1. R - Value-at-Risk Calculation
This example illustrates how to use Techila Distributed Computing Engine to speed up Value-at-Risk computations implemented with R.
The information on this page is intended to supplement the information in the original paper discussing this application. You can download the paper using the link shown below:
1.1. Introduction
One of the most common risk measures in the finance industry is Value-at-Risk (VaR). Value-at-Risk measures the amount of potential loss that could happen in a portfolio of investments over a given time period with a certain confidence interval. It is possible to calculate VaR in many different ways, each with their own pros and cons. Monte Carlo simulation is a popular method and is used in this example.
In the simplified VaR model used in the example, the value of a portfolio of financial instruments is simulated under a set of economic scenarios. The set of financial instruments in this example is limited to a set of fixed coupon bonds and equity options. The scenarios can be analyzed independently, meaning that the computations can be sped up significantly by analyzing the scenarios simultaneously on a large number of Techila Worker nodes.
This example is available for download at the following link:
The contents of the zip file is shown below for reference:
1.2. Data Locations & Management
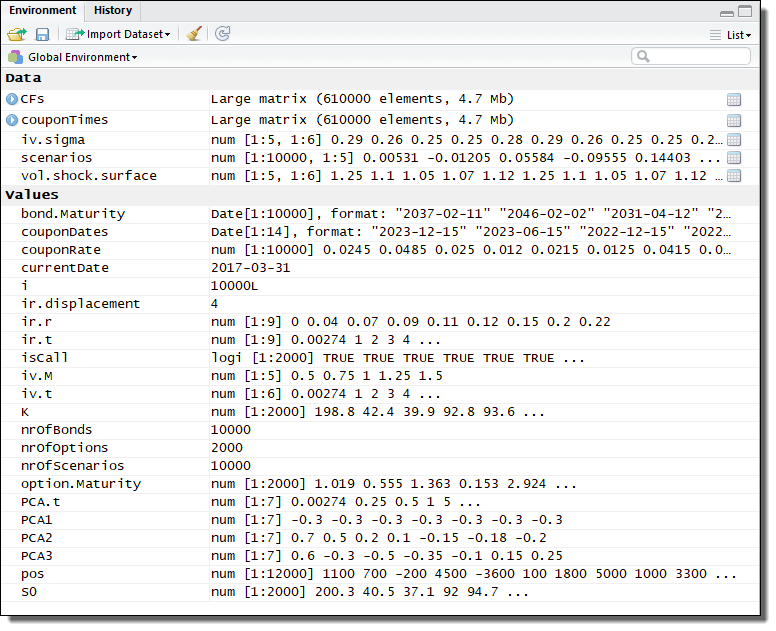
This example uses a set financial instruments, which are generated when the parameters.r file is sourced locally. This file is included in the zip-file, as can be seen from the previous screenshot.
When the parameters.r file is sourced, variables will be defined in the local R workspace. The data stored in these variables will be used when analyzing the scenarios. When processing the scenarios locally, the values of variables needed in the computations will be read from the local workspace, as in any other standard R application. In the distributed version of this application, necessary variables will be automatically transferred to Techila Workers participating in the computations.
Variables created by the parameters.r file are shown in the screenshot below for reference:
1.3. Sequential Local Processing
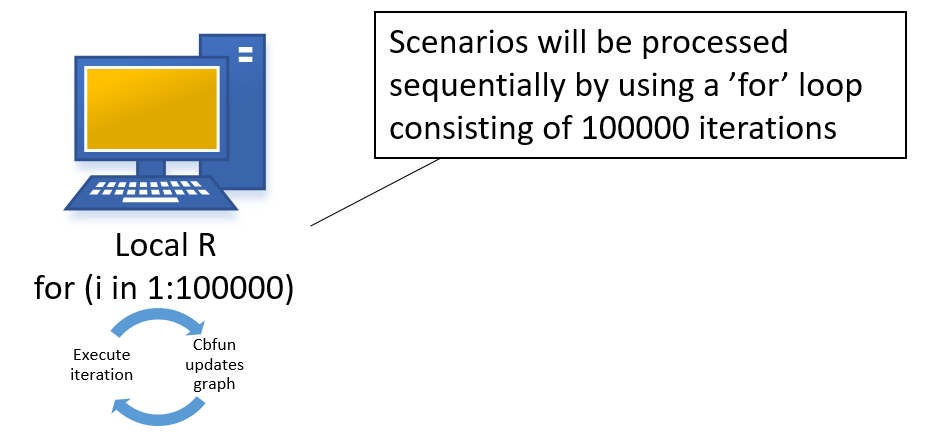
The computations could be executed locally by using a for loop structure shown below. Please note that the code package does not include a locally executable version, but the cloudfor version can be easily modified into a local for version as shown in the code snippet below.
portfolioValue <- rep(0, nrOfScenarios)
for(i in 1:nrOfScenarios) {
# Apply scenario on the interest rate curve
PCAshock <- scenarios[i, 1] * PCA1 + scenarios[i, 2] * PCA2 + scenarios[i, 3] * PCA3
rateShock <- exp(interp1(PCA.t, PCAshock, ir.t, method = "spline"))
shockedRate <- ((ir.r + ir.displacement) * rateShock) - ir.displacement
# Option valuation under the different scenarios
rate <- interp1(ir.t,
shockedRate,
option.Maturity,
method = "linear")
vol <- interp2(iv.t,
iv.M,
scenarios[i, 5] * vol.shock.surface * iv.sigma,
option.Maturity,
pmax(pmin(S0 * scenarios[i, 4] / K, max(iv.M)), min(iv.M)))
p_options <- bs_function(S0 * scenarios[i, 4],
K,
option.Maturity,
rate,
vol,
isCall)
# Bond valuation under the different scenarios
rate <- matrix(interp1(ir.t, shockedRate, couponTimes, method = "linear"), dim(couponTimes)[1], dim(couponTimes)[2])
p_bonds <- apply(CFs * exp(-couponTimes * rate / 100), 1, sum)
# Return the result
portfolioValue[i] <- pos %*% c(p_options, p_bonds)
# Update graph if necessary
cbfun(portfolioValue[i])
}Each iteration stores the computational result in the portfolioValue. Each iteration is independent, meaning there are no recursive dependencies. The results are visualized by performing a cbfun call, which updates the figure with new scenario data when a sufficient amount of new data points are available.
1.4. Distributed Processing
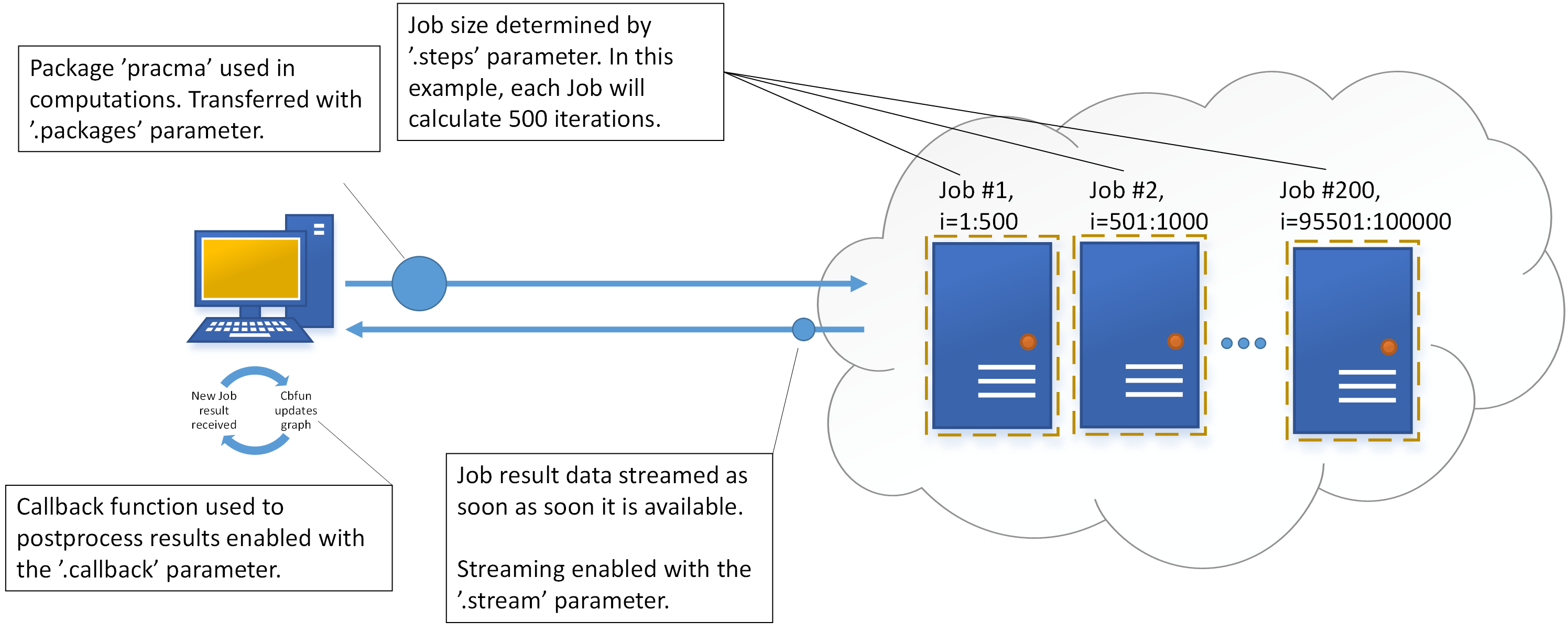
The code below shows the cloudfor version of the code, which will perform the computations in Techila Distributed Computing Engine. The syntax shown below will essentially push the code block immediately following the %t% notation to Techila Distributed Computing Engine where it will be executed on the Techila Workers.
All cloudfor parameters that start with . are optional control parameter used to fine tune the behaviour of the computations. For more general information about the cloudfor helper function, please see Techila Distributed Computing Engine with R.
The effect of the control parameters is illustrated in the image below. More information about the used control parameters can also be found in the source code comments.
portfolioValue <- cloudfor(i = 1:nrOfScenarios,
.steps = 500,
.stream = TRUE,
.callback = "cbfun",
.packages=list("pracma")
) %t% {
# Apply scenario on the interest rate curve
PCAshock <- scenarios[i, 1] * PCA1 + scenarios[i, 2] * PCA2 + scenarios[i, 3] * PCA3
rateShock <- exp(interp1(PCA.t, PCAshock, ir.t, method = "spline"))
shockedRate <- ((ir.r + ir.displacement) * rateShock) - ir.displacement
# Option valuation under the different scenarios
rate <- interp1(ir.t,
shockedRate,
option.Maturity,
method = "linear")
vol <- interp2(iv.t,
iv.M,
scenarios[i, 5] * vol.shock.surface * iv.sigma,
option.Maturity,
pmax(pmin(S0 * scenarios[i, 4] / K, max(iv.M)), min(iv.M)))
p_options <- bs_function(S0 * scenarios[i, 4],
K,
option.Maturity,
rate,
vol,
isCall)
# Bond valuation under the different scenarios
rate <- matrix(interp1(ir.t, shockedRate, couponTimes, method = "linear"), dim(couponTimes)[1], dim(couponTimes)[2])
p_bonds <- apply(CFs * exp(-couponTimes * rate / 100), 1, sum)
# Return the result
portfolioValue <- pos %*% c(p_options, p_bonds)
}1.5. Result Postprocessing
The result data post processing consists of plotting a histogram and calculating the quantiles. The figure containing the post processed data is shown below for reference.
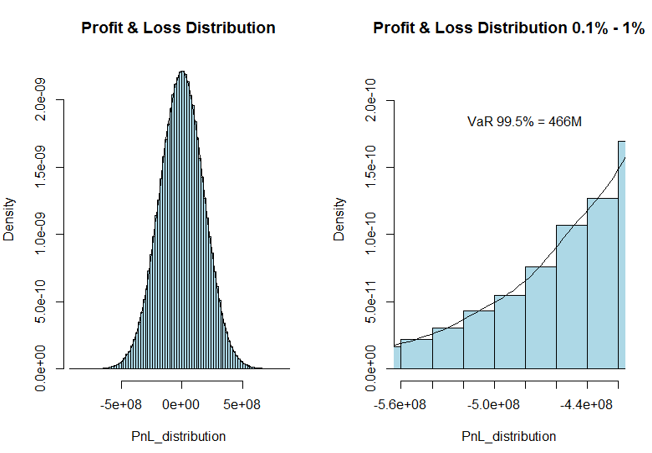
When using cloudfor, any result variables received from the Techila Workers will be automatically imported to the R workspace on the end-users computer. This means that after completing the cloudfor loop, all result data will be available in an identical format (same sizes, same data types) as in the local version. This in turn means that the code used to for post processing will be identical in both the local and distributed versions of the applications.
PnL_distribution <- sort(portfolioValue - basePortfolioValue)
# Computation done, plot final histogram and calculate quantiles
par(mfrow = c(1, 2))
# Plot entire histogram
hist(PnL_distribution,
breaks = 100,
col = "lightblue",
prob = TRUE,
main = "Profit & Loss Distribution",
freq = FALSE)
lines(density(PnL_distribution))
# Plot histogram tail
hist(PnL_distribution,
breaks = 100,
xlim = sort(PnL_distribution)[c(0.001 * length(PnL_distribution), 0.01 * length(PnL_distribution))],
col = "lightblue",
prob = TRUE,
main = "Profit and Loss Distribution 0.1-1% percentile",
freq = FALSE,
ylim = c(0, max(density(PnL_distribution)$y) / 10))
lines(density(PnL_distribution))
# Display additional info
text(sort(PnL_distribution)[0.004 * length(PnL_distribution)],
max(density(PnL_distribution)$y) / 12,
paste("VaR 99.5% = ",
as.character(round(-quantile(PnL_distribution, 0.005) / 1000000)),
"M",
sep = ""))
print(quantile(PnL_distribution, c(0.001, 0.005, 0.01, 0.1, 0.25, 0.5, 0.75, 0.9, 0.99, 0.995, 0.999)))