000000)This will create a Project consisting of ten Jobs, each Job performing 1,000,000 iterations of the Monte Carlo routine defined in the mcpi_dist function. The values returned from the Jobs will be used to calculate an approximate value for Pi.
5.8. File Handler
The file handler is a function that can be used to process additional output files after they have been transferred to the End-Users computer from the Techila Server. The file handler function can be used for example to transfer the files to suitable directories or to perform other post-processing activities.
The material used in this example is located in the following folder in the Techila SDK:
-
techila\examples\python\Features\file_handler
Additional output files and the file handler function
In order to return additional output files generated on Workers, the output files need to be defined in the peach-function syntax by using the outputfiles parameter. For example, the following syntax would transfer an output file called output_file1 from the Workers to your computer.
outputfiles = ['output_file1']Several files can be transferred from Workers by defining the names of the files as list elements. For example, the following syntax would specify that two files called output_file1 and output_file2 should be returned from Workers.
outputfiles = ['output_file1','output_file2']If the names of the output files that are generated on Workers are different for each Job, regexp notations can be used to return all files matching the specified filter. For example, the following syntax would return all files starting with the string output_file from the Workers.
outputfiles = ['output_file.*;regex=1']Each output file that is transferred to your computer can be processed by a file handler function, which is defined in the Local Control Code. The file handler function will be called once for each transferred file and takes one input argument, which will automatically contain the path and name of the file.
The name of the function that will be called for each output file is defined with the filehandler parameter. For example, the following syntax specifies that a function called filehandler_func should be used as the file handler function.
filehandler=filehandler_funcBy default, the file handler function will be given the name of the outputfile the first input argument. Additionally, the file handler function can be give optional keyword arguments jobid, jobidx, pid as shown in the example snippet below:
def filehandler_func(file,jobid=jobid,jobidx=jobidx,pid=pid)This example illustrates how to process additional output files generated during computational Jobs by using a file handler function
5.8.1. Local Control Code
The Local Control Code used in this example is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_features_file_handler
# Copyright Techila Technologies Ltd.
# This script contains the Local Control Code, which will be used to create the
# computational Project and post-process the output files.
#
# Usage:
# run_filehandler()
# Import the techila package
import techila
# Load other necessary packages
import os
import shutil
# This function is the filehandler function, which will be
# used to post-process the output files. Function will be called once for
# each output file.
def filehandler_func(file):
# Display the location of the file on the End-Users computer
print(file)
# Display contents of the file
f = open(file, 'r')
line = f.readline()
print(line)
f.close()
# Copy the file to the current working directory
filename = os.path.basename(file)
shutil.copy(file, os.getcwd())
# This function contains the peach function call, which will be
# used to create the computational Project
def run_filehandler():
jobs = 5 # Will be used to set the number of Jobs to 5
result = techila.peach(funcname = 'worker_dist', # Function that will be called on Workers
files = 'worker_dist.py', # Files that will be sourced on Workers
params = ['<param>'], # Input parameters for the executable function
peachvector = range(1, jobs+1), # Set the number of Jobs to 5
outputfiles = ['output_file.*;regex=1'], # Files to returned from Workers
filehandler = filehandler_func, # Name of the filehandler function
)In the peach-function syntax shown above, regexp notations have been used to specify all files starting with the string output_file as output files. These files will be transferred from the Workers to your computer. The regexp notation is required, because each of the output files will have a different name.
After the files have been transferred to your computer, the filehandler_func function will be used to process each of the output files. The filehandler_func will be called once for each output file. Each time the function is called, the value of the input argument (variable file) will be automatically replaced with the name and path of output file. In this example, the file handler function will be used to print the path and name of the file and to copy the file to the current working directory.
5.8.2. Worker Code
The Worker Code used in this example is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_features_file_handler
# Copyright Techila Technologies Ltd.
# This function contains the function that will be executed
# during computational Jobs. Each Job will generate one output file, which
# will be named according to the value of the 'jobidx' variable.
def worker_dist(jobidx):
# Generate a sample string that will be stored in the output file
sample1 = 'This file was generated in Job: ' + str(jobidx)
# Create the output file
f = open('output_file' + str(jobidx), 'w')
# Write the string the output file
f.write(sample1)
f.closeEach Job in the computational Project will generate one output file. The name of the output file will include the value of the input argument jobidx, meaning the name of the file will be different for each Job. Job #1 will generate a file called output_file1, Job #2 will generate a file called output_file2 and so on. The names of all generated output files will match the regexp filter defined in the Local Control Code, meaning all files will be transferred to the End-Users computer.
5.8.3. Creating the computational Project
To create the computational Project, change your current working directory (in Python) to the directory that contains the example material for this example.
After having navigated to the correct directory, create the computational Project using commands shown below:
from run_filehandler import *
run_filehandler()This creates a Project consisting of five Jobs. Each Job will generate one additional output file, which will be processed by the file handler function. The file handler function will display the temporary locations and content of each output file. The files will be copied to the current working directory as can be seen from the output generated by the listdir function.
5.9. Snapshots
Snapshotting is a mechanism where intermediate results of computations are stored in snapshot files and transferred to the Techila Server at regular intervals. Snapshotting can be used to improve the fault tolerance of computations and to reduce the amount of computational time lost due to interruptions.
Snapshotting is performed by storing the state of the computation (i.e. variables required to resume computations) at regular intervals in snapshot files on the Worker. The snapshot files will then be automatically transferred to the Techila Server at regular intervals from the Workers. If an interruption should occur, these snapshot files will be transferred to other available Workers, where the computational process can be resumed by using the intermediate results stored in the snapshot file.
The material used in this example is located in the following folder in the Techila SDK:
-
techila\examples\python\Features\snapshot
In order to use snapshots in Python, the following import command needs to be added to the Worker Code:
from peachclient import load_snapshot, save_snapshotAdditionally, the following parameter pair will need to be added to the Local Control Code:
snapshot=TrueThe default values will define the following snapshot parameters:
-
The name of the snapshot file (
snapshot.dat) -
The transfer interval of the snapshot file (15 minutes)
Variables that you wish to store in the snapshot file will need to be declared global in the code that is executed on Workers. After declaring the variables global, they can be saved by using the save_snapshot function in the Worker Code. For example, the following syntax would store the variables var1 and var2 in the snapshot file.
save_snapshot(var1,var2)The variables will be stored in the snapshot file (snapshot.dat), which will be transferred to the Techila Server after preconfigured time intervals. This file will be automatically transferred to a Worker if the computational Job becomes interrupted and needs to be assigned to another Worker.
Variables stored in a snapshot file can be loaded by using the load_snapshot function in the Worker Code. For example, the following command loads all variables stored in the snapshot file.
load_snapshot()The default snapshot transfer interval in Python is 15 minutes. The snapshot transfer interval can be modified with the snapshotinterval parameter. For example, the syntax shown below will set the transfer interval to five (5) minutes.
snapshotinterval=5This example demonstrates how to store and load variables into and from snapshot files.
5.9.1. Local Control Code
The Local Control Code used in this example is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_features_snapshot
# Copyright Techila Technologies Ltd.
# This function contains the Local Control Code, which will be used to
# distribute computations to the Techila environment.
#
# The Python script named 'snapshot_dist.py' will be distributed to
# Workers, where the function snapshot_dist will be executed according
# to the specified input parameters. The peachvector will be used to
# control the number of Jobs in the Project.
#
# Snapshotting will be implemented with the default values, as the
# Local Control Code does not specify otherwise.
#
# To create the Project, use command:
#
# result = run_snapshot(jobs, loops)
#
# jobs = number of jobs
# loops = number of iterations performed in each Job
#
# Example:
# result = run_snapshot(10, 1000000)
# Load the techila library
import techila
# This function will create the computational Project by using peach.
def run_snapshot(jobs, loops):
result = techila.peach(
funcname = 'snapshot_dist', # Function that will be executed on Workers
params = [loops], # Input parameters for the executable function
files = ['snapshot_dist.py'], # Files that will be sourced on the Workers
peachvector = range(1, jobs + 1), # Length of the peachvector will determine the number of Jobs
snapshot = True, # Enable snapshotting
)
# Calculate the approximated value of Pi based on the received results
result = 4 * float(sum(result)) / (jobs * loops)
# Display the results
print('The approximated value of Pi is:', result)
return(result)Snapshots are enabled with the following parameter pair in the Local Control Code:
snapshot=TrueNo other modifications are required the Local Control Code to enable snapshotting with the default snapshot parameters. Apart from the parameter pair used to enable snapshotting, the structure of the Local Control Code is similar to the basic implementation as shown in Monte Carlo Pi with Peach.
5.9.2. Worker Code
The Worker Code used in this example is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_features_snapshot
# Copyright Techila Technologies Ltd.
# This function contains the Worker Code, which will be distributed
# and executed on the Workers. The save_snapshot helper function will
# be used to store intermediate results in the snapshot.dat file. The
# load_snapshot helper function will be used to load snapshot files
# if the job is resumed on another Worker.
import random
from peachclient import load_snapshot, save_snapshot
def snapshot_dist(loops):
# Snapshot variables need to be declared global
global count
global i
count = 0 # Init: No random points generated yet, init to 0.
i = 0 # Init: No iterations have been performed yet, init to 0.
load_snapshot() # Override Init values if snapshot exists
while i < loops:
if pow(pow(random.random(), 2) + pow(random.random(), 2), 0.5) < 1:
count = count + 1
if i > 0 and i % 1e7 == 0: # Snapshot every 1e7 iterations
save_snapshot('i', 'count') # Save intermediate results
i = i + 1
return(count)The snapshot helper functions are imported to the namespace using the following command:
from peachclient import load_snapshot, save_snapshotAfter the import command has been executed, the helper functions can be called in the Worker Code.
During the initial steps in the executable function the count and i variables are declared global and initialized. The initialization values will be used in situations where a snapshot file cannot be found (e.g. when starting the Job). If a snapshot file exists, it will indicate that the Job is being resumed after an interruption. In this case, the content of the snapshot file will be used to override the initialized values. This will be performed using the load_snapshot function, which automatically loads variables stored in the snapshot file to the Python environment. After loading the snapshot file, computations will be resumed from the last iteration value (i) stored in the snapshot file.
Intermediate results will be stored in the snapshot file by calling the save_snapshot function every1e7th iteration. The variables stored in the snapshot file are i and count. The parameter i will contain the number of iterations performed when the snapshot generation occurred. The parameter count will contain the intermediate results.
5.9.3. Creating the computational Project
To create the computational Project, change your current working directory (in Python) to the directory that contains the example material for this example.
After having navigated to the correct directory, create the computational Project using commands shown below:
from run_snapshot import *
result=run_snapshot(10,1e8)This creates a Project consisting of 10 Jobs, each Job performing 1e8 iterations. Intermediate results will be saved at every 1e7th iteration. Snapshot files will be transferred approximately every 30 minutes from the Worker to Techila Server. If a Job is migrated to a new Worker while the Job is being computed, the latest available snapshot file will be automatically transferred from the Techila Server to the new Worker.
Snapshot data can also be viewed and downloaded by using the Techila Web Interface. Instructions for this can be found in the Techila Web Interface End-User Guide.
Note that when using the syntax shown above to run the example, the execution time of single Job is relatively short. This might result in the Job being completed before a snapshot file will be transferred to the Techila Server. If snapshot data is not visible in the Techila Web Interface, consider increasing the amount of iterations to increase the execution time of a Job. You can also experiment by specifying a shorter snapshot interval with the snapshotinterval parameter as explained earlier in this Chapter.
5.10. Using Custom Python Packages in Computational Projects
Custom Python packages can be made available on Workers by either using the packages parameter of the peach-function or by using the bundleit-function to create the Bundle. This Chapter discusses using the bundleit-function in more detail.
The material used in this example is located in the following folder in the Techila SDK:
-
techila\examples\python\Features\custom_package
If you wish to see how the packages parameter is used to create a Bundle, please refer to the file run_packagetest2.py. This file is located in the same directory that contains the example material that uses the bundleit-function.
When using the bundleit-function, Python packages that are not included in the standard Python distribution can be made available on Workers by performing the steps listed below.
-
Step 1: Creating a Bundle from the Python package using the
bundleitfunction -
Step 2: Importing the Bundle in to a computational Project by using the
importsparameter
These steps are described below.
Step 1: Creating the Python Package Bundle
Python packages that are installed on your computer can be stored in Python Package Bundles by using the bundleit function, which is included in the techila package. Bundles that are created with this function will be automatically transferred to the Techila Server and can be imported in to computational Projects.
The general syntax of the bundleit function is shown below:
bundleit(package,
version = None,
all_platforms = False,
expiration = '7 d',
bundlename = None,
sdkroot = None,
initfile = None,
password = None):The input parameters of the function are explained below:
The package parameter defines name of the installed Python package you wish to store in the Bundle and transfer to the Techila Server. For example, the following syntax could be used to transfer a package named techilatest to the Techila Server.
>>> import techila
>>> bundlename=techila.bundleit(package='techilatest')
>>> bundlename
'demouser.Python.v272.package.techilatest.1.0.0'The bundleit function will return the name of the Bundle that was created. In the example shown above, the name will be stored in the variable bundlename. The Bundle name returned by the bundleit function can be used to import the Bundle (Step 2) to a computational project, so it is typically convenient to store the value in a variable for future use. The general naming convention of Bundles created with the bundleit function is illustrated below.
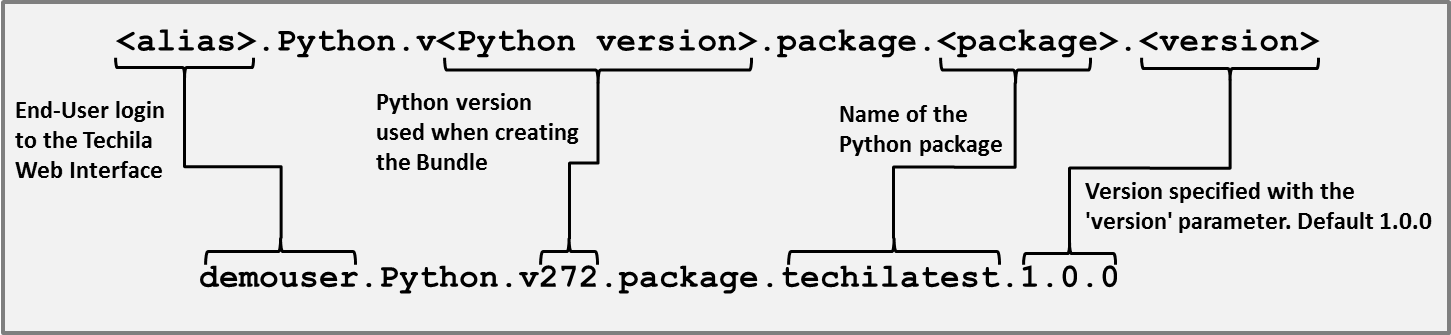
The version parameter can be used to modify the name of the Bundle that will be created. Modifying the name of the Bundle will typically be required if you wish to re-create a Bundle from a Python package that has already been transferred to the Techila Server. This is because all Bundles must have unique names and Bundles with a non-unique name will not be accepted by the Techila Server.
The example below shows how to modify the name of a Bundle with the version parameter.
>>> import techila
>>> bundlename=techila.bundleit(package='techilatest',version='1.0.1')
>>> bundlename
'demouser.Python.v272.package.techilatest.1.0.1'The all_platforms parameter can be used to specify that the Bundle should be offered to all Workers, regardless of the operating system of the Worker. By default, Bundles will only be offered to Workers that have the same operating system type (Linux or Windows) as the one used by the End-User when creating the Bundle. To allow all Workers to use the Bundle, specify the parameter as shown below:
all_platforms=TrueThe `expiration`parameter can be used to specify a different expiration period (default value 7 days) for the Bundle. This expiration period defines how long the Bundle can remain unused on the Worker, before it will be marked for removal. For example, the syntax shown below could be used to set an expiration period of 30 days.
expiration = '30 d'The sdkroot parameter can be used to specify the path of the techila directory on your computer. If you have set the environment variable TECHILA_SDKROOT, using this parameter will not be required.
The initfile parameter can be used to specify the path of the techila_settings.ini file if the file cannot be found from any of the default locations (for example the techila directory or the user home directory).
The password parameter can be used to specify the password of the End-User Keystore. When specified, the password will not be prompted when creating the Bundle.
Step 2: Importing the Bundle
Bundles containing Python packages can be imported to computational Projects by using the imports parameter of the peach-function. The general syntax for defining the parameter is shown below.
imports=['<bundle name>']For example, the following syntax could be used to import the Bundle that was used as an example in Step 1 earlier in this Chapter:
imports=['demouser.Python.v272.package.techilatest.1.0.0']Bundles listed in the imports parameter will be transferred to all Workers that participate in the Project. After being imported, the packages stored in the Bundles can be used normally in the Worker Code.
The following example illustrates how to store a Python package in a Bundle and import the Bundle in a computational Project.
5.10.1. Local Control Code and the techilatest package
In this example, a package called techilatest will be installed on the End-Users computer. This package will then be transferred to the Techila Server by using the bundleit function. The package is located in the same folder that contains the example material for this example and contains one module called functions.py.
The content of the function.py file is shown below. Instructions for installing the package can be found at the end of this Chapter.
# Example documentation: https://docs.techilatechnologies.com/help/techila-distributed-computing-engine/python-techila-distributed-computing-engine.html#_using_custom_python_packages_in_computational_projects
def summation(a, b):
return(a + b)
def multiplication(a, b):
return(a * b)
def subtraction(a, b):
return(a - b)
def division(a, b):
af = float(a)
bf = float(b)
return(af / bf)The functions shown above can be used to perform basic arithmetic operations. Each function takes two input arguments. These functions will be called during the computational Jobs. The input arguments will be defined in the Local Control Code shown below.
The Local Control Code (in file run_packagetest.py) used in this example is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_features_custom_package
# Copyright Techila Technologies Ltd.
# This script contains the Local Control Code containing two function
# definitions.
# These functions can be used to create a Bundle containing the 'techilatest'
# and for creating a computational Project that will import the Bundle.
#
# Usage:
#
# bundlename=create_package()
# result=run_packagetest(bundlename)
#
# Import the techila package
import techila
# The function used to store the 'techilatest' package in a Bundle.
def create_package():
# Create the Bundle from the 'techilatest' package.
bundlename = techila.bundleit('techilatest', all_platforms = True)
print('package bundlename is \'%s\'' % bundlename) # Print the Bundle name
# Return the name of the Bundle.
return(bundlename)
# This function is used to create a computational Project that will import
# the Bundle containing the 'techilatest' package.
def run_packagetest(bundlename):
results = techila.peach(funcname = 'packagetest_dist', # Function executed on Workers
params = ['<vecidx>','<param>'], # Input arguments to the executable function
files = ['packagetest_dist.py'], # File that will be evaluated at the start
imports = [bundlename], # Import the Bundle containing the 'techilatest' package
peachvector = [1, 2, 4, 8, 16], # Peachvector containing five integer elements
)
# Display the results
for row in results:
print(row)The script contains two functions, which will be used to perform the following operations:
The function create_package contains the bundleit-function call, which will be used to create a Bundle from the techilatest package. The function will return the name of the Bundle (bundlename) that was created, which can be used to import the Bundle to the computational Project.
The function run_packagetest contains the peach-function call, which will be used to create the computational Project. The function takes one input argument (bundlename) which will be used to define which Bundle should be imported to the Project (imports = [bundlename]).
The peach-function syntax also defines two input arguments (params=['<vecidx>','<param>']), which will be passed to the executable function. These input arguments will eventually be passed to the functions in the techilatest package.
5.10.2. Worker Code
The Worker Code used in this example is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_features_custom_package
# Copyright Techila Technologies Ltd.
# This script contains the Worker Code, which contains the
# packagetest_dist function that will be executed in each
# computational Job.
# Load the the techilatest module.
import techilatest.functions as test
# Define the function that will be called on Workers
def packagetest_dist(a, b):
# Call the functions defined in the 'techilatest' package
res1 = test.summation(a,b)
res2 = test.multiplication(a,b)
res3 = test.subtraction(a,b)
res4 = test.division(a,b)
# Return results in a list
return([res1, res2, res3, res4])The first line in the Worker Code will load the functions module from the techilatest package. The import can be performed because the Bundle containing the package has been transferred to all participating Workers. After importing the module, the functions can be accessed during the computational Job.
5.10.3. Installing the techilatest package and creating the computational Project
To install the techilatest package, launch a command prompt / terminal and change your current working directory to the directory that contains the example material for this example. Install the package using command:
pip3 install --user .
Executing the command should generate a similar output as shown below (paths may differ).
Processing /home/user/techila/examples/python/Features/custom_package Preparing metadata (setup.py) ... done Installing collected packages: techilatest Running setup.py install for techilatest ... done Successfully installed techilatest-1.0
After installing the package, launch Python and follow the instructions below to run the example.
Evaluate the Python script containing the Local Control Code using command shown below:
from run_packagetest import *After sourcing the file, create a Bundle from the package techilatest using command:
bundlename = create_package()Create a computational Project using command:
result = run_packagetest(bundlename)This will create a Project containing five Jobs. The Bundle containing the techilatest package will be transferred to each participating Worker and the package will be available on these Workers. After the Project has been completed, the values generated in the Jobs will be displayed. Each displayed row contains the values returned from one Job and contains the values returned from the functions in the techilatest package.
5.11. Precompiled Binaries
The Python peach-function can also be used to execute precompiled binaries on Workers. Please note that when executing precompiled binaries on Workers, the syntax for defining input arguments and output files will be different. This is because the wrapper peachclient.py will not be used.
The material used in this example is located in the following folder in the Techila SDK:
-
techila\examples\python\Features\precompiled_binary
When executing precompiled binaries during a computational Project, the following peach-function parameter needs to be defined.
executable = TrueIn addition, as precompiled binaries typically do not require Python runtime components on Workers, it is recommended that you also disable Python Runtime Bundles imports with the following parameter:
python_required = FalseIn addition to these two parameters, the names of the executable binaries will need to be defined by using the binaries parameter. The general syntax for defining the parameter is shown below.
binaries = [{'file': '<path_to/binary_name>'}]The <path_to/binary_name> notation should be replaced with path and name of the executable binary you wish to transfer and execute on Workers. For example, the following syntax could be used to transfer file mcpi.exe from the directory C:\temp to Workers.
binaries = [{'file': 'C:\\temp\\mcpi.exe'}]If the executable is operating system specific (e.g. a Windows executable), the osname parameter can be used to define the operating system of Workers that are allowed to execute the binary. For example, the following syntax defines that the executable should only be executed on Workers with a Windows operating system.
binaries = [{'file': 'C:\\temp\\mcpi.exe', 'osname': 'Windows'}]Multiple operating system specific binaries can be executed in the same Project by listing the executables and the applicable operating systems. For example, the following syntax would execute binary mcpi.exe on Workers with a Windows operating system and binary mcpi on Workers with a Linux operating system.
binaries = [{'file': 'mcpi', 'osname': 'Linux'},
{'file': 'mcpi.exe', 'osname': 'Windows'}]Input arguments to the executable binary can be passed by using params parameter. For example the following syntax could be used to define three input arguments for the executable binary.
Example:
binaries = [{'file': 'mcpi.exe', 'osname': 'Windows'}]
params = '1 10000 example.file'With the example shown above, each Job in Project would fundamentally consist of the following command line instruction being executed on the Worker.
mcpi.exe 1 10000 example.fileInput arguments that have a different value for each Job, can be passed by using the %P(jobidx)notation. The value of this notation will be replaced with 1 for Job 1, 2 for Job 2 and so on. These values will be automatically generated on the Techila Server.
Example:
binaries = [{'file': 'mcpi.exe', 'osname': 'Windows'}],
params = '%P(jobidx) 10000 example.file'With the example shown above, the following commands line instructions would be executed Workers.
| Job | Executable | Argument 1 | Argument 2 | Argument 3 |
|---|---|---|---|---|
Job 1 |
mcpi.exe |
1 |
10000 |
example.file |
Job 2 |
mcpi.exe |
2 |
10000 |
example.file |
Job 3 |
mcpi.exe |
3 |
10000 |
example.file |
mcpi.exe executable. The value of argument 1 will be different for each Job.The %P() notation can also be used to refer to values of variables that have been defined in the project_parameters parameter. The general syntax for defining a parameter is shown below.
project_parameters = {'<key>':<value>}The <key> notation should be replaced by the string that you want to use when referencing the value (i.e. %P(<key>). The <value> notation should be replaced by the value that you wish to use as an input argument.
Example:
binaries = [{'file': 'mcpi.exe', 'osname': 'Windows'}],
params = '%P(jobidx) %P(loops) example.file',
project_parameters = {'loops':10000}With the example shown above, the following commands line instructions would be executed Workers.
| Job | Executable | Argument 1 | Argument 2 | Argument 3 |
|---|---|---|---|---|
Job 1 |
mcpi.exe |
1 |
10000 |
example.file |
Job 2 |
mcpi.exe |
2 |
10000 |
example.file |
Job 3 |
mcpi.exe |
3 |
10000 |
example.file |
Output files that should be transferred from the Workers to your computer can be listed with the outputfiles parameter. The general syntax for defining a file that should be returned is shown below
outputfiles=['<resource>;file=<filename>']The <resource> notation should be replaced with a string you wish to use when referencing to the output file (i.e. %O(<resource>)). The <filename> notation should be replaced with the name of the file you wish to transfer from the Workers.
Example:
binaries = [{'file': 'mcpi.exe', 'osname': 'Windows'}],
params = '%P(jobidx) %P(loops) %O(output)',
project_parameters = {'loops':10000},
outputfiles=['output;file=example.file'],With the example shown above, the following commands line instructions would be executed Workers.
| Job | Executable | Argument 1 | Argument 2 | Argument 3 |
|---|---|---|---|---|
Job 1 |
mcpi.exe |
1 |
10000 |
example.file |
Job 2 |
mcpi.exe |
2 |
10000 |
example.file |
Job 3 |
mcpi.exe |
3 |
10000 |
example.file |
outputfiles parameter.If the executable binary executed on Workers generates an output file having a different name for each Job, regexp notations can be used to specify wildcards for the output file name. For example, the following syntax could be used to return all files starting with the string output_file from the Workers.
outputfiles=['output;file=example.file;regex=1']The mechanism for distributing binaries is demonstrated with a precompiled version of the Monte Carlo Pi written in C. The binary is provided for two platforms:
-
64-bit Windows (file
mcpi.exe) -
64-bit Linux (file
mcpi)
The generic syntax for executing the binary is:
mcpi <jobidx> <loops> <outputfile>
The input arguments passed to the executable are explained below:
-
<jobidx>, initializes the random number generator seed
-
<loops>, number of iterations performed
-
<outputfile>, the name of the output file that will be generated
The binaries can be executed locally by following the steps below:
-
Launch a command prompt / terminal
-
Execute the program using command:
mcpi 1 1000000 data
This executes the binary and performs 1,000,000 iterations of the Monte Carlo Pi routine. Executing the program with the syntax shown above will create file called data, which will contain two values. The first value will be the number of points that were located inside the unit circle. The second value will be the total number of iterations performed. Values will be stored as plain text and the file can be viewed with a text editor.
5.11.1. Local Control Code
The Local Control Code used to create the Project is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_features_precompiled_binary
# Copyright Techila Technologies Ltd.
""" This script contains the Local Control Code, which can be used to
create the computational Project.
The mcpi.c file must first be compiled into an executable format for
example by using command:
gcc -o mcpi mcpi.c -lm
To run the example, execute commands:
result = run_binaries()
Input arguments:
jobcount: defines the number of Jobs in the Project
loops: defines the number of iterations performed in each Job
Example:
run_binaries(jobcount = 20, loops = 100000000)
"""
# Load the techila library
import techila
def fh(file):
""" Used to process each output file that will be returned from the Workers;
return a list containing values read from the file. """
# Read values returned from the Worker
f = open(file, 'r')
l = f.readline()
f.close()
values = l.split() # Parse values read from the file
in_points = int(values[0]) # Points inside unitary circle
all_points = int(values[1]) # Iterations performed in the job
# Print information where the temporary output file is located on
# End-Users computer and the content of the file.
print('Path of the output file:\n', file)
print('Values read from the output file:\n', l)
# Return values read from the file.
return (in_points, all_points)
def run_binaries(jobcount = 20, loops = 100000000):
""" Creates computational Project in the Techila environment; return an
integer containg approximated value of Pi."""
results = techila.peach( # Peach function call starts
executable = True, # Define that we're using a precompiled executable
python_required = False, # Python runtime libraries not required on Workers
funcname = 'Precompiled binary', # Name can be chosen freely
binaries = [{'file': 'mcpi', 'osname': 'Linux'}, # Execute 'mcpi' binary on Linux Workers
{'file': 'mcpi.exe', 'osname': 'Windows'}], # Execute 'mcpi.exe' binary on Windows Workers
project_parameters = {'loops':loops}, # Define value for the 'loops' input argument
outputfiles = ['output;file=output.data'],
params = '%P(jobidx) %P(loops) %O(output)', # Input arguments given to the executable binary
jobs = jobcount, # Set the number of jobs based on the value of the input argument
filehandler = fh, # Use funtion 'fh' to process each output file returned from Workers
stream = True, # Enable streaming
)
# Permute results returned by the peach function
(in_points, all_points) = map(lambda *x:x ,*results)
# Sum values received from jobs and calculate an approximated value for Pi
pivalue = 4 * float(sum(in_points)) / float(sum(all_points))
# Print and returnt the value of the approximation
print('Approximated value of Pi ', pivalue)
return(pivalue)The script shown above defines two functions; run_binaries and fh.
The run_binaries function contains the peach-function call, which will be used to create the computational Project. The parameters of the peach-function are explained below:
executable = TrueThe executable parameter has been set to True, indicating that the executable code will be a precompiled binary.
python_required = FalseThe python_required parameter has been set to False, indicating that Python Runtime components will not be required on the Worker.
funcname = 'Precompiled binary'As the executable program will be a precompiled binary, the value of the funcname parameter can be defined quite freely. The value of the funcname parameter will only be used to specify the name of the Project (visible in the Techila Web Interface) and for naming the .state file that will be generated in to the current working directory when creating the Project.
binaries = [{'file': 'mcpi', 'osname': 'Linux'},
{'file': 'mcpi.exe', 'osname': 'Windows'}],The binaries parameter defines that the executable mcpi.exe will be executed on Workers with a Windows operating system and the executable mcpi on Workers with a Linux operating system. These executables will be transferred from the current working directory to the Techila Server when the Project is created.
project_parameters = {'loops':loops}The project_parameters parameter sets a value for the loops key according to the value of the loops variable. This definition will be required in order to refer to the value using the %P(loops) notation when defining the params parameter.
outputfiles=['output;file=output.data']The outputfiles parameter defines that the file called output.data should be returned from the Workers to the End-Users computer. The syntax also defines the resource output, meaning the notation %O(output) can be used to refer to the name of the output file.
params = '%P(jobidx) %P(loops) %O(output)'The params parameter defines three input arguments for the executable binary.
The first input argument (%P(jobidx)) will be replaced by different values for each Job. The value of this notation will be 1 for Job 1, 2 for Job 2 and so on. This value will be used to specify the seed for the random number generator.
The second input argument (%P(loops)) will be replaced by the value defined for the loops parameter in project_parameters. The value of this notation will therefore be 100000000 for all Jobs. This value will be used to specify the number of iterations that will be performed in each Job (will define the length of a computational Job).
The third input argument (%O(output)) will be replaced with the value of the resource output defined in the outputfiles parameter. The value of this notation will therefore be output.data for all Jobs. This value will define the name of the file that will be generated by the executable binary.
The figure below illustrates how the parameters defined in the Local Control Code will be passed to the executable binary as input arguments.
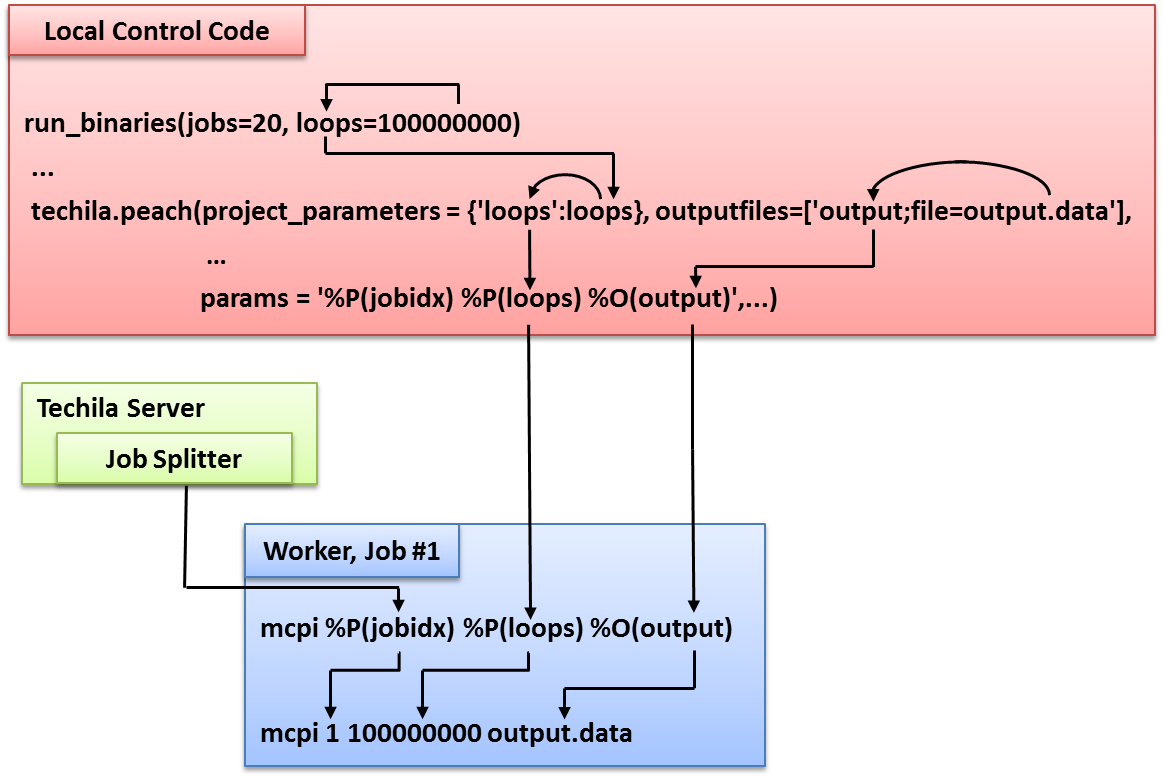
params parameter. Values for the jobidx parameter will be generated on the Techila Server.The fh is the file handler function which will be used to process each of the output files generated during the computational Project. In this example, the function will be used to:
-
Display the location of the temporary output file after it has been transferred to your computer
-
Display the values read from the file
-
Return the values read from the file
The values returned by the fh-function will be stored as list elements in the results list that will be returned from the peach-function. After all output files have been processed, the values will be combined and used to calculate an approximated value for pi.
5.11.2. Worker Code
Each Worker performs the Monte Carlo routine by executing the mcpi.exe or mcpi binary depending on the operating system of the Worker. The binary is executed according to the input arguments that were defined in the peach-function params parameter.
5.11.3. Creating the computational Project
The project can be created with the following commands:
from run_binaries import *
result = run_binaries()This will create a project consisting of 20 Jobs. During each Job, the mcpi binary will be executed and will perform a Monte Carlo routine that consists of 100,000,000 iterations. After the Monte Carlo routine has been completed, the result of the approximation will be stored a file called output.data. This file will be returned from the Workers to the Techila Server.
As the peach-function syntax enabled result streaming, the results will be streamed from the Techila Server to your computer as soon as they are available. Each time a new result has been transferred, the file handler function will be executed and used to process the output file.
5.12. Active Directory Impersonation
The walkthrough in this Chapter is intended to provide an introduction on how to use Active Directory (AD) impersonation. Using AD impersonation will allow you to execute code on the Workers so that the entire code, or parts of code, are executed using your own AD user account.
The material discussed in this example is located in the following folder in the Techila SDK:
-
techila\examples\python\Features\ad_impersonate
Note! Using AD impersonation requires that the Techila Workers are configured to use an AD account and that the AD account has been configured correctly. These configurations can only be done by persons with administrative permissions to the computing environment.
More general information about this feature can be found in Introduction to Techila Distributed Computing Engine.
Please consult your local Techila administrator for information about whether or not AD impersonation can be used in your Techila environment.
AD impersonation is enabled by setting the following Project parameter:
project_parameters = {'techila_ad_impersonate':True}This control parameter will add the techila_ad_impersonate Project parameter to the Project. No other code modifications are needed.
When AD impersonation is enabled, the entire computational process will be executed under the user’s own AD account.
5.12.1. Local Control Code
The Local Control Code used in this example is shown below. The commented version of the code can be found in the following file in the Techila SDK:
-
techila\examples\python\Features\ad_impersonate\run_impersonate.py
# Example documentation: http://www.techilatechnologies.com/help/python_features_ad_impersonate
# Copyright Techila Technologies Ltd.
""" This script contains the Local Control Code, which can be used to
create the computational Project.
To run the example, execute commands:
result = run_impersonate()
Example:
run_impersonate()
"""
# Load the techila library
import techila
import subprocess
def run_impersonate():
""" Creates computational Project in the Techila environment."""
o,e = subprocess.Popen(['whoami'], stdout=subprocess.PIPE).communicate()
local_username = o.rstrip()
worker_username= techila.peach( # Peach function call starts
funcname = 'impersonate_dist', # Name can be chosen freely
files = ['impersonate_dist.py'], # Files that will be evaluated on Workers
project_parameters = {'techila_ad_impersonate':True}, # Enable AD impersonation
jobs = 1 # Set the number of jobs to 1
)
print('Username on local computer: ' + bytes.decode(local_username));
print('Username on Worker computer: ' + bytes.decode(worker_username[0]));
return(worker_username)The Popen method from the subprocess package is used to get the current user name. This Popen method will be executed on the End-User’s computer, meaning the command will return the user name of the End-User. The user name is stored in variable o.
After getting the user name, the string is trimmed and stored in the local_username variable.
The peach-function call creates a Project consisting of one Job. During this Job, the impersonate_dist function will be executed on the Worker. The return value of the peach-function will be stored in variable worker_username, which will contain the user name of the account that was used when the code was executed on the Worker.
AD impersonation is enabled with the Project parameter. This means that the entire computational process (i.e. Job) will be executed using the End-User’s own AD user account.
After the Project has been completed, the user accounts that were used during the example will be printed.
5.12.2. Worker Code
The Worker Code that will be executed in each Job is shown below. The commented version of the code can be found in the following file in the Techila SDK:
-
techila\examples\python\features\ad_impersonate\impersonate_dist.py
# Example documentation: http://www.techilatechnologies.com/help/python_features_ad_impersonate
def impersonate_dist():
import subprocess
o,e = subprocess.Popen(['whoami'], stdout=subprocess.PIPE).communicate()
worker_useraccount = o.rstrip()
return(worker_useraccount)The code starts by importing the subprocess package, which contains methods needed to get the current user name.
After importing the package, the Popen method from the subprocess package is used to get the current user name. This command will be executed on the Worker and will return the user account that is used to run the code. If AD impersonation is enabled and is working correctly, this command will return the End-User’s own AD user account details. If AD is not working correctly, this command will return the Techila Worker’s own user account details.
After retrieving the user account information, the Job will be completed and the information will be returned to the Ende-User’s computer where it will be returned by the peach-function.
5.12.3. Creating the computational Project
To create the computational Project, change your current working directory (in Python) to the directory that contains the example material for this example.
After having navigated to the correct directory, create the computational Project using commands shown below:
from run_impersonate import *
result=run_impersonate()After the Project has been completed, information about the AD user accounts will be displayed. Please note that the output generated by the program will change based your domain and AD account user names.
5.13. Using Semaphores
The walkthrough in this Chapter is intended to provide an introduction on how to create Project-specific semaphores, which can be used to limit the number of simultaneous operations.
The material discussed in this example is located in the following folder in the Techila SDK:
-
techila\examples\python\Features\semaphores
More general information about this feature can be found in Introduction to Techila Distributed Computing Engine.
Semaphores can be used to limit the number of simultaneous operations performed in a Project. There are two different types of semaphores:
-
Project-specific semaphores.
-
Global semaphores
Project-specific semaphores will need to be created in the code that is executed on the End-User’s computer. Respectively, in order to limit the number of simultaneous processes, the semaphore tokens will need to be reserved in the code executed on the Techila Workers. Global semaphores can only be created by Techila administrators
The example figure below illustrates how to use Project-specific semaphores. The code snippet illustrated on the left will create a Project-specific semaphore called examplesema and sets the maximum number of tokens to two.
The code on the right will be executed on the Workers and contains a with statement, which will automatically create a TechilaSemaphore object. This object can only be created when a semaphore token named examplesema is available on the Techila Server. If no semaphore token is available, the process will wait until a token becomes available.
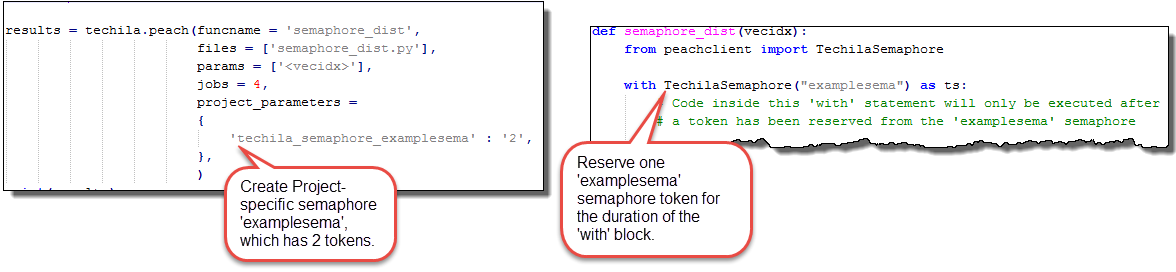
As illustrated in the figure above, Project-specific semaphores are created by adding a Project parameter. The following syntaxes can be used when defining the Project parameter:
'techila_semaphore_<name>' : 'size'
'techila_semaphore_<name>' : 'size, expiration'The 'techila_semaphore_<name>' : 'size' parameter creates a Project-specific semaphore with the defined <name> and sets the maximum number of tokens to match the value defined in size. The semaphore tokens will not have an expiration time, meaning the tokens can be reserved indefinitely.
For example, the following syntax could be used to create a semaphore with the name examplesema, which would have 10 tokens. This means that a maximum of 10 tokens can be reserved at any given time.
project_parameters = {'techila_semaphore_examplesema' : '10'}The 'techila_semaphore_<name>' : 'size, expiration' `parameter defines the `name and size of the semaphore similarly as the earlier syntax shown above. In addition, this syntax can be used to define an expiration time for the token by using the expiration argument. If a Job reserves a semaphore token for a longer time period than the one defined in the expiration argument, the Project-specific semaphore token will be automatically released and made available for other Jobs in the Project. The process that exceeded the expiration time will be allowed to continue normally.
For example, the following syntax could be used to define a 15 minute (900 second) expiration time for each reserved token.
project_parameters = {'techila_semaphore_examplesema' : '10,900'}As illustrated earlier in Figure 34, semaphores are reserved by creating a new instance of the TechilaSemaphore class. The TechilaSemaphore class is defined in the peachclient.py file, which can be imported with the following command on the Worker:
from peachclient import TechilaSemaphoreAfter importing the TechilaSemaphore, the following syntax can be used to create a new TechilaSemaphore object:
TechilaSemaphore(name, isglobal = False, timeout = -1, ignoreerror = False);The only mandatory argument is the name argument, which is used to define which semaphore should be used. The remaining arguments isglobal, timeout and ignoreerror are optional and can be used to modify the behaviour of the semaphore reserve process. The usage of these arguments is illustrated with example syntaxes below.
TechilaSemaphore(name) will reserve one token from the semaphore, which has the same name as defined with the name input argument. This syntax can only be used to reserve tokens from Project-specific semaphores.
For example, the following syntax could be used to reserve one token from a semaphore named examplesema for the duration of the with-block.
from peachclient import TechilaSemaphore
with TechilaSemaphore("examplesema") as ts:
# Code inside this 'with' statement will only be executed after
# a token has been reserved from the 'examplesema' semaphoreTechilaSemaphore(name, isglobal=True) can be used to reserve one token from a global semaphore with a matching name as the one defined with the name argument. When isglobal is set to True, it defines that the semaphore is global. Respectively, when the value is set to False, it defines that the semaphore is Project-specific.
For example, the following syntax could be used to reserve one token from a global semaphore called globalsema.
from peachclient import TechilaSemaphore
with TechilaSemaphore("globalsema", isglobal = True) as ts:
# Code inside this 'with' statement will only be executed after
# a token has been reserved from the global 'globalsema' semaphoreTechilaSemaphore(name, timeout=10) can be used to reserve a token from a Project-specific semaphore, which has the same name as defined with the name input argument. In addition, this syntax defines a value for the timeout argument, which is used to define a timeout period (in seconds) for the reservation process. When a timeout period is defined, a timer is started when the constructor requests a semaphore token. If no semaphore token can be reserved within the specified time window, the Job will be terminated and the Job will generate an error. If needed, setting the value of the timeout parameter to -1 can be used to disable the effect of the timeout argument.
For example, the following syntax could be used to reserve one token from Project-specific semaphore called projectsema. The syntax also defines a 10 second timeout value for token. This means that the command will wait for a maximum of 10 seconds for a semaphore token to become available. If no token is available after 10 seconds, the code will generate an error, which will cause the Job to be terminated.
from peachclient import TechilaSemaphore
with TechilaSemaphore("examplesemasema", timeout = 10) as ts:
# Code that should be executed only when a Project-specific semaphore
# token named 'projectsema' is available and can be reserved by this Job.
# If no token has been reserved after 10 s, the Job will be terminated.TechilaSemaphore(name, isglobal = True, timeout = 10, ignoreerror = True) can be used to define the name, isglobal and timeout arguments in a similar manner as explained earlier. In addition, the ignoreerror argument is used to define that problems during the semaphore token reservation process should be ignored.
When the ignoreerror argument is set to True, the code is allowed to continue even if a semaphore token could not be reserved in the time window specified in timeout. The code is also allowed to continue even if there is no matching semaphore on the Techila Server. If needed, setting ignoreError to False can be used to disable this parameter.
The example code snippet below illustrates how to reserve a global semaphore token called globalsema. If the semaphore is reserved successfully, the operations inside the if (ts == True) statement are processed. If no semaphore token could be reserved, code inside the else statement will be processed.
with TechilaSemaphore("globalsema", isglobal=True, ignoreerror = True) as ts:
if (ts == True):
# This code block will be executed only if a token was reserved ok.
else:
# This code block will be executed if no token could be reserved5.13.1. Local Control Code
The Local Control Code used in this example is shown below. The commented version of the code can be found in the following file in the Techila SDK:
-
techila\examples\python\features\semaphore\run_semaphore.py
# Example documentation: http://www.techilatechnologies.com/help/python_features_semaphore
def run_semaphore():
import techila
jobs = 4
results = techila.peach(funcname = 'semaphore_dist',
files = ['semaphore_dist.py'],
jobs = jobs,
project_parameters =
{
'techila_semaphore_examplesema' : '2',
}
)
for jobresult in results:
for message in jobresult:
print(message)
return resultsThe Project parameter definition is used to create the Project-specific semaphore. The semaphore will be named examplesema and will contain two semaphore tokens. This means that a maximum of two tokens can be reserved at any given time. No other modification are required in the code that is used to create the Project.
Project results will be displayed by using for-loops to iterate over the elements in the results list.
5.13.2. Worker Code
The Worker Code that will be executed in each Job is shown below. The commented version of the code can be found in the following file in the Techila SDK:
-
techila\examples\python\features\semamphore\semaphore_dist.py
# Example documentation: http://www.techilatechnologies.com/help/python_features_semaphore
import time
def semaphore_dist():
from peachclient import TechilaSemaphore
import os
result=['Results from Job #' + os.getenv('TECHILA_JOBID_IN_PROJECT')]
jobStart = time.time()
with TechilaSemaphore("examplesema") as ts:
start = time.time()
genLoad(30);
twindowstart = start - jobStart
twindowend = time.time() - jobStart
result.append('Project-specific semaphore reserved for the following time window: ' + str(round(twindowstart)) + '-' + str(round(twindowend)))
with TechilaSemaphore("globalsema", isglobal = True, ignoreerror = True) as ts:
if (ts == True):
# This code block will be executed only if a token was successfully reserved.
start2 = time.time()
genLoad(5)
twindowstart = start2 - jobStart
twindowend = time.time() - jobStart
result.append('Global semaphore reserved for the following time window: ' + str(round(twindowstart)) + '-' + str(round(twindowend)))
if (ts == False):
# This code block will be executed if no token could be reserved
result.append('Error when using global semaphore')
return(result)
def genLoad(duration):
import random
a = time.time()
while ((time.time() - a) < duration):
random.random()
return(0)The code starts by importing the TechilaSemaphore from the peachlient.py file. The peachlient.py file is automatically copied to the same temporary working directory on the Worker. This temporary working directory will also contain the semaphore_dist.py file.
The current timestamp is then retrieved, which will be used to mark the start time of the Job.
The Job’s index number is retrieved from an environment variable and stored as the first element in the result list.
The with-statement will create a TechilaSemaphore object. This object contains enter and exit methods, which will be automatically called when the with-block is entered and exited. The execution of this code block will start when the Job has reserved a semaphore token from the semaphore called examplesema. Because the Project contains four Jobs and there are two tokens, only two Jobs will start processing the code right away. The remaining two Jobs will wait until the earlier Jobs exited the with-block and released the tokens.
After getting the token, the current timestamp is retrieved. This will be used to mark the start time of the with block.
The genLoad function is then executed, which will generate CPU load by generating random numbers for 30 seconds.
The elapsed time between the start of the Job (jobStart variable) and the genLoad method call (start variable) is calculated. If a Job was able to reserve a token right away, this value should be 0. If the Job had to wait for a semaphore token to become available, this value will be roughly 30. Please note that if all Jobs were not started at the same time, you will get different values.
After this, the code calculates how many seconds the Project-specific semaphore token was reserved.
The result string is then built and the string is addedto the result list, which will be returned from the Job. The string will contain information about the time window when the Project-specific semaphore token was reserved relative to the start of the Job.
After processing the Project-specific semaphore, the second with-block is executed, which will attempt to reserve one token from the global semaphore globalsema. The syntax used sets the value of the ignoreerror argument to True, meaning code inside the with-block will be executed regardless of the status of the semaphore reservation process. If the semaphore token was reserved successfully, the value True will be stored in ts. If the semaphore could not be reserved, the value False will be stored in ts.
If the global semaphore token was reserved successfully, code inside the if-clause will be executed. In this case, the genLoad function will be used to generate 5 seconds of CPU load. After the generating the CPU load, information about when the global semaphore token was reserved will be stored in the result list.
If the global semaphore token was not reserved successfully, the code inside the second if-clause will be executed. In this case, a simple status message will be stored in the result list.
Please note that global semaphores will need to be created by your local Techila administrator. This means that unless your local Techila administrator has created a semaphore named globalsema, the second if-statement (ts == False) will be executed in the Job.
The example figure below illustrates how Jobs in this example are processes in an environment where all Jobs can be started at the same time. In this example figure, the global semaphore globalsema is assumed to exist and that it only contains one token.
The activities taking place during the example Project are explained below.
After the Jobs have been assigned to Workers, two of the Jobs start processing the first with-statement. This processing is illustrated by the Computing, Project-specific semaphore reserved bars. During this time, the remaining two Jobs will wait until semaphore tokens become available. After the first Jobs have released the Project-specific semaphores, Jobs 3 and 4 can reserve semaphore tokens and start processing the first with-block.
The global semaphore only contains one token, meaning only one Job can process the second with-block at any given time. In the example figure below, Job 1 reserves the token and starts processing the second with-statement first. This processing is represented by the Computing, global semaphore reserved bars. After Job 1 has completed processing the second with-block, the global semaphore is released and Job 2 can start processing.
After Jobs 3 and 4 complete processing the first with-statement, the Jobs will start reserving tokens from the global semaphore.
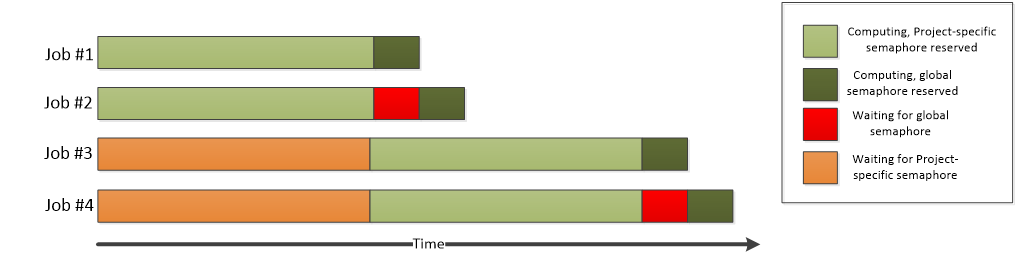
with-block at the same time. The number of Jobs able to simultaneously process the second with-statement depends on the number of tokens in the global semaphore. This example assumes that there is only one token in the global semaphore.5.13.3. Creating the computational Project
To create the computational Project, change your current working directory (in Python) to the directory that contains the example material for this example.
After having navigated to the correct directory, create the computational Project using commands shown below:
from run_semaphore import *
result=run_semaphore()Please note that the output generated by the program will change based on whether or not the global semaphore named globalsema is available. The two example screenshots below illustrate the output in both scenarios.
The example screenshot below illustrates the generated output when the global semaphore exists.
Please note that there might be overlap in the reported time windows. This is because the time windows are measured from the timestamp generated at the start of the 'Execute' method, which means that e.g. initialization delays can cause the reported times to overlap.
5.14. Intermediate Data
The walkthrough in this Chapter is intended to provide an introduction on how to transfer intermediate data to and from Jobs.
The material discussed in this example is located in the following folder in the Techila SDK:
techila\examples\Python\Features\intermediate_data
More general information about this feature can be found in Introduction to Techila Distributed Computing Engine.
In the computational Job, intermediate data is managed by using the following Python functions.
-
save_im_data- Executed in the Job. Sends data to End-User. -
load_im_data- Executed in the Job. Loads data received from End-User.
On the End-User’s computer, intermediate data can be transferred to the Job by using the following function.
-
send_im_data- Executed on the End-User’s computer. Sends data to Job.
This send_im_data function will need to be executed in an intermediate callback function, which is automatically executed each time intermediate data is received from a Job. Intermediate callback functions can be enabled with a cloudfor control parameter.
These functions and the concept of an intermediate callback function are explained in more detail below.
In order to use the save_im_data and load_im_data functions during the Job, they will need to be imported by executing the following import statement at the start of the Job.
from peachclient import save_im_data, load_im_datasave_im_data is used to send workspace variables from a Job to the End-User. When this function is executed in a Job, the specified variables will be saved to a data file, which will be automatically transferred to the End-User via the Techila Server. For example, the following syntax could be used to send a tuple containing variables var1 and var2 from a Job to the End-User.
save_im_data((var1, var2))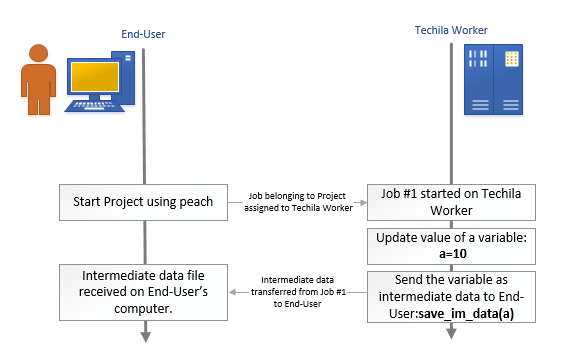
save_im_data function will need to be executed on the Techila Worker, during the computational Job. This function is used to send intermediate result data from the Job to the End-User. In this figure, the value of variable a is transferred.After an intermediate data file has been transferred to the End-User’s computer, the most convenient way to process the contents of the file is use an intermediate callback function. Intermediate callback functions can be enabled by using the intermediate_callback, control parameter for peach to define which function will be executed when new interemediate data is received. For example, the following parameter could be used to define that a function named imcbfun will be used to process each intermediate data file.
techila.peach(...
intermediate_callback = imcbfun
)The intermediate callback function expects atleast one input argument. The value of this input argument will automatically be replaced with the intermediate data that was sent from the Job when the save_im_data function was executed. The code snippet shown below shows an intermediate callback function that prints the data received from the Job.
def imcbfun(data):
print(data) # This would print the data that was received from the JobIn addition to the mandatory input argument mentioned above, the intermediate callback function can also be given three optional parameters. These optional parameters have the following names.
-
jobid -
pid -
jobidx
jobid can be used to get the Job’s Id number. This is a unique value in a Techila Distributed Computing Engine environment and will be needed when sending data back to the Job.
pid is the Project ID number.
jobidx is the Job’s index number in the Project. If the Project contains 10 jobs, the values of this variable will range from 1 to 10.
The code snippet shown below shows an intermediate callback function that prints the data received from the Job and sends variable a back to the same Job.
def imcbfun(data, jobid):
print(data) # Print the data that was received from the Job
a = 2
send_im_data(jobid, a) # Send variable 'a' back to the Job.As can be seen from the code snippet above, you will need to define a target jobid, followed by a comma separated list of variable names you want to transfer when using send_im_data to transfer data to a Job. Multiple variables can be transferred by wrapping them in a data structure, such as a list or a tuple. For example, the following syntax could be used to send a tuple containing variables b and c back to the same Job that returned the intermediate data.
def imcbfun(data, jobid):
print(data) # Print the data that was received from the Job
b = 4
c = 8
send_im_data(jobid,(b,c)) # Send a tuple containing the variables back to the JobAfter intermediate data has been sent to a Job (by using the send_im_data), the load_im_data can be executed on the Techila Worker, during the computational Job. This function will wait for intermediate data and load the intermediate data after it has been received from the End-User. This function can be executed without any input arguments, in which case the function will wait indefinitely for intermediate data. Code execution will continue immediately after data has been received and loaded.
# Executed on Techila Worker, will wait indefinitely until intermediate data has been received.
# Stores the received intermediate data to variable 'rdata'
rdata = load_im_data()If you do not want the function to wait indefinitely, you can define a timeout (in seconds) by using an input argument. For example, the following syntax could be used to wait for intermediate data for a maximum of 60 seconds before allowing code execution to continue. Code execution will be allowed to continue after 60 seconds, even if no intermediate data has been received. Code execution will also continue immediately after data has been received and loaded.
# Executed on Techila Worker, will wait a maximum of 60 seconds for intermediate data before continuing.
# Stores the received intermediate data to variable 'rdata'
rdata = load_im_data(60)The image below illustrates how functions save_im_data, send_im_data and load_im_data can be used in conjunction to update variable values in a computational Job.
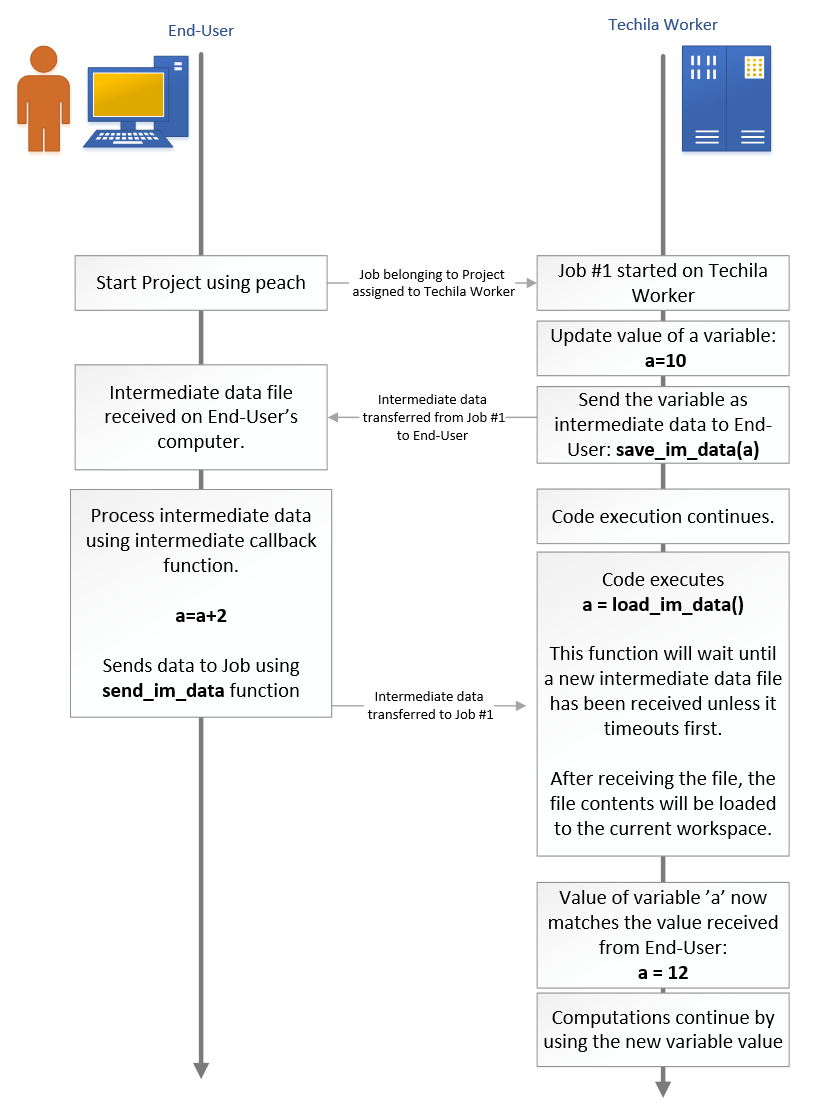
save_im_data is used to save the value of variable a, which will be transferred back to the End-User’s computer. This intermediate data file will then be processed in an intermediate callback function. This intermediate callback function will update the value of variable a and transfer the updated variable to the Job using function send_im_data. Intermediate data received from the End-User’s computer can be read on the Techila Worker by executing the load_im_data function during the Job. After executing function, updated variable values will be available in the Job’s workspace.5.14.1. Example material walkthrough
The source code of the example discussed here can be found in the following file in the Techila SDK:
techila\examples\python\Features\run_intermediate.py
The code used in this example is also illustrated below for convenience.
# Example documentation: http://www.techilatechnologies.com/help/python_features_intermediate_data
# Copyright Techila Technologies Ltd.
# This function contains the Local Control Code, which will be used to
# distribute computations to the Techila environment.
#
# Usage:
# result = run_intermediate()
#
# Note: The number of Jobs in the Project will be automatically set to 2
def myfunction(a, jobid, jobidx):
# Intermediate callback function. Called each time new intermediate data
# has been received.
from techila import send_im_data
print('Received intermediate data from Job #' + str(jobidx))
print('Value of received variable is: ' + str(a))
a = a + 2 # Increase value of variable so we know it was processed here
print('Increased value of variable to: ' + str(a))
print('Sending updated value of variable as intermediate data to Job #' + str(jobidx))
send_im_data(jobid, a); # Send the updated value of 'a' back to the same Job
print('Finished sending intermediate data to Job #' + str(jobidx))
# Load the techila library
import techila
def run_intermediate():
# Will be used to set the number of jobs to 2
jobs = 2
result = techila.peach(funcname = "intermediate_dist", # Name of the executable function
files = ['intermediate_dist.py'], # File with function definitions
params = '<param>', # Input argument for executable function
peachvector = range(1,jobs+1), # Number of Jobs and input args
stream = True, # Enable streaming
intermediate_callback = myfunction, # Intermediate callback function
)
# Print and return results
print(result)
return result In this example, the peach function call will create a Project consisting of two Jobs. Each Job will generate a variable a and transfer the value of variable a as intermediate data back to the End-User’s computer. After the intermediate data has been received on the End-User’s computer, the data will be processed using an intermediate callback function named myfunction.
Function myfunction will display information about the data that was received from a Job, increase the value of variable a by 2 and send the updated value back to the same Job that sent the data by using function send_im_data. This updated value will be loaded by the load_im_data function call.
Each Job will return the updated value of the variable as the result. These results will be printed after the Project has been completed.
5.14.2. Running the example
To create the computational Project, change your current working directory (in Python) to the directory that contains the example material for this example.
After having navigated to the correct directory, create the computational Project using commands shown below:
from run_intermediate import *
result=run_intermediate()6. Interconnect
The Techila interconnect feature allows solving parallel workloads in a Techila environment. This means that using the Techila interconnect feature will allow you to solve computational Projects, where Jobs need to communicate with other Jobs in the Project.
This Chapter contains walkthroughs of simple examples, which illustrate how to use the Techila interconnect functions to transfer interconnect data in different scenarios.
The example material discussed in this Chapter, including python source code files can be found under the following folder in the Techila SDK:
-
techila\examples\python\Interconnect
More general information about this feature can be found in Introduction to Techila Distributed Computing Engine.
Below are some notes about additional requirements that need to be met when using the Techila interconnect feature with Python.
General Note: All Jobs of an interconnect Project must be running at the same time
When using Techila interconnect methods in your code, all Jobs that execute these methods must be running at the same time. Additionally, all Workers that are assigned Jobs from your Project must be able to transfer Techila interconnect data. This is means that you must limit the number of Jobs in your Project so that all Jobs can be executed simultaneously on Workers that can transfer interconnect data.
If all Workers in your Techila environment are not able to transfer interconnect data, it is recommended that you assign your Projects to run on Worker Groups that support interconnect data transfers. If Jobs are assigned to Workers that are unable to transfer interconnect data, your Project may fail due to network connection problems. Please note that before the interconnect Worker Groups can be used, they will need to be configured by your local Techila Administrator.
You can specify that only Workers belonging to specific Worker Groups should be allowed to participate in the Project with the 'techila_worker_group' Project parameter.
The example code line below illustrates how the Project could be limited to only allow Workers belonging to Worker Group called 'IC Group 1' to participate. This example assumes that administrator has configured a Worker Group called 'IC Group 1' so it consists only of Workers that are able to transfer interconnect data with other Workers in the Worker Group.
project_parameters = {'techila_worker_group' : 'IC Group 1'}Please ask your local Techila Administrator for more detailed information about how to use the Techila interconnect feature in your Techila environment.
6.1. Transferring Data between Specific Jobs
This example is intended to illustrate how to transfer data between specific Jobs in the Project.
There are no locally executable versions of the code snippets. This is because the distributed versions are essentially applications, where each iteration must be executed at the same time.
The material used in this example is located in the following folder in the Techila SDK:
-
techila\examples\python\Interconnect\1_jobtojob
Please note that before you can successfully run this example, your Techila environment needs to be configured to support Techila interconnect Projects. Please ask your local Techila Administrator for more information.
Methods for transferring the interconnect data are included in the TechilaInterconnect class, which is defined in the peachclient.py file. This class can be imported during a computational Job with the following syntax:
from peachclient import TechilaInterconnectAfter importing the class, a new TechilaInterconnect object can be created with the following syntax:
ti = TechilaInterconnect()When the object is created, the Worker automatically joins the interconnect network, which is used to connect each Job in the Project. If your Techila environment does not support the Techila interconnect feature, attempting to create a TechilaInterconnect object will generate an error, which will cause your Project to fail.
After creating the object, the following methods can be used to send and receive interconnect data transferred between two specific Jobs
-
ti.send_data_to_job(targetjob,data) -
ti.recv_data_from_job(sourcejob)
The send_data_to_job(targetjob,data) method sends the data defined in argument data to the Job with an index number defined in argument targetjob.
The recv_data_from_job(sourcejob) method receives data from the Job that is specified in the sourcejob argument. This method returns the data that was received from the sourcejob.
Any data that is sent with the send_data_to_job method, must be received with a matching recv_data_from_job method call.
Example: The following syntax could be used to send a string 'Hello' to Job 2.
ti.send_data_to_job(2,'Hello')If we assume that the above code is executed in Job 1, the data could be received by executing the following command in Job 2.
data = ti.recv_data_from_job(1)The output variable data will contain the data that was received. In this example, data would contain the string 'Hello'.
Note! After interconnect data has been transferred between Jobs, the ti.wait_for_others() command can be used to enforce a synchronization point. When this command is executed in Jobs, each Job in the Project will wait until all other Jobs in the Project have also executed the command before continuing.
6.1.1. Example Code Walkthrough
The source code of the example discussed in this Chapter is shown below.
-
techila\examples\python\Interconnect\1_jobtojob\jobtojob.py
# Example documentation: http://www.techilatechnologies.com/help/python_interconnect_1_jobtojob
# This Python script contains the Local Control Code and Worker Code, which will be
# used to perform the computations in the Techila environment.
#
# Usage:
# result = run_jobtojob()
# Copyright Techila Technologies Ltd.
def jobtojob_dist():
"""
This function contains the Worker Code and will be executed on Techila Workers.
The code will transfer simple strings between Job #1 and Job #2 using the Techila
interconnect functions.
"""
# Import the Techila interconnect functions from the peachclient.py file
from peachclient import TechilaInterconnect
# Create a TechilaInterconnect object, which contains the interconnect methods.
ti = TechilaInterconnect()
rcvd = None
if ti.myjobid == 1: # Job #1 will execute this code block
ti.send_data_to_job(2, 'Hi from Job #1') # Send message to Job #2
rcvd = ti.recv_data_from_job(2) # Receive message from Job #2
elif ti.myjobid == 2: # Job #2 will execute this code block
rcvd = ti.recv_data_from_job(1) # Receive message from Job #1
ti.send_data_to_job(1, 'Hi from Job #2') # Send message to Job #1
# Wait until all Jobs have reached this point before continuing
ti.wait_for_others()
return (ti.myjobid, rcvd)
def run_jobtojob():
"""
This function will be executed on the End-User's computer
functions and will be used to create the Project.
"""
# Load the techila package
import techila
# Set the number of Jobs to 2
jobs = 2
results = techila.peach(funcname = 'jobtojob_dist', # Call this function on Workers
files = 'jobtojob.py', # Source this file on Workers
jobs = jobs, # Specify Job count (2 in this example)
#project_parameters = {'techila_worker_group' : 'IC Group 1'} # Uncomment to enable. Limit Project to Worker Group 'IC Group 1'.
)
# Print the results
for res in results:
jobid = str(res[0])
jobresult = res[1]
print('Result from Job #' + jobid + ': ' + jobresult)
return(results)The run_jobtojob function is used to create the Project and display the results. The peach-syntax on will create a Project with two Jobs. During each Job, the function jobtojob_dist will be executed. After the Project has been completed, the results will be displayed with the for-loop.
The jobtojob_dist function will be executed in each Job. This function will be used to transfer simple message strings between the two Jobs in the Project.
Below is an illustration of the interconnect data transfer operations that will be performed in this Project when the Jobs are assigned to Workers.
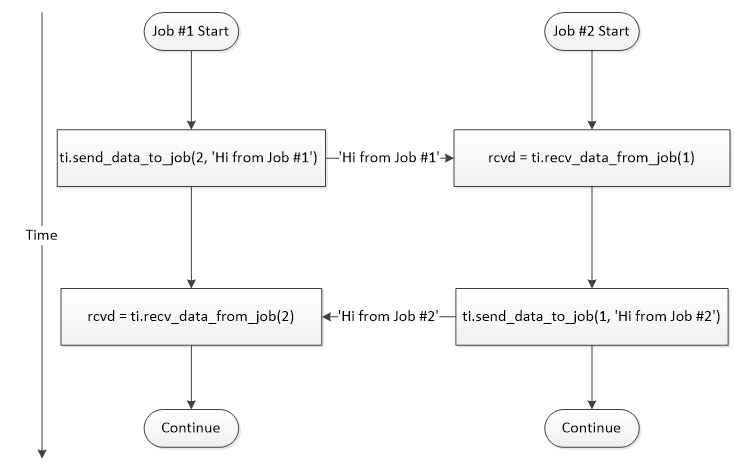
Below is a more detailed explanation on the effect of each line in the code sample.
The TechilaInterconnect class is imported from the peachclient.py file. After this, a new TechilaInterconnect object, which will provide the necessary methods needed to transfer interconnect data.
The remaining code contains two if-statements. These determine the operations that will be executed in each Job. Job 1 will execute the code inside the first if-statement (ti.jobid==1) and Job 2 will execute the code inside the other code branch (ti.jobid==2).
Job 1 will start by executing the send_data_to_job command, which is used to transfer data to Job 2. Job 2 respectively starts by executing the recv_data_from_job command, which is used to receive the data, which is being transferred by Job 1.
After Job 2 has received the data, the roles are reversed, meaning Job 2 will transfer data to Job 1.
After data has been transferred between Jobs, each Job will execute the ti.wait_for_others() command. This line will act as a synchronization point, meaning Jobs will continue execution only after all Jobs have reached this line.
6.1.2. Running the Example
To create the computational Project, change your current working directory (in Python) to the directory that contains the example material for this example.
After having navigated to the correct directory, create the computational Project using commands shown below:
from jobtojob import *
result = run_jobtojob()6.2. Broadcasting Data from one Job to all other Jobs
This example is intended to illustrate how to broadcast data from one Job to all other Jobs in the Project.
The material used in this example is located in the following folder in the Techila SDK:
-
techila\examples\python\Interconnect\2_broadcast
Please note that before you can successfully run this example, your Techila environment needs to be configured to support Techila interconnect Projects. Please ask your local Techila Administrator for more information.
Data can be broadcasted from one Job to all other Jobs with the cloudbc method:
ti = TechilaInterconnect()
bcval = ti.cloudbc(<datatobetransferred>, <sourcejobidx>);The notation <datatobetransferred> should be replaced with the data you wish to broadcast to other Jobs in the Project. The notation <sourcejobidx> should be replaced with the index of the Job you wish to use for broadcasting the data. The function will return the broadcasted data and it can be stored in a workspace variable; in example syntax shown above it will be stored in the bcval variable.
The figure below illustrates how the cloudbc command could be used to broadcast the value of a local variable x from Job 2 to other Jobs in the Project.
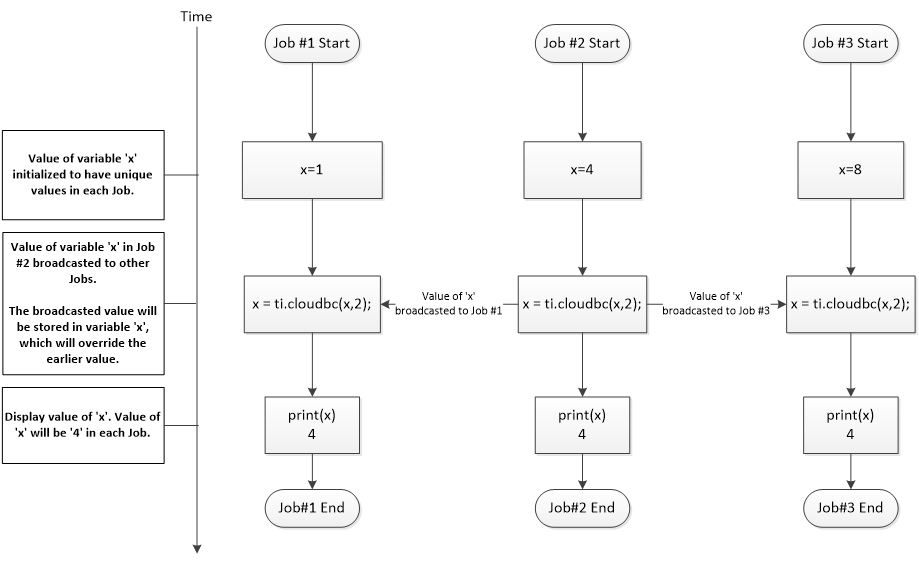
6.2.1. Example Code Walkthrough
The commented version of the code can be found in the following file in the Techila SDK:
-
techila\examples\python\Interconnect\2_broadcast\broadcast.py
The source code of the example is shown below.
# Example documentation: http://www.techilatechnologies.com/help/python_interconnect_2_broadcast
# This Python script contains the Local Control Code and Worker Code, which will be
# used to perform the computations in the Techila environment.
#
# Usage:
# result = run_cloudbc()
# Copyright Techila Technologies Ltd.
def cloudbc_dist(sourcejob):
"""
This function contains the Worker Code and will be executed on Techila Workers.
The code will broadcast a simple string from 'sourcejob' to all Jobs in the
Project using the Techila interconnect functions.
"""
# Import the Techila interconnect functions from the peachclient.py file
from peachclient import TechilaInterconnect
# Create a TechilaInterconnect object, which contains the interconnect methods.
ti = TechilaInterconnect()
# Build a simple message string that will be broadcasted from one Job to
# all other Jobs in the Project.
datatotransfer = 'Hi from Job ' + str(ti.myjobid)
# Broadcast the message str
result = ti.cloudbc(datatotransfer, sourcejob)
# Wait until all Jobs have reached this point before continuing
ti.wait_for_others()
return (ti.myjobid, result)
def run_cloudbc():
"""
This function contains the Local Control Code, which will be executed on the
End-User's computer. This function will create a computational Project, where
one Job will broadcast to all other Jobs in the Project.
"""
import techila
# Define number of Jobs in the Project.
jobs = 3
# Define which Job will broadcast data.
sourcejob = 2
results = techila.peach(funcname = 'cloudbc_dist', # Execute this function on Workers
files = ['broadcast.py'], # Source this file on Workers.
params = [sourcejob], # Pass 'sourcejob' as an input argument
jobs = jobs, # Set the Job count
#project_parameters = {'techila_worker_group' : 'IC Group 1'} # Uncomment to enable. Limit Project to Worker Group 'IC Group 1'.
)
# Print the results.
for res in results:
jobid = str(res[0])
result = res[1]
print('Result from Job #' + jobid + ': ' + result)
return(results)The peach-function used in this example will create a Project with three Jobs. Each Job will execute the cloudbc_dist function with one input argument sourcejob. The sourcejob argument will be used to define which Job will broadcast the interconnect data. In this example, the value of the sourcejob parameter has been set to 2, meaning Job 2 will broadcast interconnect data.
Each Job will execute the cloudbc_dist function, which will be used to broadcast the data.
At the start of each Job, a message string will be built and stored in variable datatotransfer. This message string will include the value of ti.myjobid, which contains the Job’s index number. This information will be used to distinguish which Job broadcasted the string. The example table below illustrates values of the datatotransfer variable in each Job, in a Project consisting of 3 Jobs.
| Job # | Value of 'datatotransfer' |
|---|---|
1 |
Hi from Job 1 |
2 |
Hi from Job 2 |
3 |
Hi from Job 3 |
The datatotransfer variable will be broadcasted from the sourcejob to all other Jobs in the Project using ti.cloudbc. In this example, the value of the sourcejob argument has been set to 2, meaning Job 2 will broadcast data to all other Jobs in the Project. The broadcasted data will be returned from the ti.cloudbc method and stored in the result variable.
After the data has been broadcasted (and received), each Job in the Project will wait until all other Jobs in the Project have reached and executed the ti.wait_for_others() command.
6.2.2. Running the Example
To create the computational Project, change your current working directory (in Python) to the directory that contains the example material for this example.
After having navigated to the correct directory, create the computational Project using commands shown below:
from broadcast import *
result = run_cloudbc()When executed, the code will create a Project consisting of three (3) Jobs. Job 2 will broadcast data to other Jobs in the Project. Below figure illustrates the operations that take place when the code is executed with the syntax shown above.
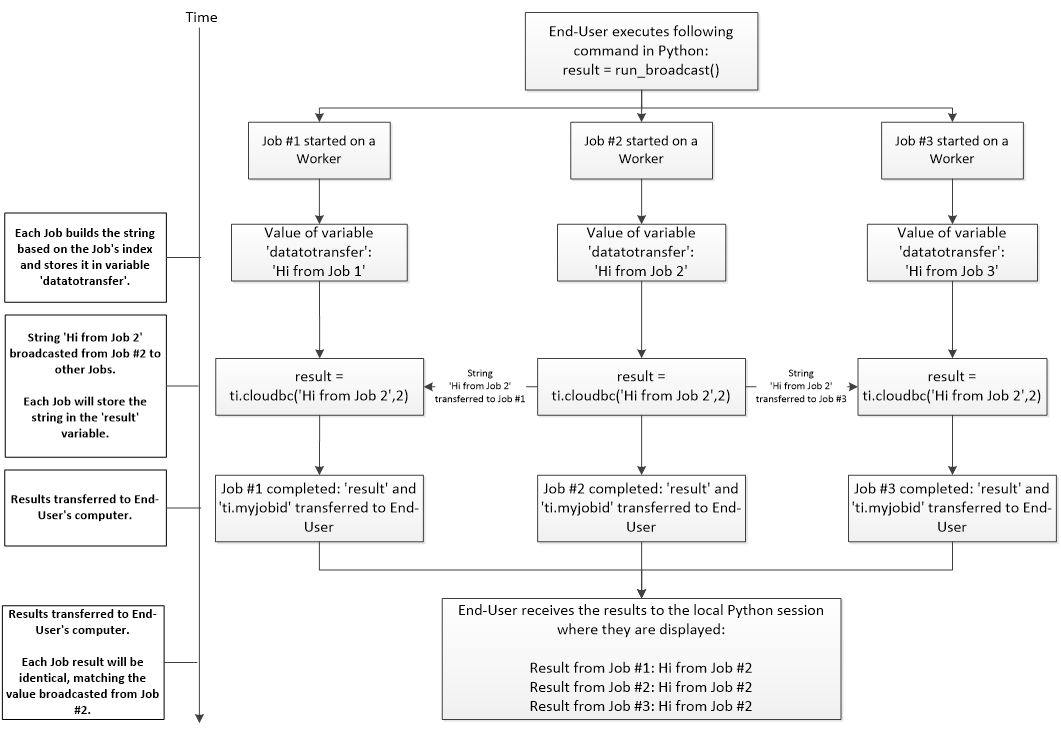
6.3. Transferring Data from all Jobs to all other Jobs
This example is intended to illustrate how to broadcast data from all Jobs to all other Jobs in the Project.
The material used in this example is located in the following folder in the Techila SDK:
-
techila\examples\python\Interconnect\3_alltoall
Please note that before you can successfully run this example, your Techila environment needs to be configured to support Techila interconnect Projects. Please ask your local Techila Administrator for more information.
Data can be transferred to all Jobs from all other Jobs by using the send_data_to_job and recv_data_from_job methods combined with regular for-loops and if-statements. These for-loops and if-statements will need to be implemented so that each Job that is sending data has a matching Job that is receiving data.
6.3.1. Example Code Walkthrough
The source code of the example discussed in this Chapter is shown below.
-
techila\examples\python\Interconnect\3_alltoall\alltoall.py
# Example documentation: http://www.techilatechnologies.com/help/python_interconnect_3_alltoall
# This Python script contains the Local Control Code and Worker Code, which will be
# used to perform the computations in the Techila environment.
#
# Usage:
# result = run_alltoall()
# Copyright Techila Technologies Ltd.
def alltoall_dist():
"""
This function contains the Worker Code and will be executed on Techila Workers.
Each Job will transfer a simple string to all other Jobs in the Project using
the Techila interconnect functions.
"""
# Import the Techila interconnect functions from the peachclient.py file
from peachclient import TechilaInterconnect
# Create a TechilaInterconnect object, which contains the interconnect methods.
ti = TechilaInterconnect()
# Get the Job's index number
jobidx = ti.myjobid
# Get the number of Jobs in the Project
jobcount = ti.jobcount
dataall=[]
# Create message string
data = 'Hi from Job ' + str(ti.myjobid)
# Send the message string to all other Jobs in the Project
for src in range(1,jobcount+1):
for dst in range(1,jobcount+1):
if src == jobidx and dst != jobidx:
ti.send_data_to_job(dst,data)
elif src != jobidx and dst == jobidx:
recvdata = ti.recv_data_from_job(src)
dataall.append(recvdata)
else:
print('Do nothing')
# Wait until all Jobs have reached this point before continuing
ti.wait_for_others()
return (jobidx, dataall)
def run_alltoall():
"""
This function contains the Local Control Code, which will be executed on the
End-User's computer. This function will create a computational Project, where
simple message strings will be transferred between all Jobs in the Project.
"""
import techila
# Set the number of Jobs to four.
jobs = 4
results = techila.peach(funcname = 'alltoall_dist', # Execute this function on Workers
files = ['alltoall.py'], # Source this file on Workers
jobs = jobs, # Define the number of Jobs
#project_parameters = {'techila_worker_group' : 'IC Group 1'} # Uncomment to enable. Limit Project to Worker Group 'IC Group 1'.
)
# Print the results
for res in results:
jobid = str(res[0])
result = str(res[1])
print('Result from Job #' + jobid + ': ' + result)
return(results)The peach-function used in this example defines that the Project will contain four Jobs and that during each Job, the alltoall_dist function should be executed.
The alltoall_dist function is executed on the Worker and starts by getting the Job’s index number and stores it in variable jobidx.
The number of Jobs in the Project is retrieved with ti.jobcount and stored in variable jobcount. With the values used in the example, this value will be four (4).
Each Job will then build a simple, unique message string, which will be transferred from the Job. The table below shows the messages transferred from each Job.
Job # |
Message Transferred |
1 |
Hi from Job 1 |
2 |
Hi from Job 2 |
3 |
Hi from Job 3 |
4 |
Hi from Job 4 |
The two nested for-loops contain the code that will decide the order in which Jobs will transfer messages to other Jobs. The transferred messages will be stored to the dataall list, which will be returned to the End-User’s computer.
The interconnect data transfers that take place during the Project are illustrated in the figure below. The arrows indicate that interconnect data is being transferred. The values in parentheses correspond to the values of the src and dst loop counters. For example, arrow with value (1,3) means that Job 1 is sending the msg string to Job 3. If src is equal to dst (e.g. (2,2)), no data is transferred because the source and target are the same.
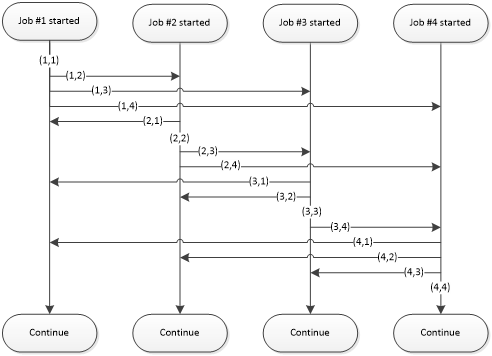
6.3.2. Running the Example
To create the computational Project, change your current working directory (in Python) to the directory that contains the example material for this example.
After having navigated to the correct directory, create the computational Project using commands shown below:
from alltoall import *
result = run_alltoall()When the command is executed, the code will create a Project consisting of four (4) Jobs. Each Job will transfer a simple string to all other Jobs in the Project.
6.4. Executing a Function by Using CloudOp
This example is intended to illustrate how to execute a custom function by using the cloudop-method.
The material used in this example is located in the following folder in the Techila SDK:
-
techila\examples\python\Interconnect\4_cloudop
Please note that before you can successfully run this example, your Techila environment needs to be configured to support Techila interconnect Projects. Please ask your local Techila Administrator for more information.
The cloudop-function executes the given operation across all the Jobs and returns the result to all Jobs, or the target job:
ti = TechilaInterconnect()
result=ti.cloudop(<op>, <data>, <target>)The effect of the input arguments is explained below.
The <op> notation should be replaced with the function you wish to execute across all Jobs. For example the following syntax could be used to execute the Python max function.
result=ti.cloudop(max, <data>, <target>)It is also possible to execute custom, user defined functions with cloudop. For example, if you have developed a custom function called summation, then you could execute this with cloudop with the following syntax.
result=ti.cloudop(summation, <data>, <target>)The <data> notation should be replaced with the input data you wish to pass to the function defined in <op> as an input argument.
The <target> is an optional argument, which can be used to define how the final result of the operation will be returned. When the <target> argument is omitted or set to zero, cloudop will return the final result in all Jobs.
The <target> argument can also be used to transfer the final result to a specific Job. For example, if the value of the <target> argument is set to one (1), the result of the <op> will only be returned in Job 1. In this case, the cloudop function will return the value None in all other Jobs.
Functions executed with cloudop will need to meet following requirements:
-
The function must accept two input arguments
-
The function must return one output value. The format of this output value must be such that it can be given as an input argument to the custom function. This is because the operations will be executed using a binary tree structure, which means that the output of the custom function will be also used as input for the function when function is called later in the tree structure.
The example code snippet below shows custom function called multiply, which meets the above requirements.
def multiply(a, b):
return (a*b)Example 1: In the example code snippet below, the min function is used to find the minimum value of local variables (variable x). The minimum value will then be returned in Job 1 and store in variable xmin. All other Jobs will return the value None.
def findmin(input,idx,target):
from peachclient import TechilaInterconnect
ti = TechilaInterconnect()
x = input[idx]
xmin = ti.cloudop(min, x, target)
return(xmin)
def run():
import techila
input = [10, 5, 20]
jobs = len(input)
target = 1
xminlist = techila.peach(funcname = findmin,
params = [input,'<vecidx>',target],
jobs = jobs)
return(xminlist)The operations that take place on the Workers when the above code snippet is executed are illustrated in the figure below.
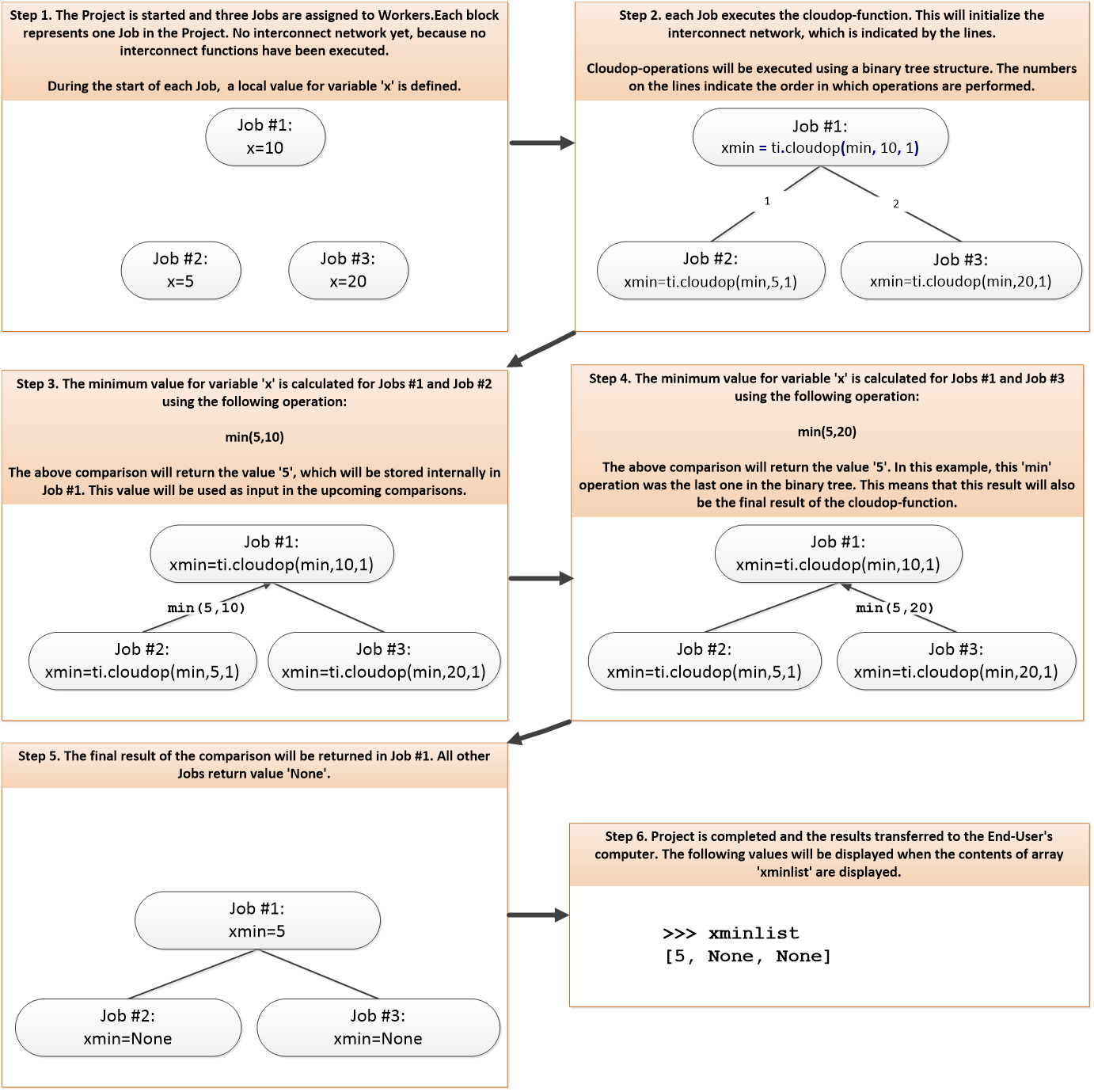
Example 2: In the example code snippet below, the min function is used to find the global minimum value of local workspace variables (variable x). The minimum value will then be broadcasted to all Jobs and stored in the xmin variable.
def findmin(input,idx):
from peachclient import TechilaInterconnect
ti = TechilaInterconnect()
x = input[idx]
xmin = ti.cloudop(min, x)
return(xmin)
def run():
import techila
input = [10, 5, 20]
jobs = len(input)
xminlist = techila.peach(funcname = findmin,
params = [input,'<vecidx>'],
jobs = jobs)
return(xminlist)The operations that take place on the Workers when the above code snippet is executed are illustrated in the figure below.
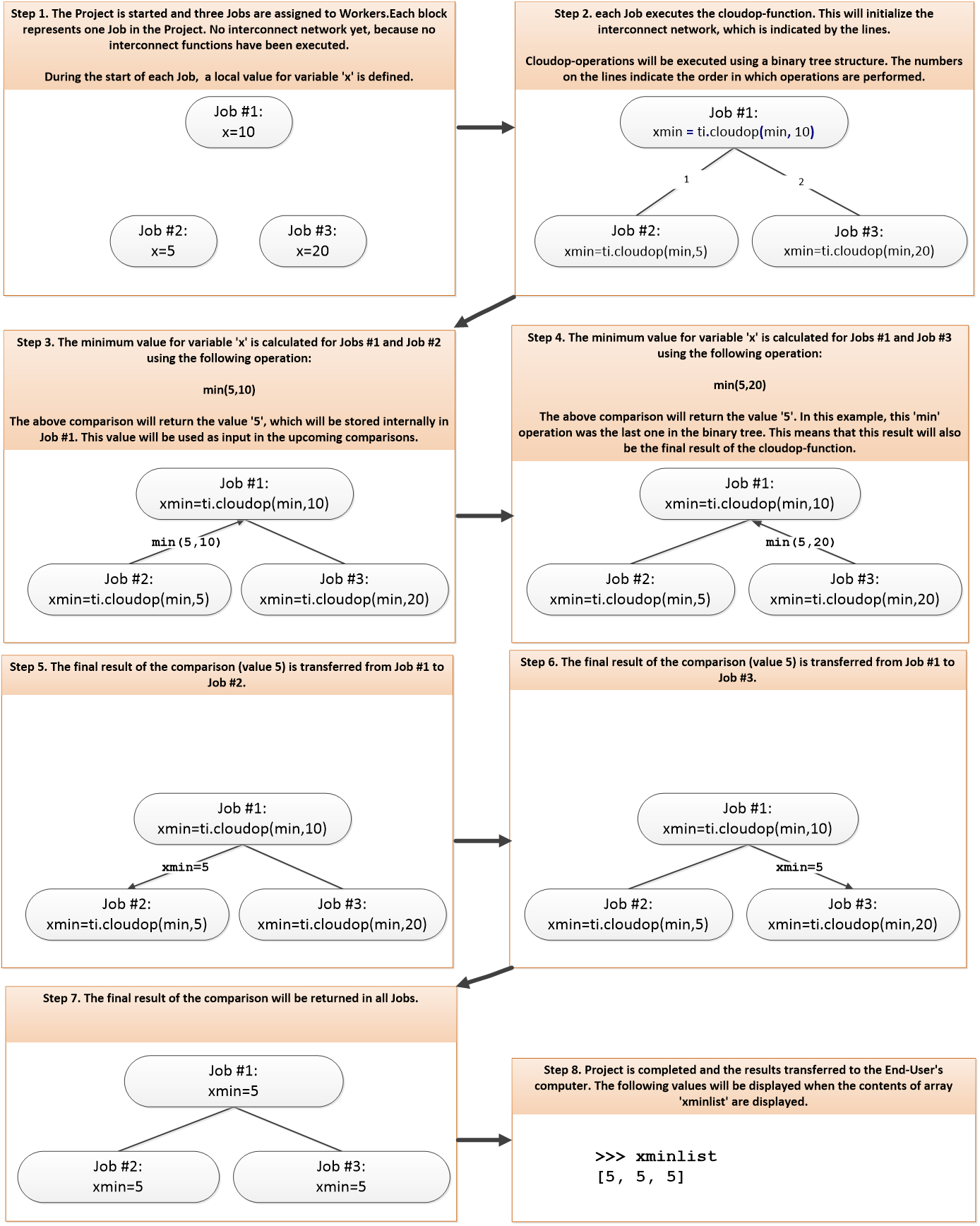
Summing Values with Cloudsum
The cloudsum function can be used to sum the defined variables. The operating principle of this function is similar to cloudop, with the exception that the cloudsum function can only be used to perform summation. The general syntax of the function is shown below.
ti = TechilaInterconnect()
result = ti.cloudsum(<data>,<target>)The <data> notation defines the input data that will be summed together.
The <target> can be used to define how the final result of the operation will be returned. When the <target> argument is omitted or set to zero, cloudsum will return the final result in all Jobs.
The <target> argument can also be used to transfer the final result to a specific Job. For example, if the value of the <target> argument is set to one (1), the summation result will only be returned in Job 1. In this case, the cloudsum function will return the value None in all other Jobs.
Example:
The code snippet below could be used to create a Project with three Jobs. Each Job executes the cloudsum to sum the values stored in the data variable. The summation result would be returned in all Jobs and would be stored in the variable sumval.
def cloudsum_dist(idx):
from peachclient import TechilaInterconnect
import random
ti = TechilaInterconnect()
random.seed(idx)
data = random.random()
sumval = ti.cloudsum(data)
return(ti.myjobid,sumval)
def run_cloudsum():
import techila
jobs = 3
results = techila.peach(funcname = cloudsum_dist,
params = ['<vecidx>'],
jobs = jobs)
for res in results:
jobid = str(res[0])
result = str(res[1])
print('Result from Job #' + jobid + ': ' + result)
return(results)6.4.1. Example Code Walkthrough
The source code of the example discussed in this Chapter is shown below.
-
techila\examples\python\Interconnect\4_cloudop\cloudop.py
# Example documentation: http://www.techilatechnologies.com/help/python_interconnect_4_cloudop
# This Python script contains the Local Control Code and Worker Code, which will be
# used to perform the computations in the Techila environment.
#
# Usage:
# result = run_cloudop()
# Copyright Techila Technologies Ltd.
def cloudop_dist(idx):
"""
This function contains the Worker Code and will be executed on Techila Workers.
Each Job will transfer a simple string to all other Jobs in the Project using
the Techila interconnect functions.
"""
# Import the Techila interconnect functions from the peachclient.py file
from peachclient import TechilaInterconnect
# Import the random package so we can generate random numbers
import random
# Define a simple function for multiplying values. This function will be executed
# across all Jobs by using the 'cloudop' method.
def multiply(a,b):
return(a*b)
# Create a TechilaInterconnect object, which contains the interconnect methods.
ti = TechilaInterconnect()
# Set the random number generator seed
random.seed(idx)
# Generate a random number
data = random.random()
# Execute the 'multiply' function across all Jobs with input 'data'. Final
# multiplication result will be stored in 'mulval' in all Jobs.
mulval = ti.cloudop(multiply, data)
# Wait until all Jobs have reached this point before continuing
ti.wait_for_others()
return(ti.myjobid,mulval)
def run_cloudop():
"""
This function contains the Local Control Code, which will be executed on the
End-User's computer. This function will create a computational Project, where
simple message strings will be transferred between all Jobs in the Project.
"""
import techila
# Set the number of Jobs to three.
jobs = 3
results = techila.peach(funcname = cloudop_dist, # Execute this function on Workers
params = ['<vecidx>'], # Define one input argument for the function.
jobs = jobs, # # Define number of Jobs in the Project.
#project_parameters = {'techila_worker_group' : 'IC Group 1'} # Uncomment to enable. Limit Project to Worker Group 'IC Group 1'.
)
# Print the results.
for res in results:
jobid = str(res[0])
result = str(res[1])
print('Result from Job #' + jobid + ': ' + result)
return(results)The run_cloudop function contains the code for creating the Project and displaying the results after the Project has been completed.
The peach-function used in this example will create a Project with three Jobs. Each Job will execute the cloudop_dist function with one input argument '<vecidx>'. The value of the '<vecidx>' notation will be different in each Job: 1 in Job 1, 2 in Job 2 and 3 in Job 3.
Each Job will execute a function called multiply using the cloudop method across all Jobs. This function takes two input arguments, multiplies them and returns the multiplication result. This means that the multiply function meets the requirements for functions that can be executed with cloudop.
In this example, the multiply function will multiply the random numbers generated in each Job. As the <target> argument is not defined in the cloudop call, the final result of the multiplication will be returned in each Job and stored in the mulval variable.
6.4.2. Running the Example
To create the computational Project, change your current working directory (in Python) to the directory that contains the example material for this example.
After having navigated to the correct directory, create the computational Project using commands shown below:
from cloudop import *
result = run_cloudop()When the command is executed, the code will create a Project consisting of three (3) Jobs. During each Job, a random number is generated. These random numbers will then be multiplied by using the cloudop function.
7. Cloud Control
The Techila cloud control feature allows controlling Techila Worker instances in various clouds.
This Chapter contains walkthrough of a simple example, which illustrates how to use the Techila cloud control functions. The example is the same as the first example in the peach tutorial with the cloud control functions added.
The example material discussed in this Chapter, including python source code files can be found under the following folder in the Techila SDK:
-
techila\examples\python\Features\cloud_control
7.1. Distributed Program
All arithmetic operations in the locally executable function are performed in the for-loop. There are no recursive data dependencies between iterations, meaning that the all the iterations can be performed simultaneously. The iterations can be performed simultaneously by placing the arithmetic operations to a separate file (distribution_dist.py), which can be then transferred and executed on Workers.
The file containing the Local Control Code (run_cloudcontrol.py) will be used to start Techila Worker cloud instances, set the idle shutdown time for the instances, create the computational Project and terminate the instances in the end. The Worker Code (distribution_dist.py) will be transferred to the Workers, where it will be automatically imported using command:
from distribution_dist import *This import process will take place at the preliminary stage of Job. After the functions have been imported, the function distribution_dist will be executed. The result returned by the function will be returned from the Job.
7.2. Local Control Code
The Local Control Code used to control the cloud Worker instances and create the computational Project is shown below.
# Example documentation: https://docs.techilatechnologies.com/help/techila-distributed-computing-engine/python-techila-distributed-computing-engine.html#_cloud_control
# Copyright Techila Technologies Ltd.
# This function contains the Local Control Code, which will
# control cloud instances and create the computational Project.
#
# Usage:
# execfile('run_cloudcontrol.py')
# result = run_cloudcontrol(jobcount)
#
# jobcount: number of Jobs in the Project
#
# Example:
# result = run_cloudcontrol(5)
def run_cloudcontrol(jobcount):
# Import the techila package
import techila
# Initialize connection to the Techila Server
techila.init()
# Start 1 worker instance with 4 cores (default instance type)
techila.deploy_workers(1)
# To specify instance type and start 4 instances, use command:
# techila.deploy_workers(4, '<machinetype>');
# where available values for <machinetype> depend on the cloud. The default instance types are
# Google: n1-standard-4
# AWS: c5.large
# Azure: Standard_D2s_v3
# Set worker instances idle shutdown delay to 1 minute
techila.set_auto_delete_delay(1)
# Create the computational Project with the peach function.
result = techila.peach(funcname = 'distribution_dist', # Function that will be called on Workers
files = 'distribution_dist.py', # Python-file that will be sourced on Workers
jobs = jobcount, # Number of Jobs in the Project
)
# Shutdown instances
techila.shutdown_workers()
# Uninitialize the connection
techila.uninit()
# Display results after the Project has been completed. Each element
# will correspond to a result from a different Job.
print(result)
return(result)The code consists of one function called run_cloudcontrol. This function takes one input argument called jobcount (integer). This variable will be used during the peach-function call to define the value of the jobs parameter, which defines the number of Jobs in the Project.
Techila helper functions (including peach) are made available by importing the techila package.
Techila Server connection is initialized by calling init. After this, deploy_workers is used to start Techila Worker cloud instances. In this case, one Worker instance with the default configuration is started.
Additionally, idle shutdown delay is set by calling set_auto_delete_delay. This makes the cloud instance(s) to be automatically terminated when they have been idling (no computational projects are running) for the configured period. In this case, the delay is set to one minute.
The computational Project is created with a peach-function call. After the computational Project has been completed, the results will be stored in the result list. The number of list elements will be the same as the number of Jobs in the Project. Each list element will contain the result returned from one Job.
The parameters of the peach-function call are explained below.
funcname = 'distribution_dist'The funcname parameter shown above defines that the function distributed_dist will be executed in each Job. This function will be defined when the file distribution_dist.py is evaluated as explained below.
files = 'distribution_dist.py'The parameter shown above defines that code in file named distributed_dist.py should be imported using command from distribution_dist import *. This import process will make all variables and functions defined in the file accessible during the computational Job. In this example, the file contains the definition for the distribution_dist function.
jobs = jobcountThe jobs parameter shown above defines the number of Jobs in the Project. In this example, the number of Jobs will be based on the value of the jobcount variable. The number of Jobs in the Project could also be defined by using the peachvector parameter. For more information on how to define the peachvector, please see Using Input Parameters.
After the Project has been completed, the results stored in result will be printed. Each element in the array will contain the result for one Job in the Project.
To terminate the Techila Worker cloud instances, shutdown_workers is called. Without this, the instances would also be terminated automatically after the configured idle shutdown delay.
The internal state of Techila connection and related resources are cleaned by calling uninit.
The function will return the result variable as the output.
7.3. Worker Code
The Worker Code that will be executed on the Workers is in the file called distribution_dist.py. The content of the file is shown below.
# Copyright Techila Technologies Ltd.
# This function contains the function that will be executed during
# computational Jobs. Each Job will perfom the same computational
# operations: calculating 1 + 1.
def distribution_dist():
# Store the sum of 1 + 1 to variable 'result'
result = 1 + 1
# Return the value of the 'result' variable. This value will be
# returned from each Job and the values will be stored in the list
# returned by the peach-function.
return(result)8. Appendix
This appendix contains miscellaneous code samples on how to implement various other features not featured in the python examples inluded in the Techila SDK.
8.1. Libraryfiles
By default, files transferred using the databundles parameter will be copied to Job-specific temporary working directories. In situations where the datafiles are very large, or you want to access files from a single location, you can prevent the copying by using the libraryfiles parameter. You can then access the files from a shared directory that is accessible by all Jobs.
The location of the files on the Techila Worker can be retrieved by using the bundle_parameters parameter, which can be used to create an environment variable that points to the file location.
import techila
def fun():
# This function will be executed in the Job on Techila Workers.
import os
print(os.getenv("datadir")) # This prints the directory path where the file is located on the Techila Worker.
# File loading and processing would be done here.
return(0)
# The 'libraryfiles' parameter is used to store the file in a location that can
# be accessed by all Jobs running on the Techila Worker. Will not be copied to
# temporary working directories on the Techila Worker.
databundles = [ # Define a databundle
{ # Data Bundle #1
'datadir' : '.', # The directory from where files will be read from.
'datafiles' : [ # Files for Data Bundle #1.
'file_on_your_computer.data',
],
'libraryfiles': True,
}]
# The 'bundle_parameters' is used to create 'datadir' environment variable that
# contains the path where the file is located on Techila Workers.
res = techila.peach(funcname=fun,
databundles=databundles,
bundle_parameters={'Environment': 'datadir;value=%L(peach_datafiles_0)'},
jobs=1)